„W „pandach” możemy łatwo odczytać plik tekstowy za pomocą metody „pandy”. „Pandy” dają nam możliwość odczytania pliku tekstowego. „Pandas” udostępnia różne wbudowane metody odczytywania pliku tekstowego. Omówimy tutaj wszystkie metody w tym samouczku wraz ze wszystkimi parametrami i wyjaśnimy je szczegółowo. Ponadto odczytamy plik tekstowy w „pandach” za pomocą metod „pand” w naszych kodach tutaj”.
Metody czytania pliku tekstowego w „pandach”
W „pandach” mamy trzy metody, które pomagają nam w odczytaniu pliku tekstowego. Zrobiliśmy tutaj również kilka przykładów, w których odczytujemy plik tekstowy. Metody oferowane przez „pandy” omówiono poniżej:
-
- Korzystając z metody pd.read_csv().
- Korzystając z metody pd.read_table().
- Korzystając z metody pd.read_fwf().
Teraz wyjaśniamy składnię wszystkich tych metod, a także szczegółowo omawiamy parametry wszystkich metod w tym samouczku.
Składnia read_csv()
pd.read_csv ( „nazwapliku.txt”, wrz =' ', nagłówek =Brak, nazwy = [ „Nazwa_kolumny1”, „Nazwa_kolumny2, „Nazwa_kolumny2”, ………….. ] )
W tej metodzie najpierw dodajemy nazwę pliku tekstowego, którego dane chcemy odczytać i jest to pierwszy parametr tej metody. Następnie umieszczamy „sep”, który jest separatorem w tej metodzie, i umieszczamy tutaj spację jako znak, aby traktował spację jako separator. Po tym mamy parametr header i używana jest wartość „None” tego parametru, więc utworzy domyślny nagłówek, a jeśli nie dodamy tego parametru, rozważy pierwszą linię pliku tekstowego jako nagłówek. W parametrze „nazwy” możemy dodać nazwy kolumn, które musimy dodać jako nagłówek.
Składnia read_table()
pd.read_table ( 'nazwa_pliku.txt' , ogranicznik = ' ' )
W tej metodzie jako pierwszy parametr wstawiamy nazwę pliku tekstowego. W separatorze, gdy umieścimy „ ”, to jako separator przyjmie znak spacji.
Składnia read_fwf()
pd.read_fwf ( 'nazwa_pliku.txt' )
Ta metoda przyjmuje tylko jeden parametr, którym jest nazwa pliku tekstowego.
Teraz użyjemy tych metod do odczytywania plików tekstowych w kodach „pand” i pokazywania danych pliku tekstowego na terminalu.
Przykład # 01
Aplikacja „Spyder” jest tutaj, w której wykonaliśmy wszystkie kody przedstawione w tym samouczku. Poniżej znajduje się plik tekstowy, którego dane chcemy odczytać. Użyjemy metody „read_csv()” do odczytania tego pliku tekstowego w „pandach”.
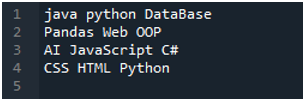
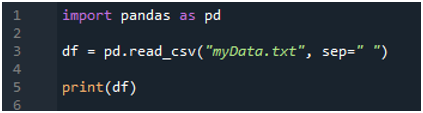
Najpierw importujemy bibliotekę „pandy”, ponieważ chcemy wykorzystać metodę „read_csv()”, a jest to metoda „pand”. Dostęp do tej metody uzyskujemy tylko wtedy, gdy zaimportowaliśmy bibliotekę „pand”. W tym miejscu wspominamy „pandy jako pd”, więc to „pd” jest umieszczane z nazwą metody jego użycia. Następnie tworzymy tutaj zmienną „df”, która służy do przechowywania danych pliku tekstowego po odczytaniu. Umieszczamy tutaj metodę „pd.read_csv()”, która pomaga w odczytywaniu pliku tekstowego i konwertowaniu danych pliku tekstowego do DataFrame i przechowywaniu go w zmiennej „df”.
Przekazaliśmy nazwę pliku, która brzmi „myData.txt”, tutaj, a następnie używamy „sep” i przypisujemy temu „sep” pusty znak. Tak więc ten pusty znak działa jako separator w pliku tekstowym. Następnie wykorzystaliśmy poniższy „print()”, który służy do drukowania danych z pliku tekstowego. Wyświetli dane pliku tekstowego w formularzu DataFrame.
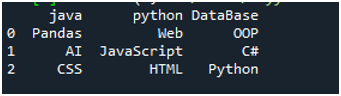
Aby wykonać ten kod, musimy nacisnąć „Shift + Enter”, a dane wyjściowe zostaną wyrenderowane na terminalu „Spyder”. Wynik powyższego kodu jest wyświetlany na podanym zrzucie ekranu i widać, że dane pliku tekstowego są wyświetlane jako DataFrame, a pierwszy wiersz naszego pliku tekstowego jest tutaj prezentowany jako nazwy kolumn tego DataFrame. Oddziela również dane, w których w pliku tekstowym występuje znak spacji.
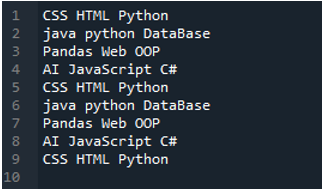
Przykład # 02
Plik tekstowy, który odczytamy w tym przykładzie, jest pokazany tutaj i ponownie użyjemy metody „read_csv()”, ale z innymi parametrami.
Wykorzystywana jest metoda „pandy” „pd.read_csv()” i przekazujemy tutaj trzy parametry. Najpierw umieszczamy nazwę pliku, którą jest „Record.txt”. Drugi parametr to parametr „sep” i przypisuje mu pusty znak, a następnie mamy trzeci parametr, w którym ustawiamy „header” i dostosowujemy go na „None”, dzięki czemu utworzy domyślny nagłówek DataFrame kiedy wykonujemy ten kod. Zapisaliśmy to wszystko w zmiennej „My_Record”, a także dodaliśmy „My_Record” w funkcji „print()” do drukowania.

Wszystkie dane są zapisywane w DataFrame i oddziela dane, w których w danych pliku tekstowego występuje znak spacji. Ponadto utworzył tutaj domyślny nagłówek DataFrame, ponieważ dostosowaliśmy parametr „header” do „Brak”.
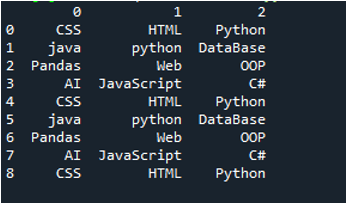
Przykład nr 03
Wyświetlany jest plik tekstowy tego przykładu i ponownie użyjemy metody „read_csv()” ze zmodyfikowanymi parametrami.
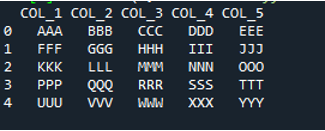
W tym kodzie cztery parametry są przekazywane tutaj do metody „pandy” „pd.read_csv()”. Pierwszym parametrem jest nazwa pliku tekstowego. Parametr „sep” otrzymuje pusty znak w drugim parametrze. Parametr „nagłówek” jest ustawiony na „Brak” w trzecim argumencie, a jako czwarty parametr ustawiliśmy „nazwy”, które pojawią się jako nazwy kolumn DataFrame po odczytaniu pliku tekstowego, a te nazwy kolumn są „COL_1, COL_2, COL_3, COL_4 i COL_5”. Wszystkie te informacje zostały zapisane w zmiennej „My_Record”, a „My_Record” został również dodany do metody „print()”, dzięki czemu będzie drukowany na terminalu.

Wszystkie informacje z pliku tekstowego są tutaj renderowane jako DataFrame, a także oddziela dane, w których spacje są dodawane w pliku tekstowym. Dodaje również odpowiednio nazwy kolumn, które dodaliśmy powyżej w kodzie.
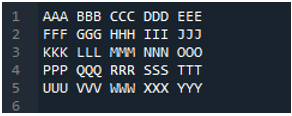
Przykład # 04
Jest to plik tekstowy, który odczytamy w tym przykładzie, korzystając z innej metody, metody „pd.read_table()”.
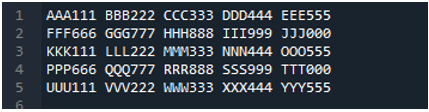
W tym miejscu dodajemy metodę „pd.read_table()” do odczytu pliku tekstowego i dodajemy „ABC.txt”, czyli nazwę pliku tekstowego. Ta metoda pomaga w odczytywaniu pliku tekstowego, a także dostosowaliśmy parametr „delimiter” do znaku spacji, więc będzie działał również jak separator, który wyjaśniliśmy powyżej. Następnie wszystkie dane pliku tekstowego są zapisywane w zmiennej „My_Data” i również tutaj drukowane.

Początkowy wiersz naszego pliku tekstowego jest tutaj pokazany jako nazwy kolumn DataFrame, a dane z pliku tekstowego są drukowane jako DataFrame. Dodatkowo oddziela dane pliku tekstowego, w którym występuje znak spacji.
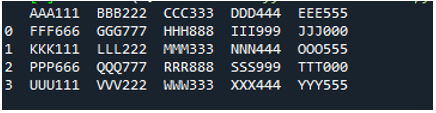
Przykład # 05
Teraz plik tekstowy zawiera dane, które są wyświetlane poniżej. Tym razem zastosujemy „read_fwf()” i pokażemy, jak renderuje dane po odczytaniu pliku tekstowego.
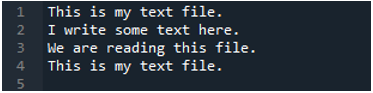
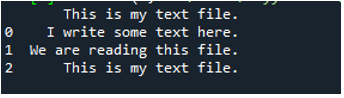
Jak wiemy, ta metoda „read_fwf()” przyjmuje tylko jeden parametr, którym jest nazwa pliku, który chcemy odczytać. Dodajemy tutaj „textfile.txt”, co jest nazwą naszego pliku tekstowego i przypisujemy tę metodę pandy do zmiennej „File_Data”, która będzie przechowywać dane tego pliku tekstowego. Następnie wstawiamy „print(File_Data)”, aby również wydrukować te dane.

Tutaj pokazane są wszystkie dane pliku tekstowego. Nie oddzielił danych, w których występują znaki spacji, ponieważ w tej funkcji nie ma parametru takiego jak „Sep” lub „delimiter”.
Wniosek
Ten samouczek wyjaśnia, jak czytać plik tekstowy w „pandach” i jakie metody są używane do czytania pliku tekstowego w „pandach”. Omówiliśmy wszystkie metody, które pomagają nam w odczytywaniu pliku tekstowego w „pandach”. W tym samouczku zbadaliśmy trzy różne metody „pand” do czytania naszych plików tekstowych w „pandach”. Wyjaśniliśmy również szczegółowo składnię wszystkich metod, a także parametry wszystkich metod i przeczytaliśmy wiele plików tekstowych, stosując różne metody ze wszystkimi możliwymi parametrami w tym samouczku.