Składnia
df [ ( cond_1 ) & ( war_2 ) ]Przykład 01
Wykonujemy te kody w aplikacji „Spyder” i użyjemy operatora „AND” w naszych warunkach w „pandach” tutaj. Ponieważ robimy kody pand, najpierw musimy zaimportować „pandy jako pd” i uzyskać jego metodę, umieszczając po prostu „pd” w naszym kodzie. Następnie generujemy słownik o nazwie „Cond”, a dane, które tu wstawiamy to „A1”, „A2” i „A3” to nazwy kolumn, a dodajemy „1, 2 i 3” w „ A1”, w „A2” jest „2, 6 i 4”, a ostatni „A3” zawiera „3, 4 i 5”.
Następnie przechodzimy do tworzenia DataFrame tego słownika, wykorzystując tutaj „pd.DataFrame”. To zwróci DataFrame powyższych danych słownikowych. Renderujemy go również, podając tutaj „print ()”, a następnie stosujemy pewne warunki, a także używamy operatora „&” w tym warunku. Pierwszym warunkiem jest to, że „A1 >= 1”, a następnie umieszczamy operator „&” i stawiamy kolejny warunek, którym jest „A2 < 5”. Kiedy to wykonamy, zwróci wynik, jeśli „A1 >=1”, a także „A2 <5”. Jeśli oba warunki są tutaj spełnione, wyświetli wynik, a jeśli którykolwiek z nich nie jest tutaj spełniony, nie wyświetli żadnych danych.
Sprawdza obie kolumny „A1” i „A2” ramki DataFrame, a następnie zwraca wynik. Wynik jest wyświetlany na ekranie, ponieważ używamy instrukcji „print()”.
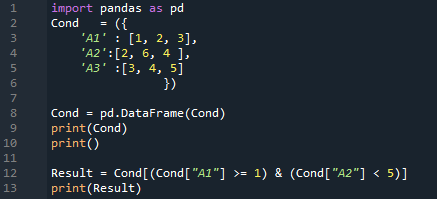
Wynik jest tutaj. Wyświetla wszystkie dane, które umieściliśmy w DataFrame, a następnie sprawdza oba warunki. Zwraca te wiersze, w których „A1 >=1”, a także „A2 <5”. W tym wyniku otrzymujemy dwa wiersze, ponieważ oba warunki są spełnione w dwóch wierszach.
Przykład 02
W tym przykładzie bezpośrednio tworzymy DataFrame po zaimportowaniu „pandy jako pd”. W tym miejscu tworzona jest ramka DataFrame „Team” z danymi zawierającymi cztery kolumny. Pierwsza kolumna to kolumna „zespoły”, w której umieszczamy „A, A, B, B, B, B, C, C”. Następnie kolumna obok „drużyny” to „score”, w której wstawiamy „25, 12, 15, 14, 19, 23, 25 i 29”. Następnie kolumna, którą mamy, to „Out”, a także dodajemy w niej dane jako „5, 7, 7, 9, 12, 9, 9 i 4”. Nasza ostatnia kolumna to kolumna „odbicia”, która zawiera również pewne dane liczbowe, czyli „11, 8, 10, 6, 6, 5, 9 i 12”.
DataFrame jest tutaj ukończona i teraz musimy wydrukować tę DataFrame, więc w tym celu umieszczamy tutaj „print()”. Chcemy uzyskać określone dane z tego DataFrame, więc ustalamy tutaj pewne warunki. Mamy tutaj dwa warunki i między tymi warunkami dodajemy operator „AND”, aby zwrócił tylko te warunki, które spełnią oba warunki. Pierwszym dodanym przez nas warunkiem jest „score > 20”, a następnie wstawiamy operator „&” oraz drugi warunek, którym jest „Out == 9”.
Tak więc filtruje te dane, w których wynik zespołu jest mniejszy niż 20, a także ich outy wynoszą 9. Filtruje te i ignoruje pozostałe, co nie spełnia obu warunków ani żadnego z nich. Wyświetlamy również te dane, które spełniają oba warunki, dlatego zastosowaliśmy metodę „print()”.
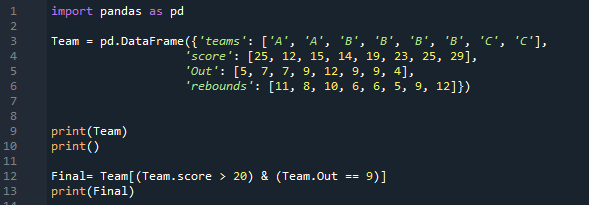
Tylko dwa wiersze spełniają oba warunki, które zastosowaliśmy do tego DataFrame. Filtruje tylko te wiersze, w których wynik jest większy niż 20, a także ich outy to 9 i wyświetla je tutaj.
Przykład 03
W naszych powyższych kodach po prostu wstawiamy dane liczbowe do naszego DataFrame. Teraz umieszczamy w tym kodzie kilka danych ciągu. Po zaimportowaniu „pand jako pd” przechodzimy do budowy DataFrame „Member”. Zawiera cztery unikalne kolumny. Nazwa pierwszej kolumny to „Imię” i wstawiamy imiona członków, którymi są „Sojusznicy, Bills, Charles, David, Ethen, George i Henry”. Następna kolumna nosi tutaj nazwę „Lokalizacja” i zawiera „Ameryka. Kanada, Europa, Kanada, Niemcy, Dubaj i Kanada”. Kolumna „Kod” zawiera „W, W, W, E, E, E i E”. Dodajemy tutaj również „punkty” członków jako „11, 6, 10, 8, 6, 5 i 12”. Renderujemy DataFrame „Member” z wykorzystaniem metody „print()”. W tym DataFrame określiliśmy pewne warunki.
Tutaj mamy dwa warunki, a dodając między nimi operator „AND”, zwróci tylko te warunki, które spełniają oba warunki. Tutaj pierwszym warunkiem, który wprowadziliśmy, jest „Lokalizacja == Kanada”, po którym następuje operator „&”, a drugim warunkiem „punkty <= 9”. Pobiera te dane z DataFrame, w których oba warunki są spełnione, a następnie umieściliśmy „print()”, które wyświetla te dane, w których oba warunki są spełnione.
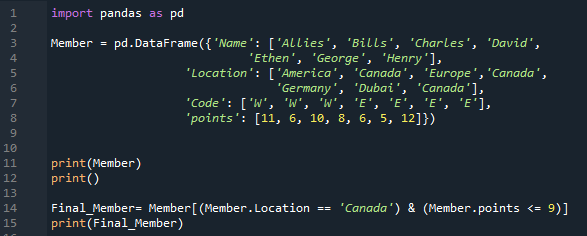
Poniżej możesz zauważyć, że dwa wiersze są wyodrębniane z DataFrame i wyświetlane. W obu rzędach lokalizacja to „Kanada”, a liczba punktów wynosi mniej niż 9.
Przykład 04
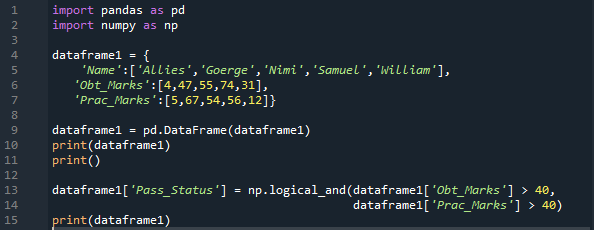
Importujemy tutaj zarówno „pandy”, jak i „numpy”, odpowiednio jako „pd” i „np”. Otrzymujemy metody „pandy” umieszczając metody „pd” i „numpy” umieszczając „np” tam, gdzie jest to potrzebne. Wtedy słownik, który tutaj stworzyliśmy, zawiera trzy kolumny. W kolumnie „Imię” wstawiamy „Sojusznicy, George, Nimi, Samuel i William”. Następnie mamy kolumnę „Obt_Marks”, w której znajdują się uzyskane oceny uczniów, a te oceny to „4, 47, 55, 74 i 31”.
Tworzymy tutaj również kolumnę dla „Prac_Marks”, w której znajdują się praktyczne oceny ucznia. Znaki, które tutaj dodajemy to „5, 67, 54, 56 i 12”. Tworzymy ramkę DataFrame tego słownika, a następnie ją drukujemy. Stosujemy tutaj „np.Logical_and”, co zwróci wynik w postaci „Prawda” lub „Fałsz”. Przechowujemy również wynik po sprawdzeniu obu warunków w nowej kolumnie, którą utworzyliśmy tutaj o nazwie „Pass_Status”.
Sprawdza, czy „Obt_Marks” jest większe niż „40”, a „Prac_Marks” jest większe niż „40”. Jeśli oba są prawdziwe, to w nowej kolumnie zostanie wyświetlone prawda; w przeciwnym razie oznacza fałsz.
Nowa kolumna jest dodawana z nazwą „Pass_Status”, a ta kolumna składa się tylko z „True” i „False”. Jest to prawdziwe, gdy uzyskane oceny, a także oceny praktyczne są większe niż 40 i fałszywe dla pozostałych wierszy.
Wniosek
Głównym celem tego samouczka jest wyjaśnienie pojęcia „i stanu” w „pandach”. Mówiliśmy o tym, jak pozyskać te wiersze, w których spełnione są oba warunki, lub uzyskujemy również prawdziwe dla tych, w których wszystkie warunki są spełnione, a fałszywe dla pozostałych. Przeanalizowaliśmy tutaj cztery przykłady. Wszystkie cztery przykłady, które stworzyliśmy w tym samouczku, przeszły przez ten proces. Wszystkie przykłady w tym samouczku zostały starannie przedstawione dla Twojej korzyści. Ten samouczek powinien pomóc ci w lepszym zrozumieniu tego pomysłu.