Ten post ilustruje metodę korzystania z funkcji i klas wyjściowych analizatora składni poprzez framework LangChain.
Jak korzystać z parsera wyjściowego poprzez LangChain?
Parsery wyjściowe to wyjścia i klasy, które mogą pomóc w uzyskaniu uporządkowanego wyniku z modelu. Aby poznać proces korzystania z parserów wyjściowych w LangChain, po prostu wykonaj wymienione kroki:
Krok 1: Zainstaluj moduły
Najpierw rozpocznij proces korzystania z parserów wyjściowych, instalując moduł LangChain wraz z jego zależnościami, aby przejść przez proces:
pypeć zainstalować łańcuch językowy
Następnie zainstaluj moduł OpenAI, aby korzystać z jego bibliotek, takich jak OpenAI i ChatOpenAI:
pypeć zainstalować otwórz
Teraz skonfiguruj środowisko dla OpenAI za pomocą klucza API z konta OpenAI:
importuj nas
zaimportuj getpass
os.środowisko [ „OPENAI_API_KEY” ] = getpass.getpass ( „Klucz API OpenAI:” )
Krok 2: Importuj biblioteki
Następnym krokiem jest zaimportowanie bibliotek z LangChain w celu wykorzystania parserów wyjściowych w frameworku:
z langchain.prompts zaimportuj HumanMessagePromptTemplate
z pydantycznego pola importu
z langchain.prompts importuj ChatPromptTemplate
z langchain.output_parsers importuj PydanticOutputParser
z pydantycznego importu BaseModel
z pydantycznego walidatora importu
z langchain.chat_models importuj ChatOpenAI
z langchain.llms importuje OpenAI
od wpisania listy importu
Krok 3: Budowanie struktury danych
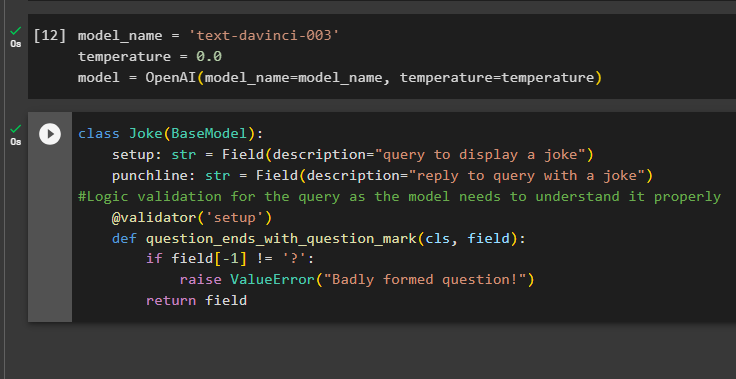
Budowanie struktury wyników jest istotnym zastosowaniem analizatorów wyjściowych w modelach wielkojęzycznych. Zanim przejdziemy do struktury danych modeli, konieczne jest zdefiniowanie nazwy modelu, którego używamy, aby uzyskać ustrukturyzowane dane wyjściowe z parserów wyjściowych:
temperatura = 0,0
model = OpenAI ( Nazwa modelu =nazwa_modelu, temperatura =temperatura )
Teraz użyj klasy Joke zawierającej model BaseModel, aby skonfigurować strukturę danych wyjściowych w celu uzyskania żartu z modelu. Następnie użytkownik może łatwo dodać niestandardową logikę sprawdzania poprawności za pomocą klasy pydantic, która może poprosić użytkownika o umieszczenie lepiej sformułowanego zapytania/podpowiedzi:
klasowy żart ( Model podstawowy ) :konfiguracja: str = pole ( opis = „zapytanie o wyświetlenie żartu” )
pointa: str = Pole ( opis = „odpowiedz na pytanie żartem” )
#Weryfikacja logiczna zapytania, ponieważ model musi je poprawnie zrozumieć
@ walidator ( 'organizować coś' )
def pytanie_końce_ze_znakiem_pytania ( cls, pole ) :
Jeśli pole [ - 1 ] ! = „?” :
podnieść błąd wartości ( „Źle sformułowane pytanie!” )
powrót pole
Krok 4: Ustawianie szablonu podpowiedzi
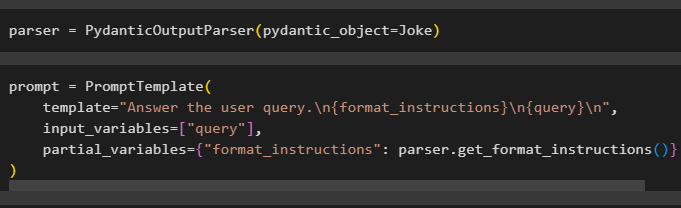
Skonfiguruj zmienną parsera zawierającą metodę PydanticOutputParser() zawierającą jej parametry:
Po skonfigurowaniu parsera wystarczy zdefiniować zmienną podpowiedzi za pomocą metody PromptTemplate() ze strukturą zapytania/podpowiedzi:
zachęta = szablon podpowiedzi (szablon = „Odpowiedz na zapytanie użytkownika. \N {format_instrukcje} \N {zapytanie} \N ' ,
zmienne_wejściowe = [ 'zapytanie' ] ,
częściowe_zmienne = { „format_instrukcje” : parser.get_format_instructions ( ) }
)
Krok 5: Przetestuj analizator wyjściowy
Po skonfigurowaniu wszystkich wymagań utwórz zmienną, która będzie przypisywana za pomocą zapytania, a następnie wywołaj metodę format_prompt():
_input = zachęta.format_prompt ( zapytanie =żart_zapytanie )
Teraz wywołaj funkcję model(), aby zdefiniować zmienną wyjściową:
wyjście = model ( _input.to_string ( ) )Zakończ proces testowania, wywołując metodę parser() ze zmienną wyjściową jako parametrem:
parser.analiza ( wyjście ) 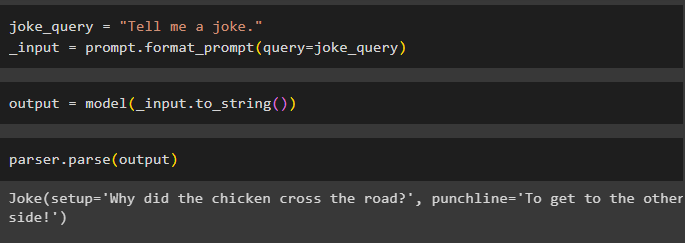
To wszystko, jeśli chodzi o proces korzystania z parsera wyjściowego w LangChain.
Wniosek
Aby użyć parsera wyjściowego w LangChain, zainstaluj moduły i skonfiguruj środowisko OpenAI przy użyciu jego klucza API. Następnie zdefiniuj model, a następnie skonfiguruj strukturę danych wyjściowych z logiczną walidacją zapytania dostarczonego przez użytkownika. Po skonfigurowaniu struktury danych wystarczy ustawić szablon podpowiedzi, a następnie przetestować parser wyjściowy, aby uzyskać wynik z modelu. Ten przewodnik ilustruje proces korzystania z parsera wyjściowego w środowisku LangChain.