UTF-8 oznacza „ Format transformacji Unicode 8-bitowy ” i odpowiada doskonałemu formatowi kodowania, który zapewnia prawidłowe wyświetlanie znaków na wszystkich urządzeniach, niezależnie od używanego języka/skryptu. Format ten jest również pomocny w przypadku stron internetowych i służy do przechowywania, przetwarzania i przesyłania danych tekstowych w Internecie.
Ten samouczek obejmuje poniższe obszary treści:
- Co to jest kodowanie UTF-8?
- Jak działa kodowanie UTF-8?
- Jak obliczane są wartości punktów kodowych?
- Jak kodować/dekodować UTF-8 w JavaScript?
- Zakoduj/dekoduj UTF-8 w JavaScript przy użyciu metod „encodeURIComponent()” i „decodeURIComponent()”.
- Koduj/dekoduj UTF-8 w JavaScript przy użyciu metod „encodeURI()” i „decodeURI()”.
- Koduj/dekoduj UTF-8 w JavaScript przy użyciu wyrażeń regularnych.
- Wniosek
Co to jest kodowanie UTF-8?
„ Kodowanie UTF-8 ” to procedura przekształcania sekwencji znaków Unicode na zakodowany ciąg składający się z 8-bitowych bajtów. To kodowanie może reprezentować duży zakres znaków w porównaniu do innych kodowań znaków.
Jak działa kodowanie UTF-8?
Reprezentując znaki w UTF-8, każdy indywidualny punkt kodowy jest reprezentowany przez jeden lub więcej bajtów. Poniżej znajduje się podział punktów kodowych w zakresie ASCII:
- Pojedynczy bajt reprezentuje punkty kodowe w zakresie ASCII (0-127).
- Dwa bajty reprezentują punkty kodowe w zakresie ASCII (128-2047).
- Trzy bajty reprezentują punkty kodowe w zakresie ASCII (2048-65535).
- Cztery bajty reprezentują punkty kodowe w zakresie ASCII (65536-1114111).
Jest tak, że pierwszy bajt „ UTF-8 „sekwencja” jest określana jako „ bajt lidera ”, która podaje informację o liczbie bajtów w sekwencji i wartości punktu kodowego znaku.
„Bajt wiodący” dla sekwencji jedno-, dwu-, trzy- i czterobajtowej mieści się odpowiednio w zakresie (0-127), (194-233), (224-239) i (240-247).
Pozostałe bajty w sekwencji nazywane są „ końcowy ” bajty. Wszystkie bajty sekwencji dwu-, trzy- i czterobajtowej mieszczą się w zakresie (128-191). Dzieje się tak, że wartość punktu kodowego znaku można obliczyć, analizując bajty początkowe i końcowe.
Jak obliczane są wartości punktów kodowych?
Wartości punktów kodowych dla różnych sekwencji bajtów są obliczane w następujący sposób:
- Sekwencja dwubajtowa: Punkt kodowy jest równoważny „((lb – 194) * 64) + (tb – 128)”.
- Sekwencja trzybajtowa : Punkt kodowy jest równoważny „((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)”.
- Sekwencja czterobajtowa : Punkt kodowy jest równoważny „((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)”.
Jak kodować/dekodować UTF-8 w JavaScript?
Kodowanie i dekodowanie UTF-8 w JavaScript można przeprowadzić za pomocą poniższych podejść:
- „ enodeURIComponent() ' I ' dekodujURIComponent() Metody.
- „ kodujURI() ' I ' dekodowaćURI() Metody.
- Wyrażenia regularne.
Podejście 1: Kodowanie/dekodowanie UTF-8 w JavaScript przy użyciu metod „encodeURIComponent()” i „decodeURIComponent()”
„ zakodujURIComponent() ” koduje komponent URI. Może także kodować znaki specjalne, takie jak @, &, :, +, $, # itp. „ dekodujURIComponent() ”, jednakże dekoduje składnik URI. Metody te można wykorzystać odpowiednio do kodowania i dekodowania przekazywanych wartości do formatu UTF-8.
Składnia(metoda „encodeURIComponent()”)
koduj komponent URI ( X )W podanej składni „ X ” wskazuje identyfikator URI, który ma zostać zakodowany.
Wartość zwracana
Ta metoda pobrała zakodowany identyfikator URI jako ciąg.
Składnia („metoda „decodeURIComponent()”)
dekoduj komponent URI ( X )Tutaj, ' X ” odnosi się do identyfikatora URI, który ma zostać zdekodowany.
Wartość zwracana
Ta metoda daje zdekodowany identyfikator URI.
Przykład 1: Kodowanie UTF-8 w JavaScript
Ten przykład koduje przekazany ciąg do zakodowanej wartości UTF-8 za pomocą funkcji zdefiniowanej przez użytkownika:
powrót ucieczka ( koduj komponent URI ( X ) ) ;
}
niech wal = 'Tutaj' ;
konsola. dziennik ( „Podana wartość ->” + wal ) ;
niech encodeVal = koduj_utf8 ( wal ) ;
konsola. dziennik ( „Zakodowana wartość ->” + wartość kodowania ) ;
W tych liniach kodu wykonaj poniższe kroki:
- Najpierw zdefiniuj funkcję „ encode_utf8() ”, który koduje przekazany ciąg znaków reprezentowany przez określony parametr.
- To kodowanie odbywa się za pomocą „ zakodujURIComponent() ” w definicji funkcji.
- Notatka: „ ucieczka() ” zastępuje dowolną sekwencję ucieczki reprezentowanym przez nią znakiem.
- Następnie zainicjuj wartość do zakodowania i wyświetl ją.
- Teraz wywołaj zdefiniowaną funkcję i przekaż zdefiniowaną kombinację znaków jako argumenty, aby zakodować tę wartość w formacie UTF-8.
Wyjście
Można tutaj zasugerować, że poszczególne znaki są odpowiednio reprezentowane i kodowane w UTF-8.
Przykład 2: Dekodowanie UTF-8 w JavaScript
Poniższa demonstracja kodu dekoduje przekazaną wartość (w postaci znaków) do zakodowanej reprezentacji UTF-8:
powrót dekoduj komponent URI ( ucieczka ( X ) ) ;
}
niech wal = 'à çè' ;
konsola. dziennik ( „Podana wartość ->” + wal ) ;
niech rozszyfruje = dekodowanie_utf8 ( wal ) ;
konsola. dziennik ( „Zdekodowana wartość ->” + rozszyfrować ) ;
W tym bloku kodu:
- Podobnie zdefiniuj funkcję „ dekodowanie_utf8() ”, który dekoduje przekazaną kombinację znaków za pomocą „ dekodujURIComponent() ' metoda.
- Notatka: „ ucieczka() ” pobiera nowy ciąg znaków, w którym różne znaki są zastępowane szesnastkowymi sekwencjami specjalnymi.
- Następnie określ kombinację znaków do zdekodowania i uzyskaj dostęp do zdefiniowanej funkcji, aby odpowiednio przeprowadzić dekodowanie do UTF-8.
Wyjście

W tym przypadku można zasugerować, że zakodowana wartość z poprzedniego przykładu jest dekodowana do wartości domyślnej.
Podejście 2: Kodowanie/dekodowanie UTF-8 w JavaScript przy użyciu metod „encodeURI()” i „decodeURI()”
„ kodujURI() ” koduje identyfikator URI, zastępując każde wystąpienie wielu znaków pewną liczbą sekwencji ucieczki reprezentujących kodowanie znaku UTF-8. W porównaniu do „ zakodujURIComponent() ”, ta konkretna metoda koduje ograniczoną liczbę znaków.
„ dekodowaćURI() ” jednak dekoduje identyfikator URI (zakodowany). Metody te można zastosować w połączeniu w celu kodowania i dekodowania kombinacji znaków w wartości zakodowanej w formacie UTF-8.
Składnia(metoda encodeURI())
kodujURI ( X )W powyższej składni „ X ” odpowiada wartości, która ma być zakodowana jako URI.
Wartość zwracana
Ta metoda pobiera zakodowaną wartość w postaci ciągu znaków.
Składnia (metoda decodeURI())
dekodowaćURI ( X )Tutaj, ' X ” reprezentuje zakodowany identyfikator URI, który ma zostać zdekodowany.
Wartość zwracana
Zwraca zdekodowany identyfikator URI w postaci ciągu znaków.
Przykład 1: Kodowanie UTF-8 w JavaScript
Ta demonstracja koduje przekazaną kombinację znaków do zakodowanej wartości UTF-8:
powrót ucieczka ( kodujURI ( X ) ) ;
}
niech wal = 'Tutaj' ;
konsola. dziennik ( „Podana wartość ->” + wal ) ;
niech encodeVal = koduj_utf8 ( wal ) ;
konsola. dziennik ( „Zakodowana wartość ->” + wartość kodowania ) ;
Przypomnijmy tutaj podejścia do definiowania funkcji przeznaczonej do kodowania. Teraz zastosuj metodę „encodeURI()”, aby przedstawić przekazaną kombinację znaków jako ciąg zakodowany w UTF-8. Następnie podobnie zdefiniuj znaki, które mają być oceniane i wywołaj zdefiniowaną funkcję, przekazując zdefiniowaną wartość jako argumenty w celu wykonania kodowania.
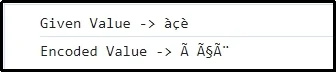
Wyjście
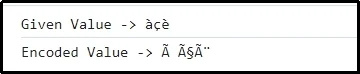
Tutaj widać, że przekazana kombinacja znaków została pomyślnie zakodowana.
Przykład 2: Dekodowanie UTF-8 w JavaScript
Poniższa demonstracja kodu dekoduje zakodowaną wartość UTF-8 (w poprzednim przykładzie):
powrót dekodowaćURI ( ucieczka ( X ) ) ;
}
niech wal = 'à çè' ;
konsola. dziennik ( „Podana wartość ->” + wal ) ;
niech rozszyfruje = dekodowanie_utf8 ( wal ) ;
konsola. dziennik ( „Zdekodowana wartość ->” + rozszyfrować ) ;
Zgodnie z tym kodem zadeklaruj funkcję „ dekodowanie_utf8() ”, który zawiera określony parametr reprezentujący kombinację znaków do zdekodowania przy użyciu „ dekodowaćURI() ' metoda. Teraz określ wartość do zdekodowania i wywołaj zdefiniowaną funkcję, aby zastosować dekodowanie do „ UTF-8 reprezentacja.
Wyjście
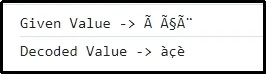
Wynik ten oznacza, że wcześniej zakodowana wartość jest odpowiednio ustalana.
Podejście 3: Kodowanie/dekodowanie UTF-8 w JavaScript przy użyciu wyrażeń regularnych
W tym podejściu stosuje się kodowanie w taki sposób, że wielobajtowy ciąg znaków Unicode jest kodowany jako wiele znaków jednobajtowych w formacie UTF-8. Podobnie dekodowanie przeprowadza się w taki sposób, że zakodowany ciąg znaków jest dekodowany z powrotem do wielobajtowych znaków Unicode.
Przykład 1: Kodowanie UTF-8 w JavaScript
Poniższy kod koduje wielobajtowy ciąg Unicode do jednobajtowych znaków UTF-8:
Jeśli ( typ wal != 'strunowy' ) rzucić nowy TypBłąd ( „Parametr” wal „nie jest ciągiem” ) ;
konst string_utf8 = wal. zastępować (
/[\u0080-\u07ff]/g , // U+0080 - U+07FF => 2 bajty 110yyyyy, 10zzzzzz
funkcjonować ( X ) {
był na zewnątrz = X. charCodeAt ( 0 ) ;
powrót Strunowy . z CharCode ( 0xc0 | na zewnątrz >> 6 , 0x80 | na zewnątrz & 0x3f ) ; }
) . zastępować (
/[\u0800-\uffff]/g , // U+0800 - U+FFFF => 3 bajty 1110xxxx, 10yyyyyy, 10zzzzzz
funkcjonować ( X ) {
był na zewnątrz = X. charCodeAt ( 0 ) ;
powrót Strunowy . z CharCode ( 0xe0 | na zewnątrz >> 12 , 0x80 | na zewnątrz >> 6 & 0x3F , 0x80 | na zewnątrz & 0x3f ) ; }
) ;
konsola. dziennik ( „Wartość zakodowana przy użyciu wyrażenia regularnego ->” + string_utf8 ) ;
}
kodujUTF8 ( 'Tutaj' )
W tym fragmencie kodu:
- Zdefiniuj funkcję „ kodujUTF8() ” zawierający parametr reprezentujący wartość, która ma być zakodowana jako „ UTF-8 ”.
- W swojej definicji należy sprawdzić przekazaną wartość, która nie jest ciągiem znaków, używając „ typ ” i zwróć określony wyjątek niestandardowy za pomocą operatora „ rzucić słowo kluczowe.
- Następnie zastosuj „ charCodeAt() ' I ' zCharCode() ” metody umożliwiające pobranie Unicode pierwszego znaku w ciągu i przekształcenie podanej wartości Unicode na znaki.
- Na koniec wywołaj zdefiniowaną funkcję, przekazując podaną sekwencję znaków, aby zakodować tę wartość jako „ UTF-8 reprezentacja.
Wyjście

Dane wyjściowe oznaczają, że kodowanie zostało przeprowadzone prawidłowo.
Przykład 2: Dekodowanie UTF-8 w JavaScript
W tej demonstracji sekwencja znaków jest dekodowana w postaci „ UTF-8 reprezentacja:
Jeśli ( typ wal != 'strunowy' ) rzucić nowy TypBłąd ( „Parametr” wal „nie jest ciągiem” ) ;
konst ul = wal. zastępować (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g ,
funkcjonować ( X ) {
był na zewnątrz = ( ( X. charCodeAt ( 0 ) & 0x0f ) << 12 ) | ( ( X. charCodeAt ( 1 ) & 0x3f ) << 6 ) | ( X. charCodeAt ( 2 ) & 0x3f ) ;
powrót Strunowy . z CharCode ( na zewnątrz ) ; }
) . zastępować (
/[\u00c0-\u00df][\u0080-\u00bf]/g ,
funkcjonować ( X ) {
był na zewnątrz = ( X. charCodeAt ( 0 ) & 0x1f ) < '+str);
}
decodeUTF8('à çè')
W tym kodzie:
- Podobnie zdefiniuj funkcję „ dekodowaćUTF8() ” posiadający parametr odnoszący się do przekazanej wartości do zdekodowania.
- W definicji funkcji sprawdź warunek ciągu przekazanej wartości poprzez „ typ operatora.
- Teraz zastosuj „ charCodeAt() ”, aby pobrać kod Unicode odpowiednio pierwszego, drugiego i trzeciego ciągu znaków.
- Zastosuj także „ String.fromCharCode() ”, aby przekształcić wartości Unicode w znaki.
- Podobnie powtórz tę procedurę ponownie, aby pobrać kod Unicode pierwszego i drugiego ciągu znaków i przekształcić te wartości Unicode na znaki.
- Na koniec uzyskaj dostęp do zdefiniowanej funkcji, aby zwrócić zdekodowaną wartość UTF-8.
Wyjście

Tutaj można sprawdzić, czy dekodowanie zostało wykonane poprawnie.
Wniosek
Kodowanie/dekodowanie w reprezentacji UTF-8 można przeprowadzić za pomocą „ enodeURIComponent()” I ' dekodujURIComponent() metody, „ kodujURI() ' I ' dekodowaćURI() ” lub przy użyciu wyrażeń regularnych.