Hostowanie danych w bazach danych i hurtowniach danych oraz zarządzanie nimi zawsze było trudnym i kłopotliwym zadaniem. Aby zrozumieć dane, potrzebne są duże zasoby i moc obliczeniowa. Amazon Web Services ma do tego kompleksowe rozwiązanie. Posiada usługę o nazwie Amazon Redshift, która w pełni zarządza hurtowniami danych użytkowników.
W tym artykule szczegółowo wyjaśniono Amazon Redshift wraz z architekturą hurtowni danych. Wszystkie elementy architektury systemu hurtowni danych Redshift zostaną szczegółowo wyjaśnione.
Co to jest przesunięcie ku czerwieni Amazona?
IT to usługa hurtowni danych świadczona przez firmę Amazon. Skutecznie zarządza dużymi zbiorami danych i je analizuje na potrzeby analiz i raportowania. Jest zbudowany w oparciu o model magazynu kolumnowego. Wykorzystuje klastry węzłów obliczeniowych kontrolowane przez węzeł wiodący, aby zapewnić wysoką wydajność przetwarzania danych.
Pobiera dane z różnych źródeł i łączy je w hurtownię danych. Oferuje różne funkcje, takie jak udostępnianie danych i analityka w czasie rzeczywistym. Obejrzyj poniższy obrazek, aby poznać funkcje i możliwości Amazon Redshift:
Przejdźmy teraz do architektury systemu hurtowni danych.
Jaka jest architektura systemu hurtowni danych Amazon Redshift?
Ta architektura systemu składa się z trzech podstawowych części. Te części to:
- Składowanie
- Przyśpieszenie
- Obliczenie
Rozumiemy ich cele:
Składowanie
Część magazynowa dotyczy usług magazynowania, które oferuje Redshift. Posiada własną opcję usługi zarządzanej pamięci masowej, a także opcję wiadra S3.
Przyśpieszenie
Część akceleracyjna zależy od używanej usługi przechowywania danych i zastosowanej mocy obliczeniowej. Pamięć masowa zarządzana za pomocą przesunięcia ku czerwieni jest szybsza w porównaniu z innymi opcjami pamięci masowej
Obliczenie
Część obliczeniowa dotyczy wyłącznie wykorzystywanej mocy obliczeniowej. Obliczenia przeprowadza się na klastrach, a klastry mają węzły. Węzły z kolei mają plasterki.
Aby lepiej zrozumieć wszystkie elementy i komponenty tej architektury, spójrz na poniższy obrazek:
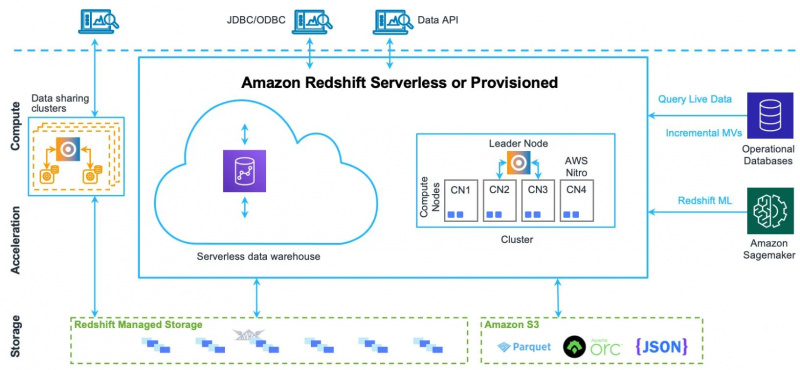
Przyjrzyjmy się po kolei jego składnikom.
Jakie są elementy architektoniczne Amazon Redshift?
Poniżej znajdują się elementy architektoniczne Amazon Redshift:
- Klastry
- Węzły
- Wycinki węzłów
- Składowanie
- Wewnętrzna sieć
- Bazy danych
Omówmy je jeden po drugim:
Klastry
Klaster jest jednostką podstawową i rdzeniową. Zawiera szereg węzłów. Jeśli klaster składa się z wielu węzłów obliczeniowych, wkracza dodatkowy węzeł wiodący, który koordynuje działania tych węzłów obliczeniowych i zarządza komunikacją zewnętrzną.
Węzły
Węzły w klastrach są dwojakiego rodzaju. To są:
- Węzeł Lidera
- Węzeł obliczeniowy
Rozumiemy je po kolei:
Węzeł Lidera
Zarządza komunikacją z programami klienckimi i koordynuje interakcje z węzłami obliczeniowymi. Węzeł wiodący odgrywa istotną rolę w wykonywaniu złożonych zapytań. Kompiluje kod na podstawie planu wykonania, który jest dystrybuowany do węzłów obliczeniowych i przypisuje porcje danych do każdego pojedynczego węzła obliczeniowego.
Węzeł obliczeniowy
Węzły obliczeniowe stanowią szkielet architektury Amazon Redshift. Dokonują zarówno przechowywania, jak i przetwarzania danych. Mają one dedykowane zasoby, takie jak pamięć i procesor.
Wycinki węzłów
Węzły obliczeniowe są dalej dzielone na wycinki. Te wycinki współpracują ze sobą, aby przetwarzać przydzielone obciążenia i osiągać równoległość w celu usprawnienia przetwarzania zapytań.
Składowanie
Przechowywanie danych w Amazon Redshift jest zarządzane przez „Redshift Managed Storage (RMS)”. Ma możliwość niezależnego skalowania pamięci masowej przy użyciu pamięci „Amazon S3”. RMS wykorzystuje wysokowydajną lokalną pamięć masową opartą na dyskach SSD jako pamięć podręczną warstwy 1, która optymalizuje wydajność.
Wewnętrzna sieć
Ta wewnętrzna sieć w Amazon Redshift pomaga w szybkiej i bezpiecznej komunikacji między węzłami wiodącymi a węzłami obliczeniowymi. Sieć ta nie jest bezpośrednio dostępna dla aplikacji klienckich.
Bazy danych
Klastry posiadają jedną lub więcej baz danych. Dane z tych baz danych znajdują się w węzłach obliczeniowych. Aplikacje klienckie komunikują się z węzłem wiodącym. Węzeł obliczeniowy zarządza wykonywaniem zapytań w węzłach obliczeniowych.
To wszystko dotyczy Amazon Redshift i jego elementów architektonicznych. W tym artykule kompleksowo wyjaśniono działające komponenty Amazon Redshift
Wniosek
Architektura Amazon Redshift jest powodem, na którym opierają się jego możliwości. Węzeł wiodący kontroluje i zarządza węzłami obliczeniowymi, a wycinki węzłów pomagają w przetwarzaniu równoległym. Magazyn zarządzany Redshift wykorzystuje pamięć masową opartą na dyskach SSD w celu zwiększenia wydajności. W tym artykule wyjaśniono architekturę systemu hurtowni danych Amazon Redshift.