W tym artykule zamieszczono demonstrację krok po kroku pobierania i instalowania sterownika Amazon Redshift JDBC w wersji 2.1.
Jak pobrać sterownik Amazon Redshift JDBC, wersja 2.1?
AWS świadczy usługi w chmurze dla firm, umożliwiając im przechowywanie ogromnych danych bez konieczności zarządzania nimi i zapewniania im bezpieczeństwa. AWS Redshift JDBC to kolejna funkcja i usługa oferowana przez AWS, która pozwala dużym firmom przechowywać ogromne ilości danych, których rozmiar sięga petabajtów.
Amazon Redshift ułatwił analizę danych i generowanie wglądu w dane, ale nie udostępnia żadnej platformy, na której można wykonywać te operacje.
W tym artykule przedstawimy procedurę krok po kroku korzystania ze sterownika JDBC:
Warunek wstępny: Zainstaluj Java i Workbench
AWS udostępnia sterownik, który można połączyć z innymi narzędziami innych firm, takimi jak My SQL workbench, Eclipse, JAVA itp., aby uzyskać znaczący wgląd w dane.
- Odwiedź oficjalną stronę internetową firmy JAVA RE . Przewiń w dół i kliknij „ Okna zakładka. Następnie kliknij łącze pobierania, aby rozpocząć pobieranie JAVA RE.
- Następnie odwiedź oficjalną stronę internetową firmy Środowisko pracy SQL . Przewiń w dół do sekcji Linki do pobrania i kliknij łącze. Po pobraniu instalatora. Wewnątrz Instalatora otwórz interfejs SQL Workbench.
Tutaj pobierane są wszystkie wymagania wstępne, teraz utwórz Redshift i pobierz jego sterownik do łączności:
Krok 1: Przesunięcie ku czerwieni Amazona
W pasku wyszukiwania Amazon wpisz i wyszukaj „ Amazonka Redshift ” i kliknij wynik podobny do następującego wyróżnionego wyniku:
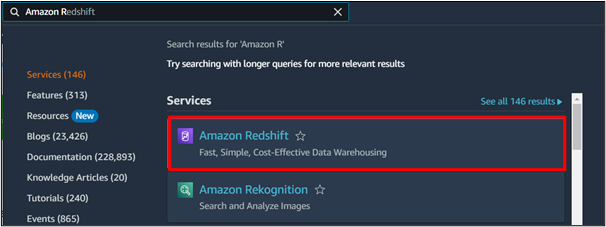
Krok 2: Utwórz klaster
W panelu kontrolnym AWS Redshift kliknij „ Utwórz klaster ' przycisk:
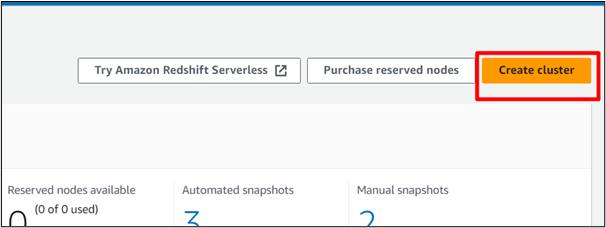
Krok 3: Określ nazwę klastra
W ' Identyfikator klastra ” wpisz nazwę wybranego klastra. Pozostałe ustawienia pozostaną takie same:
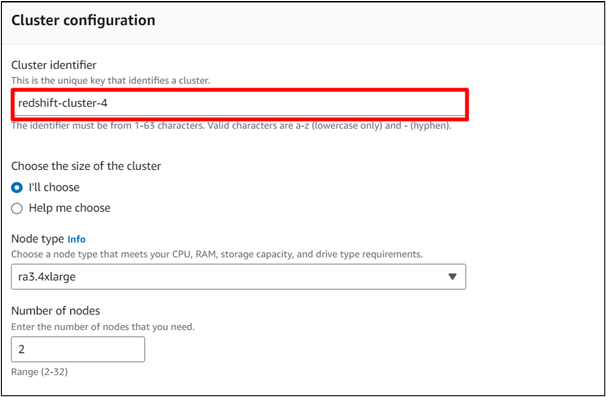
Krok 4: Załaduj dane
Jeśli chcesz, aby Twój klaster miał predefiniowane fikcyjne dane, możesz zaznaczyć opcję „ Załaduj przykładowe dane ” opcja :

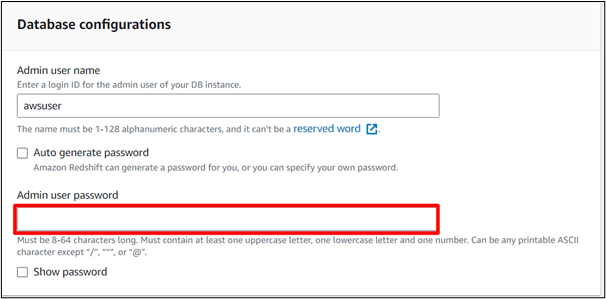
Krok 5: Wpisz hasło
Podaj hasło do klastra. Będzie to użyte podczas łączenia się ze środowiskiem roboczym SQL:
Krok 6: Konfiguracja zakończona
Po zakończeniu konfiguracji klastra kliknij przycisk „ Utwórz klaster ' przycisk:
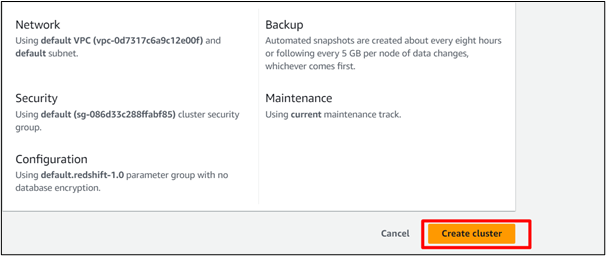
W tym przypadku załadowanie przykładowych danych i utworzenie klastra przesunięcia ku czerwieni zajmie trochę czasu:
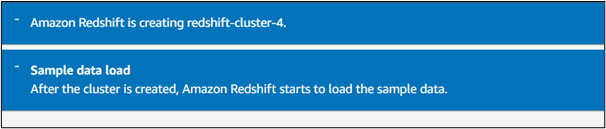
Krok 7: Pobierz sterownik
Na pulpicie nawigacyjnym klastra Redshift wybierz klaster i przejdź do „ Połącz się z klastrem przesunięcia ku czerwieni ' Sekcja. Tutaj kliknij „ Pobierz sterownik ”, aby pobrać najnowszy sterownik JDBC:
Notatka : Możesz także pobrać najnowszą wersję sterownika Redshift z witryny Dokumentacja AWS-a :
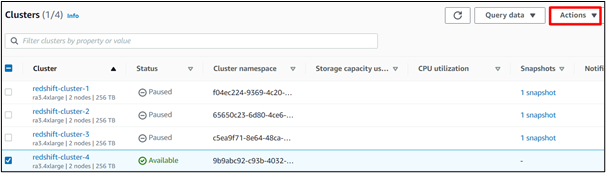
Krok 8: Zmodyfikuj akcje
Na ' Klastry ”, kliknij przycisk „ działania ' przycisk:
Krok 9: Zmodyfikuj dostęp
Z listy rozwijanej Działania kliknij opcję „ Zmodyfikuj ustawienia dostępne publicznie ' opcja:
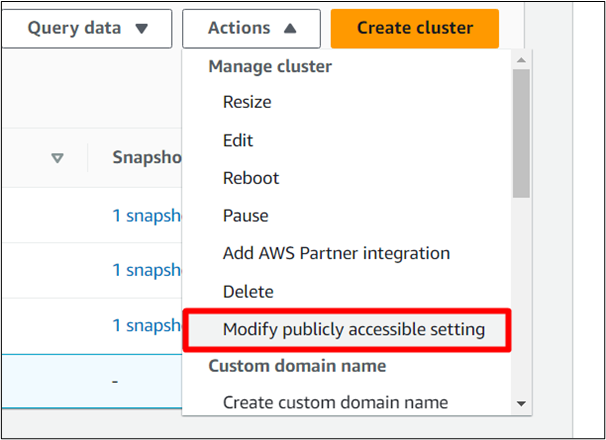
Krok 10: Włącz Dostęp
Sprawdź ' Włącz opcję Dostępny publicznie ” i zapisz zmiany:
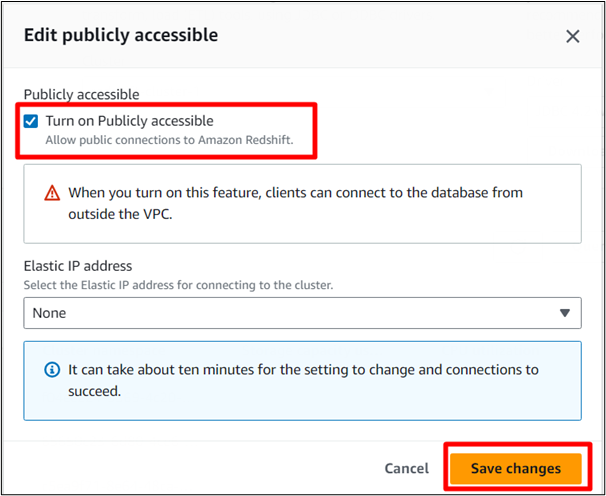
W tym miejscu AWS zapisze zmiany w klastrze.

Dodatkowa wskazówka: Jak utworzyć połączenie za pomocą środowiska SQL Workbench?
Aby połączyć się ze środowiskiem roboczym SQL, wykonaj poniższe kroki:
Krok 1: Otwórz plik wykonywalny SQL Workbench
W pobranym instalatorze kliknij „ Środowisko pracy SQL ” plik wykonywalny i kliknij „ Zarządzaj sterownikami ” w interfejsie:
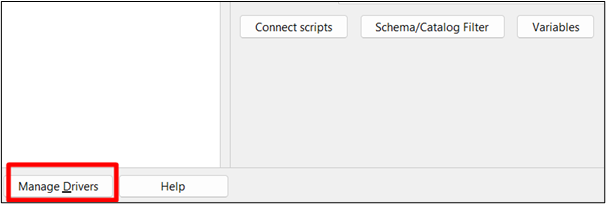
Krok 2: Nowy sterownik
Kliknij na ' Nowy plik ”, jak pokazano na poniższym obrazku:
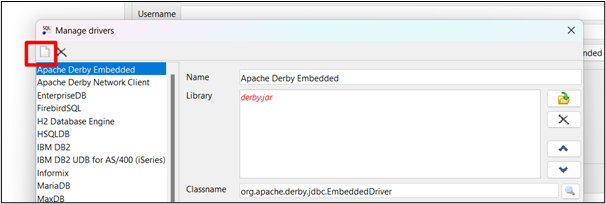
Krok 3: Podaj informacje kierowcy
Podaj nazwę sterownika i kliknij podświetlony przycisk, aby przeglądać ścieżkę pobranego sterownika JDBC. Sterownik, który pobraliśmy wcześniej, przejdź do jego ścieżki i podaj go tutaj:
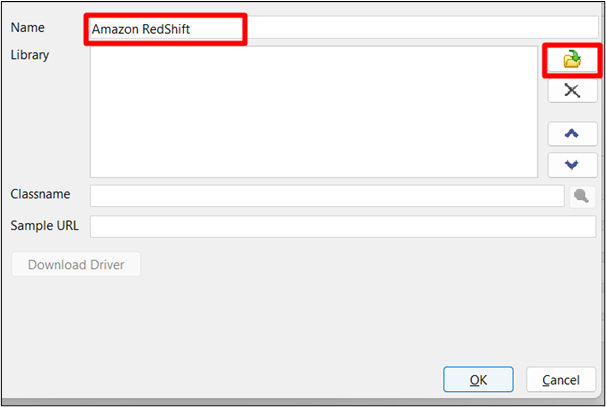
Krok 4: Zapisz zmiany
Następnie kliknij „ OK ”, aby zapisać zmiany:
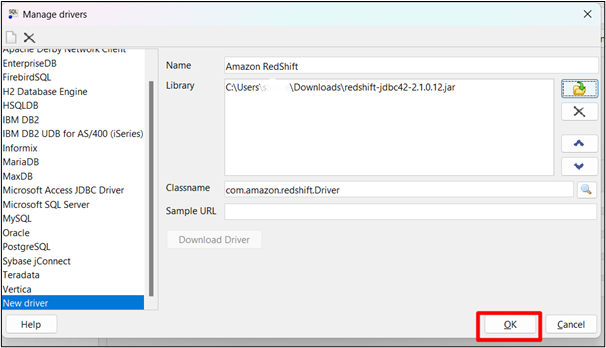
Krok 5: Skopiuj adres URL
Przejdź do pulpitu nawigacyjnego Amazon Redshift Cluster i wybierz klaster. Skopiuj adres URL klastra:
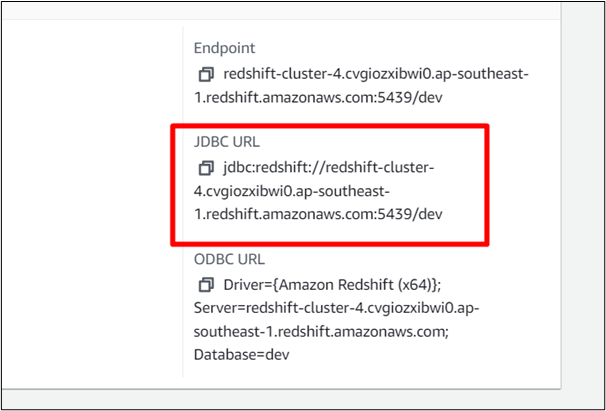
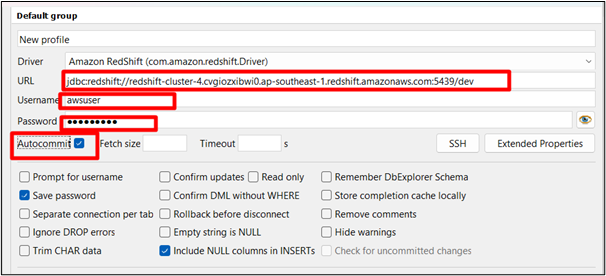
Krok 6: Podaj nazwę sterownika i adres URL
Podaj nazwę sterownika i wklej jego adres URL w interfejsie połączenia środowiska roboczego SQL. Sprawdź ' Automatyczne zatwierdzanie ' skrzynka:
Krok 7: Testuj
Kliknij na ' Test ”, aby przetestować łączność:
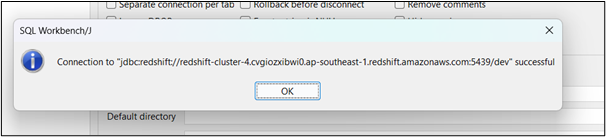
Tutaj połączenie zakończyło się pomyślnie w testowaniu łączności:
Krok 8: Naciśnij przycisk „OK”.
Po pomyślnym zakończeniu testu kliknij przycisk „ OK ' przycisk:
To wszystko z przewodnika.
Wniosek
AWS JDBC zapewnia bezpieczeństwo danych i przestrzeń do zarządzania ogromnymi ilościami danych i można go podłączyć do różnych narzędzi innych firm, instalując je i wklejając adres URL JDBC. AWS oferuje swoim użytkownikom wiele innych usług zapewniających łatwość sprawnego i efektywnego zarządzania danymi. W tym artykule przedstawiono praktyczną demonstrację pobierania i instalowania sterownika JDBC.