
Praktyczne wykonanie tej funkcji zobaczymy w tym samouczku.
Przykład 1: Wykorzystanie metody Pandas Series.Reset_Index() do resetowania indeksu serii w celu zachowania początkowej listy indeksów jako kolumny
Na tej ilustracji zastosowano metodę „Series.reset_index()”, aby zresetować indeks serii Pand i zachować zmiany w kopii serii.
Pracę programu Python rozpoczęliśmy od znalezienia odpowiedniego narzędzia dla naszego systemu do wykonania skryptu. Narzędzie „Spyder” jest wybierane do wykonywania programów.
Inicjujemy skrypt, ładując najpierw niezbędne biblioteki. Ponieważ metoda „Series.reset_index()” jest wykorzystywana z zestawu narzędzi Pandas, musimy koniecznie załadować ją do naszego środowiska Pythona. Biblioteka Pandas jest importowana przez napisanie skryptu „importuj pandy jako pd”. Sekcja „as pd” w tym wierszu odnosi się do uczynienia „pd” aliasem biblioteki „Pandas”. Dlatego nie musimy używać „Pand”. Po prostu piszemy „pd”, aby uzyskać dostęp do dowolnej funkcji Pandy.
Pierwszą metodą, do której uzyskujemy dostęp z modułu Pandas za pomocą aliasu „pd”, jest metoda „pd.Series”. Ta metoda jest wbudowaną metodą Pandy do tworzenia serii z podaną tablicą wartości. Wywołujemy tę funkcję i określamy wartości, które są „34”, „21”, „18”, „45”, „76”, „82”, „22”, „40”, „91”, „101”, i „8”. Również nazwa kolumny jest definiowana za pomocą parametru „nazwa” jako „Dane”.
Następnie inicjujemy zmienną „new_index” i przypisujemy jej pewne wartości, ale o tej samej długości, której użyliśmy dla wartości w serii. Wartości zmiennej „new_index” to „A01”, „A02”, „A03”, „A04”, „A05”, „A06”, „A07”, „A08”, „A09”, „A10” i „A11”. Do indeksu używamy wartości przechowywanych w tej zmiennej. Aby ustawić kolumnę indeksu serii, wywołujemy właściwość „Series.index” i przypisujemy jej zmienną „new_index”. Wartości przechowywane w „new_index” są umieszczane jako indeks serii zamiast domyślnej listy indeksów, która zaczyna się od „0”. Na koniec, aby zobaczyć serię o określonym indeksie, wywołujemy funkcję „print()” i przekazujemy serię „Number” jako dane wejściowe, aby wydrukować jej zawartość.
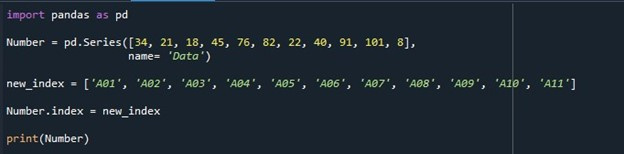
Wynikowa seria z określonymi indeksami, która zastąpiła domyślną listę indeksów, jest wyświetlana na terminalu.
Aby zresetować tę zdefiniowaną przez użytkownika listę indeksów do listy domyślnej, używamy metody Pandas „Series.reset_index()”.
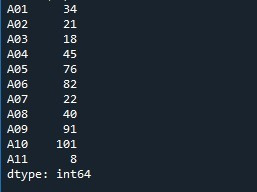
Wywołujemy metodę „Series.reset_index()”, aby zresetować listę indeksów. Nazwa serii jest podawana jako „Number” przy użyciu metody „reset_index()”. W ten sposób działa poprzez sprawdzenie serii i zresetowanie listy indeksów do ustawień domyślnych. Aby zapisać te modyfikacje, tworzymy zmienną „Wyjście”, która generuje kopię serii ze zmienioną listą indeksów. Używamy funkcji „print()”, aby wyświetlić zawartość „wyjściową”.

Na obrazie wyjściowym widzimy, że wyświetlany jest domyślny indeks sekwencyjny. Ponadto określona lista indeksów jest dodawana jako nowa kolumna serii z etykietą „indeks”.
Przykład 2: Wykorzystanie metody Pandas Series.Reset_Index() do zresetowania indeksu serii i porzucenia indeksu początkowego
Ta instancja demonstruje technikę resetowania indeksu serii Pand za pomocą metody „Series.reset_index()”. Dodatkowo odrzucamy wstępnie zdefiniowaną kolumnę indeksu za pomocą parametru „drop” funkcji „Series.reset_index()”.
Aby wykonać fragment kodu, najpierw importujemy bibliotekę Pandas jako „pd”. Następnie wykonujemy metodę z aktualnie załadowanego modułu Pandy, aby utworzyć serię Pand. Wykorzystywana jest funkcja „pd.Series()” i dostarczamy do niej tablicę wartości, aby wygenerować serię przy użyciu tych wartości. Wartości, które określiliśmy dla konstrukcji serii są typu string. Te wartości to „Nestle”, „Cadbury”, „Mars”, „Dove”, „Lindt”, „Godiva”, „Ghirardelli” i „Ferrero”. Używamy parametru „nazwa” do oznaczenia tej kolumny. Nazywamy ją „Marką”, ponieważ tworzymy serię, która zawiera nazwy marek czekoladowych. Długość serii wynosi 8. Tworzony jest obiekt serii „Czekoladki”, któremu przypisywany jest wynik wywołania metody Pandas „pd.Series()”.
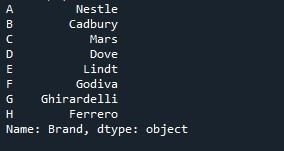
Ponadto zmienna „identyfikator” jest tworzona i inicjowana z tymi wartościami „A”, „B”, „C”, „D”, „E”, „F”, „G” i „H”. Długość wartości, które zawiera, jest taka sama jak długość wartości dla serii. Teraz zmieniamy domyślną listę indeksów serii i podajemy wartości zmiennej „identyfikator”, która ma być używana jako indeks. Aby ustawić indeks, wykonywana jest właściwość „Series.index”. Nazwa serii „Czekoladki” jest wymieniona z właściwością „.index”. Do właściwości index przypisujemy zmienną „identyfikator”. Właściwość „index” wyodrębnia wartości zachowane w zmiennej „identyfikator” i tworzy z nich listę indeksów serii. Metoda „print()” jest ostatecznie wywoływana do drukowania serii „Czekoladki”.
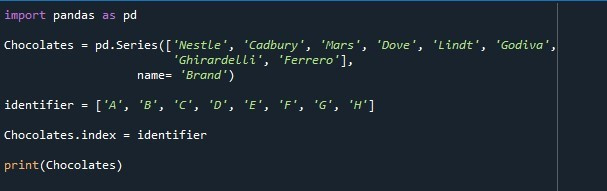
Seria pokazana na poniższym zrzucie pokazuje, że pomyślnie umieściliśmy określoną listę indeksów zamiast domyślnej listy indeksów.
Teraz, jeśli chcesz zresetować ustawienia indeksu, po prostu użyj metody Pandy „Series.reset_index()”. Tą metodą podajemy nazwę naszej serii. Po prostu resetuje ustawienia indeksu do wartości domyślnych dla tej konkretnej serii.
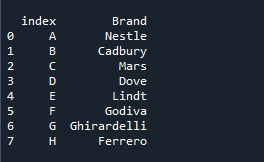
Wywołujemy metodę „Series.reset_index()” i podajemy nazwę serii jako „Czekoladki”. Aby zapisać serię z domyślną listą indeksów, tworzymy zmienną „ser”. Teraz musimy zobaczyć tę serię. W tym celu używana jest metoda „print()”. W nawiasach klamrowych przekazujemy zmienną „ser”, aby wyświetlała to, co zachowała ta zmienna.

Powstałe serie są wyświetlane z domyślną listą indeksów. Ale również początkowo określona lista indeksów jest obecna jako kolumna w serii z tytułem „indeks”. Metoda „reset_index()” umieszcza domyślną listę indeksów, ale nie usuwa określonej listy dla indeksu i zamiast tego zachowuje ją jako nową kolumnę.
Aby odrzucić wstępnie określoną listę indeksów, która jest teraz dołączona jako kolumna w serii, używamy parametru w metodzie „reset_index()”. Ten parametr to „spadek”. Jako dane wejściowe przyjmuje wartość logiczną. Domyślnie wartość parametru „drop” jest ustawiona na „False”, co oznacza, że nie usuwa on początkowej listy indeksów. Ponieważ chcemy wyeliminować początkową listę indeksów, musimy zmienić jej wartość na „Prawda”.
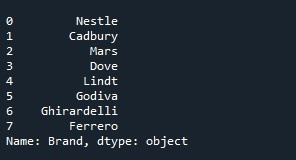
Po prostu przekazujemy atrybut „drop” z wartością „True” do funkcji „Series.reset_index()”.

Wyrenderowane dane wyjściowe przedstawiają serię, w której usunięto kolumnę „indeks” i są wyświetlane z domyślną listą indeksów. Otrzymany wynik jest przedstawiony w następującej migawce:
Wniosek
Zestawy danych, w których określono listę indeksów, mogą być używane zamiast domyślnej listy indeksów. Być może będziemy musieli zresetować go z powrotem do ustawień domyślnych. Z tego powodu Pandas udostępnia nam metodę „Series.reset_index()”. Ta metoda zmienia indeks na ustawienia domyślne. Podaliśmy dwie techniki wykorzystania tej metody. Na pierwszej ilustracji zachowaliśmy początkowo określoną listę indeksów w wynikowej serii jako kolumnę po dołączeniu domyślnej listy indeksów. Druga technika zademonstrowała, jak usunąć określoną listę z serii za pomocą parametru „drop”.