W JavaScript można to zrobić poprzez „ okno.fetch() ' metoda. Jednak w „ węzeł.js ”, tę funkcjonalność można osiągnąć za pomocą wielu pakietów, np. pobierania węzłów itp.
W tym blogu opisano następujące obszary treści:
- Co to jest „pobieranie węzła”?
- Wymagania wstępne dotyczące korzystania z pobierania węzłów.
- Jak tworzyć żądania HTTP w node.js za pomocą pobierania węzłów?
- Jak rozpocząć korzystanie z pobierania węzłów?
- Wysyłaj żądania pobierania za pośrednictwem pobierania węzłów.
- Pobierz dane JSON z interfejsu API Rest.
- Żądania wysyłania poprzez pobieranie węzłów.
- Jakie są kody stanu HTTP?
- Radzenie sobie z wyjątkami i ograniczeniami.
- Inne przypadki użycia pobierania węzłów.
- Wniosek
Co to jest „pobieranie węzła”?
„ pobieranie węzła ” odpowiada lekkiemu modułowi, który udostępnia interfejs API pobierania dla node.js. Moduł ten umożliwia także użytkownikom korzystanie z „ aportować() ” metoda w node.js, która jest w większości podobna do JavaScript „ okno.fetch() ' metoda.
Składnia (metoda fetch())
aportować ( adres URL [ , opcje ] ) ;
W tej składni:
- „ adres URL ” odnosi się do adresu URL zasobu, który należy pobrać/odzyskać.
- „ opcje Parametr ” jest potrzebny, gdy istnieje potrzeba użycia metody „fetch()” w inny sposób niż wykonanie „ DOSTAWAĆ ' wniosek.
Wartość zwracana
Ta funkcja pobiera obiekt Response zawierający informacje dotyczące odpowiedzi HTTP w następujący sposób:
- tekst: Pobiera treść odpowiedzi w postaci ciągu.
- nagłówki: Zwraca obiekt zawierający procedury obsługi odpowiedzi.
- json(): Analizuje treść odpowiedzi w obiekcie JSON.
- tekst statusu/status: Zawiera informacje dotyczące kodu stanu HTTP.
- OK: Daje „ PRAWDA ”, jeśli status to kod stanu 2xx.
Wymagania wstępne dotyczące korzystania z pobierania węzłów
Poniżej przedstawiono warunki wstępne, które należy wziąć pod uwagę przed rozpoczęciem korzystania z „ pobieranie węzła ”:
- Zainstalowano co najmniej lub najnowszą wersję niż 17.5.
- Podstawowa znajomość JavaScript.
Jak tworzyć żądania HTTP w node.js za pomocą pobierania węzłów?
Wysyłanie żądań HTTP jest procedurą asynchroniczną, ponieważ otrzymanie żądanej odpowiedzi zajmuje trochę czasu. Z tego powodu mogą istnieć dwie metodologie wykorzystania procedur asynchronicznych. Po pierwsze, użytkownik może poczekać na odpowiedź, a następnie wznowić działanie z kodem. Drugi wykonuje kod równolegle.
Jak rozpocząć korzystanie z pobierania węzłów?
Przed rozpoczęciem lub instalacją „ pobieranie węzła ”, zainicjuj projekt węzła za pomocą poniższego polecenia:
inicjacja npm - I 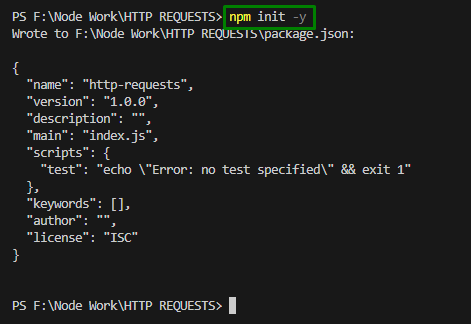
Wykonanie tego polecenia tworzy „ pakiet.json ” w bieżącym katalogu w następujący sposób:
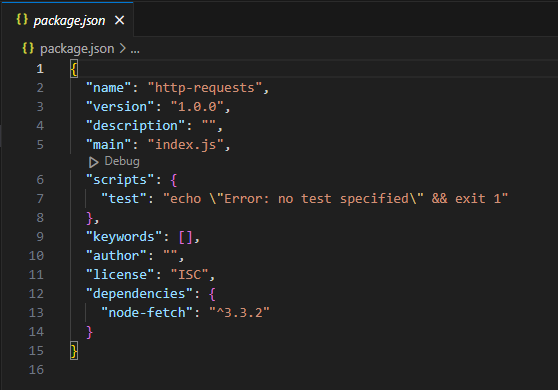
Teraz zainstaluj „ pobieranie węzła ” przy użyciu następującego polecenia cmdlet:
npm zainstaluj węzeł - aportować 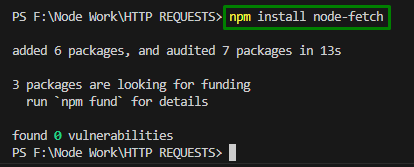
Aby jednak zainstalować docelową wersję modułu, użyj następującego polecenia:
npm zainstaluj węzeł - aportować@ 2.0W tym przypadku „ 2.0 ” zostanie zainstalowana wersja modułu.
Notatka: Zanim przejdziesz do przykładów, utwórz „ indeks.mjs ” w obszarze roboczym, który będzie używany do zastosowania funkcjonalności.
Przykład 1: Wysyłaj żądania pobierania za pośrednictwem pobierania węzłów
„ pobieranie węzła ” można wykorzystać do pobrania tekstu z serwera WWW lub danych poprzez Rest API.
Poniższy przykład kodu napisany w utworzonym „ indeks.mjs ” umożliwia proste żądanie Pobierz do strony głównej YouTube:
import aportować z „pobranie węzła” ;aportować ( „https://youtube.com” )
. Następnie ( rez => rez. tekst ( ) )
. Następnie ( tekst => konsola. dziennik ( tekst ) ) ;
W tych liniach kodu:
- Załaduj „ pobieranie węzła ” i pobierz stronę główną YouTube za pośrednictwem określonego adresu URL, do którego kierowane jest żądanie HTTP.
- Następnie połącz łańcuchem „ Następnie() ” metody obsługi odpowiedzi i danych ze złożonego żądania.
- Pierwsza metoda „then()” wskazuje oczekiwanie na odpowiedź z serwera YouTube i przekształcenie jej do formatu tekstowego.
- Ta ostatnia metoda „then()” oznacza oczekiwanie na wynik poprzedniej transformacji i wyświetla go na konsoli.
Wyjście
Teraz wykonaj kod za pomocą następującego polecenia cmdlet:
indeks węzła. mjsWykonanie powyższego polecenia powoduje pobranie całego znacznika HTML strony głównej YouTube wyświetlanej na konsoli:
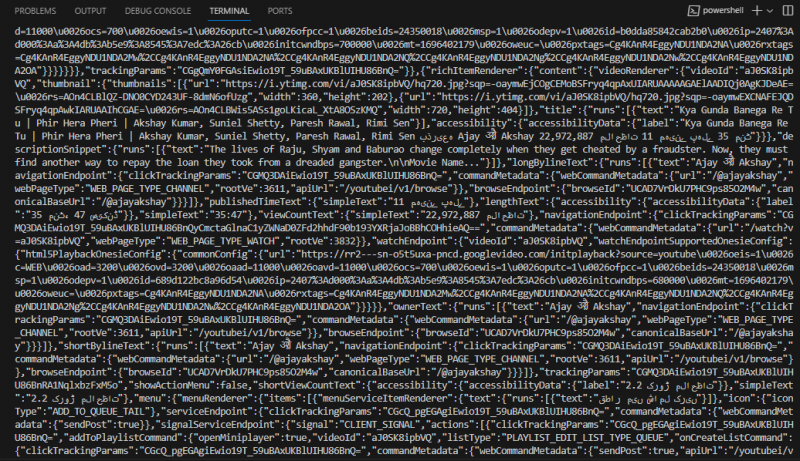
Przykład 2: Pobierz dane JSON z interfejsu API Rest
W tym przykładzie zastosowano „ pobieranie węzła ”, aby uzyskać fałszywe dane za pośrednictwem JSONZbiornik zastępczy RestAPI. Jest tak, że „ aportować() ” zawiera adres URL serwera i oczekuje na odpowiedź:
import aportować z „pobranie węzła” ;aportować ( „https://jsonplaceholder.typicode.com/users” )
. Następnie ( rez => rez. json ( ) )
. Następnie ( json => {
konsola. dziennik ( „Pierwszy użytkownik tablicy ->” ) ;
konsola. dziennik ( json [ 0 ] ) ;
konsola. dziennik ( „Nazwa użytkownika pierwszej tablicy ->” ) ;
konsola. dziennik ( json [ 0 ] . nazwa ) ;
} )
Zgodnie z tym blokiem kodu wykonaj następujące kroki:
- Treść HTTPS zawiera dane w formacie JSON zawierające dane użytkownika.
- Następnie „ json() ” służy do wywoływania poszczególnych wpisów i odpowiadających im wartości.
Wyjście
Zastosuj poniższe polecenie cmdlet, aby wykonać kod:
indeks węzła. mjs 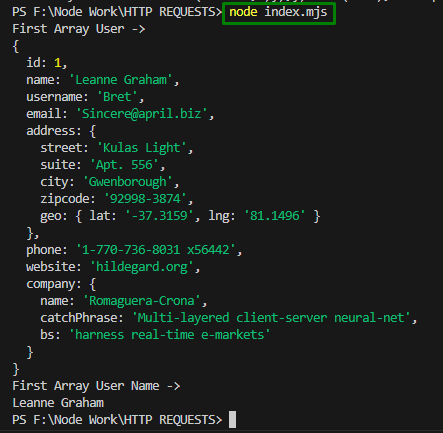
Przykład 3: Żądania wysyłania poprzez pobieranie węzłów
„ pobieranie węzła ” można również wykorzystać do wysyłania żądań zamiast ich pobierania. Można to osiągnąć poprzez „ aportować() ”, która zawiera dodatkowy parametr umożliwiający wysyłanie żądań POST do serwera.
Za pomocą tego parametru można przypisać wiele opcji. Jednakże w tym przypadku „ metoda „”, „ ciało ' I ' nagłówki ' będzie użyty. Poniżej znajduje się opis każdej z opcji:
- „ metoda ” opcja ustawia typ żądań HTTP, tj. „POST” w tym scenariuszu.
- „ ciało ” zawiera treść żądania.
- „ nagłówek ” zawiera wszystkie wymagane nagłówki, tj. „ Typ zawartości ' w tym scenariuszu.
Teraz przejdź do praktycznej implementacji wysyłania żądań pocztowych, dołączając nowy element do symbolu zastępczego JSON „ Wszystko ”. Odbywa się to poprzez dodanie do listy nowej pozycji o identyfikatorze użytkownika „476”:
import aportować z „pobranie węzła” ;niech wszystko = {
identyfikator użytkownika : 476 ,
strona : „To jest Linuxhint” ,
zakończony : FAŁSZ
} ;
aportować ( „https://jsonplaceholder.typicode.com/todos” , {
metoda : 'POST' ,
ciało : JSON. sznurować ( Wszystko ) ,
nagłówki : { 'Typ zawartości' : „aplikacja/json” }
} ) . Następnie ( rez => rez. json ( ) )
. Następnie ( json => konsola. dziennik ( json ) ) ;
W tym kodzie:
- Przede wszystkim utwórz obiekt todo i przekształć go w JSON, dołączając go do treści.
- Teraz podobnie określ adres URL z wymaganymi opcjami jako „ aportować() ” opcjonalne parametry metody.
- Następnie zastosuj „ JSON.stringify() ” metoda służąca do przekształcenia obiektu w sformatowany ciąg znaków (JSON) przed wysłaniem/przesłaniem go na serwer WWW.
- Idąc dalej, wdrażaj połączone „ Następnie() ” metody pobierania danych poprzez oczekiwanie na odpowiedź, przekształcanie jej do formatu JSON i logowanie się do konsoli.
Wyjście
Wykonaj poniższe polecenie, aby wykonać kod:
indeks węzła. mjs 
Jakie są kody stanu HTTP?
Zanim przejdziesz do następnego przykładu, upewnij się, że jeśli odpowiedź zawiera „ 3xx ” kod statusu, klient musi wykonać dodatkowe kroki. Podobnie „ 4xx ” kody reprezentują nieprawidłowe żądanie, a „ 5xx ” odpowiadają błędom serwera.
Notatka: „ złapać() ” nie radzi sobie z opisanymi powyżej przypadkami, gdyż komunikacja z serwerem odbywa się w sposób usprawniony. Dlatego skutecznym podejściem zapewniającym, że nieudane żądania zwrócą błąd, jest zdefiniowanie funkcji analizującej status HTTP odpowiedzi serwera.
Przykład 4: Radzenie sobie z wyjątkami i ograniczeniami
W wysyłanych żądaniach może występować kilka ograniczeń lub wyjątków, np. problemy z Internetem, „ aportować() ” ograniczenia funkcji itp. Z tymi wyjątkami można sobie poradzić, dodając „ złapać() funkcja:
funkcja analizujStatus ( X ) {Jeśli ( X. OK ) {
powrót X
} w przeciwnym razie {
rzucić nowy Błąd ( `Stan HTTP w odniesieniu do odpowiedzi -> $ { X. status } ( $ { X. statusTekst } ) ` ) ;
}
}
aportować ( „https://jsonplaceholder.typicode.com/MissingResource” )
. Następnie ( analizuj stan )
. Następnie ( X => X. json ( ) )
. Następnie ( json => konsola. dziennik ( json ) )
. złapać ( błądzić => konsola. dziennik ( błądzić ) ) ;
W tym fragmencie kodu:
- Najpierw zdefiniuj funkcję mającą podany parametr, a następnie przeanalizuj odpowiedź, aby poradzić sobie z napotkanymi ograniczeniami.
- Teraz dołącz „ Jeśli inaczej ”, aby zgłosić napotkany błąd lub niestandardowe ograniczenie.
- Następnie analogicznie zastosuj „ aportować() ” i powiązane z nią metody „then()” umożliwiające pobranie danych poprzez oczekiwanie na odpowiedź, przekształcenie ich do formatu JSON i zalogowanie się do konsoli.
- Na koniec, wyjątki w czasie wykonywania można rozwiązać, umieszczając „ złapać() ” na końcu łańcucha obietnic.
Wyjście
Na koniec uruchom poniższe polecenie cmdlet, aby uruchomić kod i zgłosić napotkane wyjątki:
indeks węzła. mjs 
Inne przypadki użycia „node-fetch”
„ pobieranie węzła ” można również wykorzystać do zrobienia „ Żądania API ' Lub ' Skrobanie sieci ”. Omówmy szczegółowo te przypadki użycia.
Wykorzystanie pobierania węzłów do tworzenia żądań API
Interfejs API może być wymagany w kilku scenariuszach do pobierania danych docelowych za pośrednictwem źródła zaplecza. Żądania HTTP mogą mieć wiele metod uwierzytelniania, np. przy użyciu klucza API, gdy dostawca API udostępnia klucz, który jest ograniczony tylko do użytkownika. Innym podejściem do ochrony interfejsu API może być użycie „ Uwierzytelnianie podstawowe ”, w którym należy wysłać nagłówek, aby wywołać API.
Poniżej znajduje się demonstracja drugiego podejścia, tj. „Podstawowego uwierzytelniania” w żądaniu pocztowym za pomocą „ aportować() ' metoda:
( asynchroniczny ( ) => {konst X = czekać na pobranie ( „http://httpbin.org/post” , {
metoda : 'POST' ,
nagłówki : {
'Upoważnienie' : `Podstawowe $ { brachu ( 'Login Hasło' ) } `
} ,
ciało : JSON. sznurować ( {
'klucz' : 'wartość'
} )
} ) ;
konst wynik = poczekaj x. tekst ( ) ;
konsola. dziennik ( wynik ) ;
} ) ( ) ;
W powyższej demonstracji nagłówek jest wysyłany z „ baza64 ” zakodowany ciąg znaków w formacie „ Login Hasło ”.
Wykorzystanie pobierania węzłów do skrobania sieci
„ Skrobanie sieci ” odnosi się do techniki pobierania danych/treści ze stron internetowych i ich analizowania. Analizę tę osiąga się poprzez „ pozdrawiam ' biblioteka.
Poniżej znajduje się demonstracja pobierania tytułu strony za pomocą przycisku „ aportować() ” metoda i „ pozdrawiam ' biblioteka:
konst biblioteka = wymagać ( 'wiwat' ) ;( asynchroniczny ( ) => {
konst X = czekać na pobranie ( „https://linuxhint.com/” ) ;
konst I = poczekaj x. tekst ( ) ;
konst $ = biblioteka. obciążenie ( I ) ;
konsola. dziennik ( $ ( 'tytuł' ) . Pierwszy ( ) . tekst ( ) ) ;
} ) ( ) ;
W tym przykładzie pobierany jest kafelek „ Linuksa ” tytuł witryny.
Wniosek
Żądania HTTP w node.js można wykonywać za pomocą funkcji pobierania węzłów, wysyłając żądania get, pobierając dane JSON z interfejsu API REST lub wysyłając żądania pocztowe. Ponadto wyjątki i ograniczenia można skutecznie obsługiwać za pośrednictwem „ złapać() ”funkcja.