Pandy wypełniają wartości NaN
Jeśli kolumna w ramce danych zawiera wartości NaN lub None, możesz użyć funkcji „fillna()” lub „replace()”, aby wypełnić je zerem (0).
wypełnić()
Wartości NA/NaN są wypełniane podanym podejściem za pomocą funkcji „fillna()”. Można go wykorzystać, biorąc pod uwagę następującą składnię:
Jeśli chcesz wypełnić wartości NaN dla pojedynczej kolumny, składnia jest następująca:

Gdy wymagane jest wypełnienie wartości NaN dla całej ramki DataFrame, składnia jest następująca:

Zastępować()
Aby zastąpić pojedynczą kolumnę wartości NaN, podana składnia jest następująca:

Natomiast, aby zastąpić całe wartości NaN DataFrame, musimy użyć następującej składni:

W tym artykule omówimy teraz i nauczymy się praktycznej implementacji obu tych metod w celu wypełnienia wartości NaN w naszej Pandas DataFrame.
Przykład 1: Wypełnij wartości NaN za pomocą metody Pandy „Fillna()”
Ta ilustracja przedstawia zastosowanie funkcji Pandy „DataFrame.fillna()” do wypełnienia wartości NaN w danej DataFrame wartością 0. Brakujące wartości można wypełnić w jednej kolumnie lub w całej ramce DataFrame. Tutaj zobaczymy obie te techniki.
Aby wprowadzić te strategie w życie, musimy uzyskać odpowiednią platformę do realizacji programu. Postanowiliśmy więc użyć narzędzia „Spyder”. Rozpoczęliśmy nasz kod w Pythonie od zaimportowania zestawu narzędzi „pandy” do programu, ponieważ musimy użyć funkcji Pandy do skonstruowania DataFrame, a także uzupełnienia brakujących wartości w tej DataFrame. „pd” jest używany jako alias „pand” w całym programie.
Teraz mamy dostęp do funkcji Pandy. Najpierw używamy jego funkcji „pd.DataFrame()”, aby wygenerować naszą DataFrame. Wywołaliśmy tę metodę i zainicjowaliśmy ją z trzema kolumnami. Tytuły tych kolumn to „M1”, „M2” i „M3”. Wartości w kolumnie „M1” to „1”, „Brak”, „5”, „9” i „3”. Wpisy w „M2” to „Brak”, „3”, „8”, „4” i „6”. Podczas gdy „M3” przechowuje dane jako „1”, „2”, „3”, „5” i „Brak”. Potrzebujemy obiektu DataFrame, w którym możemy przechowywać tę DataFrame po wywołaniu metody „pd.DataFrame()”. Stworzyliśmy „brakujący” obiekt DataFrame i przypisaliśmy go przez wynik uzyskany z funkcji „pd.DataFrame()”. Następnie zastosowaliśmy metodę „print()” Pythona, aby wyświetlić DataFrame w konsoli Pythona.
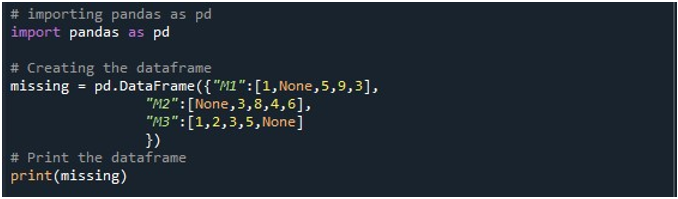
Po uruchomieniu tego fragmentu kodu na terminalu można wyświetlić ramkę DataFrame z trzema kolumnami. Tutaj możemy zaobserwować, że wszystkie trzy kolumny zawierają w sobie wartości null.
Stworzyliśmy ramkę DataFrame z kilkoma wartościami null, aby zastosować funkcję Pandy „fillna()” w celu uzupełnienia brakujących wartości 0. Dowiedzmy się, jak możemy to zrobić.
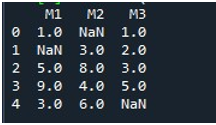
Po wyświetleniu DataFrame wywołaliśmy funkcję Pandy „fillna()”. Tutaj nauczymy się uzupełniać brakujące wartości w jednej kolumnie. Składnia tego jest już wspomniana na początku samouczka. Podaliśmy nazwę DataFrame i określiliśmy tytuł konkretnej kolumny za pomocą funkcji „.fillna()”. W nawiasach tej metody podaliśmy wartość, która zostanie umieszczona w pustych miejscach. Nazwa DataFrame jest „brakująca”, a kolumna, którą tutaj wybraliśmy, to „M2”. Wartość podana między nawiasami klamrowymi „fillna()” to „0”. Na koniec wywołaliśmy funkcję „print()”, aby wyświetlić zaktualizowaną ramkę DataFrame.

Tutaj widać, że kolumna „M2” DataFrame nie zawiera teraz żadnych brakujących wartości, ponieważ wartość NaN jest wypełniona 0.
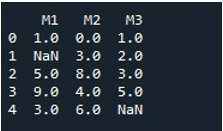
Aby wypełnić wartości NaN dla całej ramki DataFrame tą samą metodą, nazwaliśmy „fillna()”. To całkiem proste. Do nazwy DataFrame dodaliśmy funkcję „fillna()” i przypisaliśmy wartość funkcji „0” w nawiasach. Wreszcie funkcja „print()” pokazała nam wypełnioną ramkę DataFrame.

Daje nam to ramkę DataFrame bez wartości NaN, ponieważ wszystkie wartości są teraz uzupełniane zerem.
Przykład 2: Wypełnij wartości NaN za pomocą metody Pandy „Replace()”
W tej części artykułu przedstawiono inną metodę wypełniania wartości NaN w DataFrame. Użyjemy funkcji „replace()” Pandy, aby wypełnić wartości w pojedynczej kolumnie i w kompletnym DataFrame.
Zaczynamy pisać kod w narzędziu „Spyder”. Najpierw zaimportowaliśmy wymagane biblioteki. Tutaj załadowaliśmy bibliotekę Pandas, aby umożliwić programowi Python korzystanie z metod Pandas. Drugą biblioteką, którą załadowaliśmy, jest NumPy i alias na „np”. NumPy obsługuje brakujące dane za pomocą metody „replace()”.
Następnie wygenerowaliśmy DataFrame z trzema kolumnami – „śruba”, „gwóźdź” i „wiertło”. Wartości w każdej kolumnie podane są odpowiednio. Kolumna „śruba” ma wartości „112”, „234”, „Brak” i „650”. Kolumna „gwóźdź” ma „123”, „145”, „Brak” i „711”. Wreszcie kolumna 'wiertło' ma wartości '312', 'Brak', '500' i 'Brak'. DataFrame jest przechowywana w obiekcie DataFrame „narzędziowym” i wyświetlana za pomocą metody „print()”.
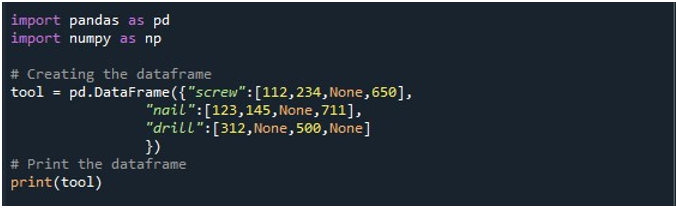
DataFrame z czterema wartościami NaN w rekordzie można zobaczyć na następującym obrazie wyjściowym:
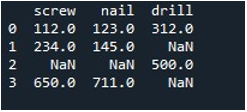
Teraz używamy metody Pandy „replace()”, aby wypełnić wartości null w pojedynczej kolumnie DataFrame. Dla zadania wywołaliśmy funkcję „replace()”. Nazwę DataFrame „narzędzie” i kolumnę „śruba” dostarczyliśmy za pomocą metody „.replace()”. Między jego nawiasami klamrowymi ustawiamy wartość „0” dla wpisów „np.nan” w DataFrame. Do wyświetlenia wyniku wykorzystywana jest metoda „print()”.

Otrzymana ramka DataFrame pokazuje nam pierwszą kolumnę z wpisami NaN zamienionymi na 0 w kolumnie „śruba”.
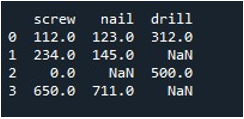
Teraz nauczymy się wypełniać wartości w całej DataFrame. Nazwaliśmy metodę „replace()” nazwą DataFrame i podaliśmy wartość, którą chcemy zastąpić wpisami np.nan. Na koniec wydrukowaliśmy zaktualizowaną ramkę DataFrame za pomocą funkcji „print()”.

To daje nam wynikową ramkę DataFrame bez brakujących rekordów.
Wniosek
Postępowanie z brakującymi wpisami w DataFrame jest podstawą i jest niezbędnym wymogiem zmniejszenia złożoności i wyzywającego postępowania z danymi w procesie analizy danych. Pandas daje nam kilka możliwości radzenia sobie z tym problemem. W tym przewodniku wprowadziliśmy dwie przydatne strategie. Wprowadzamy w życie obie techniki za pomocą narzędzia „Spyder”, aby wykonać przykładowe kody, aby było trochę zrozumiałe i łatwiejsze dla Ciebie. Zdobycie wiedzy na temat tych funkcji poprawi Twoje umiejętności Pandy.