Pandas zapewnia dostęp do szerokiego zakresu krytycznych aspektów i instrukcji, które mają na celu szybką ocenę Twoich danych. Wykorzystujemy proces przekształcania Pandas DataFrames w tabele HTML. Programiści i użytkownicy muszą zintegrować swoje ramki DataFrames w Pythonie z kodem źródłowym HTML. Używają tego rozszerzenia Pandas, aby bez wysiłku przenieść swoje dane do pliku HTML w tym celu przy użyciu techniki Pandas to HTML. Aby wyjaśnić metodologię, używamy narzędzia „Spyder” do wdrożenia, aby było łatwe do zrozumienia wraz z każdym wdrożeniem, krok po kroku.
Jeśli chcemy parsować lokalny plik HTML w Pandas, używamy nazwy tagu i aspektów tekstowych. W połączeniu z kodem tagu-ul z pliku możemy dostosować tytuł i treść tagu. Jeśli chcemy uzyskać plik HTML z adresu URL w Pandas, należy wykonać kilka czynności, które obejmują parametr internetowego adresu URL w celu wywołania funkcji skanowania. Następnie odwołujemy się do zmiennych, które umożliwiają przeglądanie obiektów bazy danych i wczytujemy całe wnętrze adresu URL do zmiennej data, aby uruchomić kod i wydrukować dane w formacie HTML.
Składnia Pandy do HTML:

Przykład: Wyświetl renderowanie ramki danych Pandas w kodzie HTML i tabeli
Na stronie internetowej HTML Pandas w Pythonie może zmienić obiekt Pandas DataFrame w tabelę HTML. Pandas DataFrame jest wykonywana przy użyciu metody „pandas.DataFrame.to html()”. Przyjrzyjmy się naszemu przykładowi i omówmy procedurę przekształcenia naszego Pythona DataFrame do kodu źródłowego HTML. Aby to osiągnąć, musimy najpierw zaprojektować ramkę DataFrame, która ostatecznie renderuje się do HTML. Aby zastosować filozofię Pandas do naszego kodu Pythona, konsekwentnie importujemy bibliotekę Pandas jako „pd”.
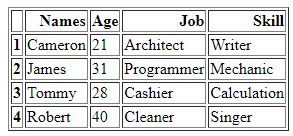
Nasza DataFrame „Członkowie” zawiera słowniki związane z informacjami o członkach wraz z czterema zadeklarowanymi zmiennymi, takimi jak „Imiona”, „Wiek”, „Praca” i „Umiejętności”. Pierwszy wiersz przechowuje dane jako „Cameron” dla „imion”, „21” dla „wiek”, „Architect” dla „Praca” i „Pisarz” dla „Umiejętności”. W ten sposób drugi wiersz wartości zainicjowanych przez DataFrame, które przypisujemy, to „James”, „31”, „Programmer” i „Mechanic” w odpowiednich kolumnach. W ten sposób drugi słownik zawiera w swoich danych „Tommy”, „28”, „Cashier” i „Calculation”. A ostatni wiersz, który przypisujemy do naszej DataFrame, zawiera dane „Robert” jako wartość dla „Imiona”, „40” jako przypisaną wartość dla „Wiek”, „Sprzątacz” jako „Praca” i „Piosenkarz” jako 'Umiejętność'.
Następnie, przypisując dane do naszego DataFrame, zapewniamy im również zakres „indeksu” od „1” do „4”, ponieważ DataFrame może mieć cztery wiersze. Następnie używamy funkcji „pd.dataframe()”, aby scalić dane wraz z numerami indeksu. Na koniec używamy funkcji „print()”, aby wyświetlić naszą ramkę DataFrame.
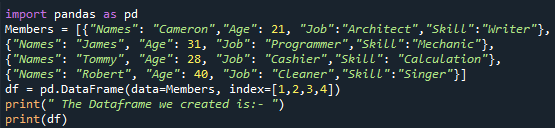
Teraz możemy zobaczyć wyświetlanie naszych „Członków” DataFrame, które stworzyliśmy. Tutaj widzimy, że jest to prosty sposób wyświetlania naszej ramki DataFrame, którą konwertujemy na kod HTML. Po prostu ma cztery kolumny – „Imiona”, „Wiek”, „Praca” i „Umiejętności” – ze wszystkimi podobnymi danymi, które przypisujemy do naszej ramki DataFrame w kodzie. Jego wiersze mają numery indeksów jako „1”, „2”, „3” i „4”. Na tym etapie widzimy, że tworzymy naszych „członków” DataFrame. Po utworzeniu naszej DataFrame przystępujemy do dalszej implementacji.
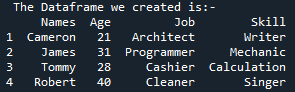
Teraz jest to krok, w którym widzimy, jak możemy przekonwertować naszych „członków” DataFrame na kod HTML. Nadszedł czas, aby zrozumieć sztuczkę Pythona DataFrame to html(), która ewoluuje DataFrame w HTML. Funkcja html() zmienia całą ramkę DataFrame, w wyniku czego każdy wiersz w ramce DataFrame jest odrębną sekwencją w tabeli HTML. W tym celu deklarujemy zmienną „html” i przechowujemy ją za pomocą funkcji „df.to_html()”, aby przekonwertować całą naszą DataFrame na kod HTML. Po zaimplementowaniu funkcji „df.to_html()” stosujemy funkcję „print()” w katalogu „html”.

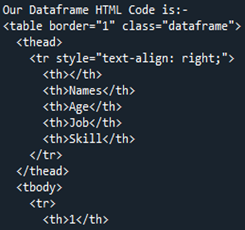
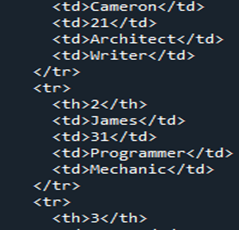
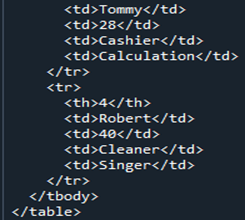
Teraz przyjrzymy się kodowi HTML, który jest konwertowany z Pandas DataFrame „Członkowie”. Jest to sposób na przekonwertowanie dowolnej z naszych ramek DataFrame na kod źródłowy HTML, który opisuje całą ramkę DataFrame w kodzie HTML, w tym wszystkie tagi mające obramowania tabeli jako „1”. Nazwy kolumn są umieszczane pod nagłówkiem „” jako nagłówkiem tabeli elementu HTML, podczas gdy cała DataFrame jest modyfikowana w element HTML „ Ponieważ w naszej DataFrame były cztery wiersze, „ Teraz zapisujemy nasz kod HTML w bieżącym katalogu jako „sygnał” wraz z rozszerzeniem „.html”. Używamy funkcji „open()”, aby określić nazwę lokalizacji pliku jako „file=open(„signal.html”, „w”)”. Ponieważ słowo kluczowe „w” przechowuje go, aby pokazać plik i ujawnić go w formie HTML, używamy funkcji „.write()” i kończymy nasz kod Pand wraz z funkcją „close()” w pliku. Mówimy o większości prostszych przypadków, w których zapisujemy go wraz z rozszerzeniem pliku „.html”, które konwertuje go na HTML i udostępnia interfejs przeglądarki w tym samym katalogu. Po konwersji naszych DataFrame „Members” na HTML, otrzymujemy nasz kod HTML, który zapisujemy najpierw w tej samej lokalizacji katalogu. Kiedy uzyskamy nasz kod źródłowy HTML, możemy go otworzyć wraz z rozszerzeniem internetowym, otwierając plik źródłowy HTML w przeglądarce. Widzimy, że wyświetla dane wyjściowe jako tabelę HTML na stronie przeglądarki. Jak widać w danych wyjściowych tabeli, zawiera ona obramowanie o rozmiarze „1” i nie ma wzdłuż nich odstępów między komórkami. Tabela przedstawia pięć kolumn. Z czego cztery nazwy kolumn to „Imiona”, „Wiek”, „Praca” i „Umiejętności”. Jeśli mówimy o numerze indeksu „1”, ma on „Cameron” w kolumnie „Imiona”, „21” w „Wiek”, „Architect” w „Praca” i „Pisarz” w „Umiejętności”. Numer indeksu „2” w tabeli oznacza „James” w „Imionach”, „31” w „Wiek”, „Programista” w „Praca” i „Mechanik” w „Umiejętności”. Indeks „3” w kolumnie „Nazwiska” pokazuje „Tommy”, „28” w „Wiek”, „Kasjer” w „Praca” i „Obliczenia w kolumnie „Umiejętności” na stronie przeglądarki. Indeks „4” w ostatnim wierszu tabeli pokazuje „Robert” w „Imionach”, „40” w „Wiek”, „Sprzątacz” w „Praca” i „Piosenkarz” w „Umiejętności”. Aby zmienić naszą ramkę DataFrame w kod źródłowy HTML tego artykułu, najpierw połączyliśmy go z nazwą „Członkowie”. Podczas renderowania DataFrame do kodu HTML używamy funkcji „html = df.to html()”. Podczas wyświetlania tabeli HTML używamy katalogu „file = open(„signal.html”, „w”)” i lokalizacji pliku „signal.html”, które są zapisane w tym samym katalogu. Dzięki temu byliśmy w stanie przekształcić nasze Pandas DataFrame w plik kodu źródłowego HTML i pokazać go w tabeli.”. Dodatkowo każdy wiersz DataFrame jest przekształcany w wiersz wraz ze znacznikiem „
” w tabeli HTML. „” używa niektórych elementów „CSS” wraz ze znacznikiem „ ”, który opisuje wiersz tabeli.
” jest używane cztery razy wraz z ich znacznikami zamykającymi. Jak wiemy w HTML, musi mieć zarówno otwierające, jak i zamykające znaczniki w odpowiednim kodzie HTML. Wszystkie dane lub DataFrame są zawarte między otwierającymi „ ” i „
” a zamykającym znacznikiem. Reszta całego kodu HTML zawiera te same dane, co w DataFrame, które są po prostu konwertowane na prosty kod źródłowy HTML wraz z niezbędnymi znacznikami wymaganymi do utworzenia tabeli.

Wniosek