„Wartości rozdzielane przecinkami (CSV) to jeden z najbardziej wszechstronnych i łatwych w użyciu formatów danych. Jest to lekki format danych, który umożliwia programistom i aplikacjom przesyłanie i analizowanie danych z jednego źródła do drugiego.
Dane CSV przechowują dane w formacie tabelarycznym, w którym każda kolumna jest oddzielona przecinkiem, a nowy rekord jest przypisywany do nowego wiersza. To sprawia, że jest to bardzo dobry wybór do eksportowania baz danych, takich jak bazy danych SQL, dane Cassandra i inne.
Nic więc dziwnego, że spotkasz się ze scenariuszem, w którym musisz zaimportować plik CSV do swojej bazy danych.
Celem tego samouczka jest pokazanie szybkiej i prostej metody importowania pliku CSV do klastra Elasticsearch za pomocą pulpitu nawigacyjnego Kibana.”
Wskoczmy.
Wymagania
Przed nurkowaniem upewnij się, że masz następujące wymagania:
- Klaster Elasticsearch z zielonym stanem zdrowia.
- Serwer Kibana połączony z Twoim klastrem Elasticsearch.
- Wystarczające uprawnienia do zarządzania indeksami w klastrze.
Przykładowy plik CSV
Jak zwykle pierwszym wymaganiem jest źródłowy plik CSV. Dobrze jest upewnić się, że dane w Twoim pliku CSV są dobrze sformatowane i nie zawierają błędów.
W celach ilustracyjnych użyjemy bezpłatnego zestawu danych zawierającego filmy i programy telewizyjne z Amazon Prime.
Otwórz przeglądarkę i przejdź do poniższego zasobu:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Postępuj zgodnie z procedurą, aby pobrać zestaw danych na komputer lokalny. Pobrane archiwum możesz rozpakować za pomocą polecenia:
$ rozsunąć suwak a~ / Pliki do pobrania / archiwum.zip
Importuj plik CSV
Po przygotowaniu pliku źródłowego możemy kontynuować i przedyskutować, jak go zaimportować.
Zacznij od przejścia do głównego pulpitu nawigacyjnego Kibana i wybrania opcji „prześlij plik”.
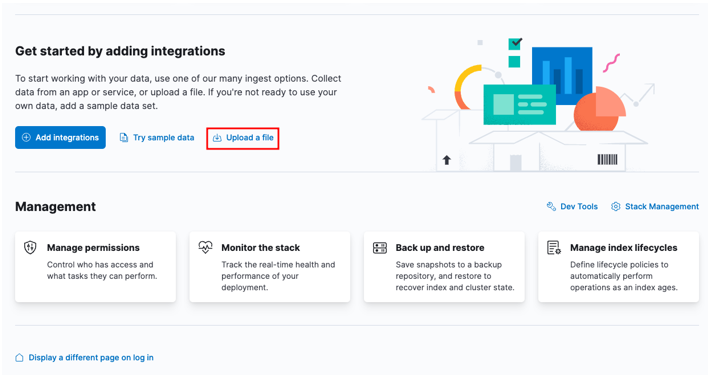
W oknie programu uruchamiającego znajdź docelowy plik CSV, który chcesz zaimportować.
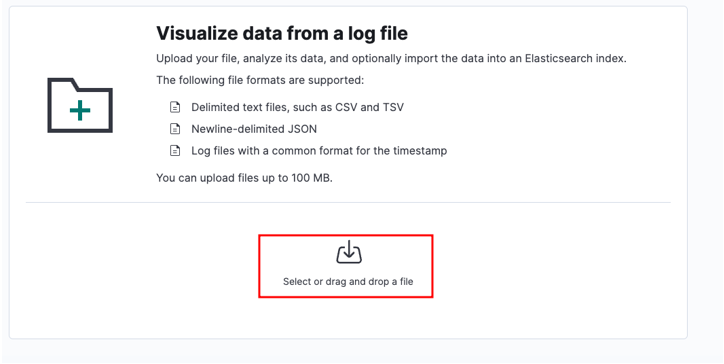
Wybierz plik źródłowy i kliknij prześlij.
Pozwól Elasticsearch i Kibanie na analizę przesłanego pliku. Spowoduje to przeanalizowanie pliku CSV i określenie formatu danych, pól, typów danych itp.
UWAGA: W zależności od konfiguracji klastra i rozmiaru danych ten proces może chwilę potrwać. Upewnij się, że węzeł główny odpowiada, aby uniknąć przekroczenia limitu czasu.
Po zakończeniu procesu powinieneś otrzymać próbkę zawartości pliku i statystyki pliku przeanalizowane przez Elastic.
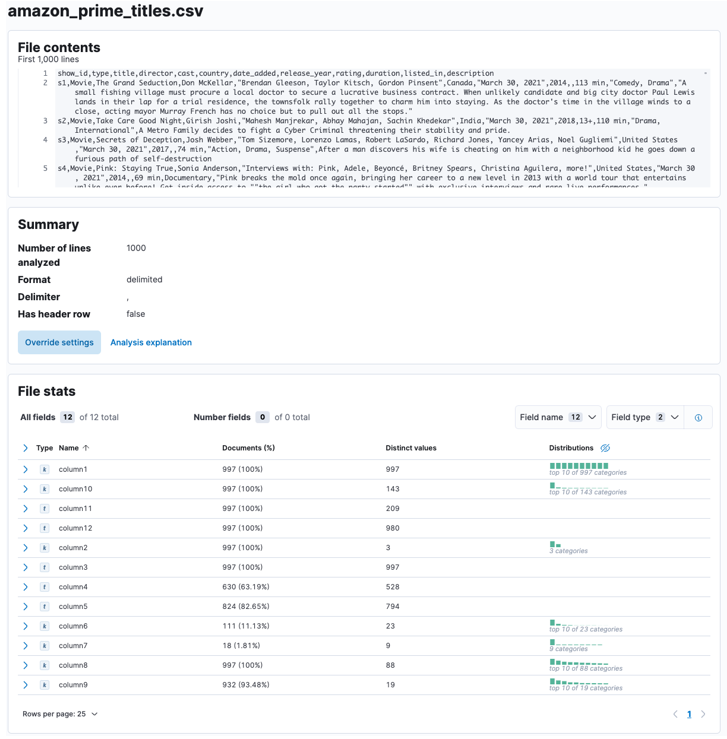
Możesz dostosować wiele parametrów, na przykład ogranicznik, wiersze nagłówka itp. Na przykład możemy dostosować powyższe dane wyjściowe, aby poinformować Elastic, że nasz plik CSV zawiera pliki nagłówkowe.
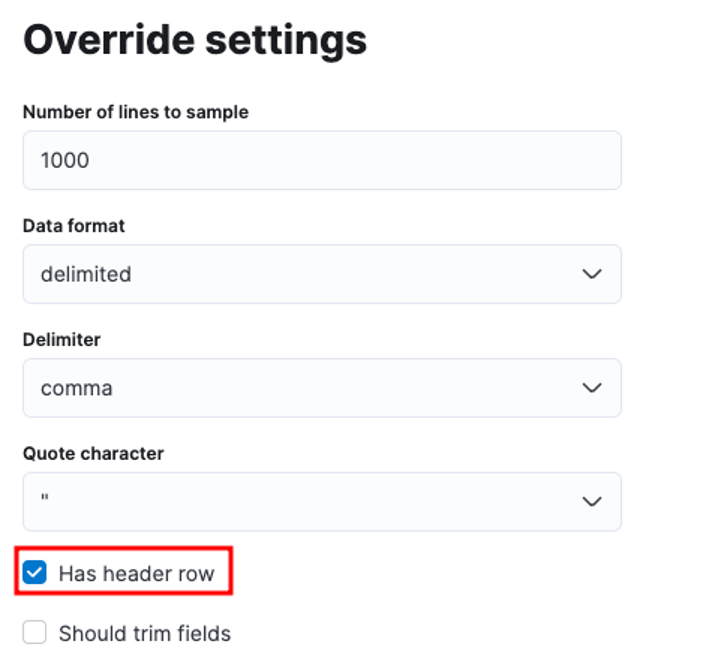
Następnie możemy kliknąć Zastosuj i ponownie przeanalizować dane. Powinno to sformatować dane we właściwym formacie, łącznie z polami.
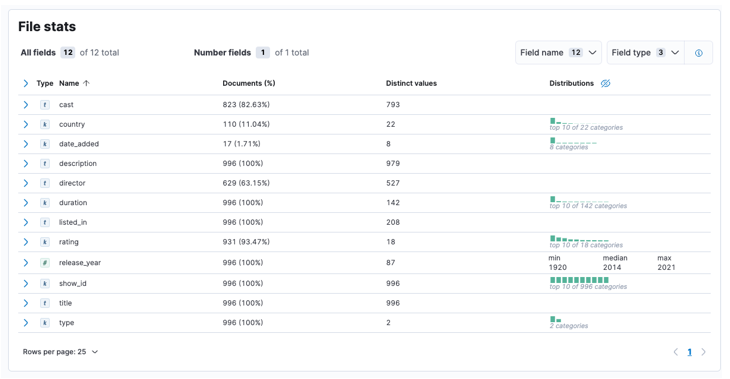
Następnie możemy kliknąć import, aby przejść do zaimportowanego pulpitu nawigacyjnego.
Tutaj musimy utworzyć indeks, w którym przechowywane są dane CSV. Do indeksu możesz przypisać dowolną obsługiwaną nazwę.
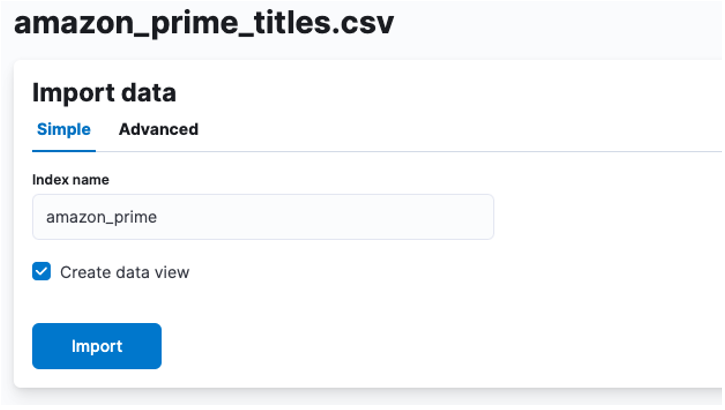
Jeśli chcesz dostosować właściwości indeksu, takie jak liczba odłamków, replik, mapowań itp. Wybierz opcję zaawansowaną i dostosuj ustawienia zgodnie z własnymi upodobaniami.
Na koniec kliknij importuj i obserwuj, jak Kibana robi swoją „magię”. Po zakończeniu możesz uzyskać dostęp do swojego indeksu za pośrednictwem Elasticsearch API lub korzystając z pulpitu nawigacyjnego Kibana.
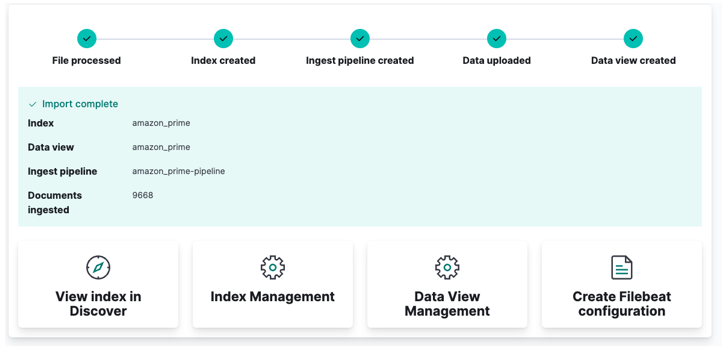
I gotowe!!
Wniosek
W tym poście omówiliśmy proces pobierania i importowania zestawu danych CSV do klastra Elasticsearch za pomocą pulpitu nawigacyjnego Kibana.
Dzięki za przeczytanie i miłego kodowania!!