Pandas Set_Option Metoda
Dzisiaj przyjrzymy się, jak używać funkcji „pd.set_option()” do wyświetlania wszystkich kolumn w Pandas Dataframe podczas prezentowania ich w narzędziu Spyder. Aby użyć funkcji „pd.set_option()”, postępujemy zgodnie z podaną składnią:

Zacznijmy poznawanie koncepcji od praktycznej implementacji programu Python.
Przykład: Wykorzystanie metody Pandy Set_Option do wyświetlenia wszystkich kolumn
Ta demonstracja jest przewodnikiem po wyświetlaniu wszystkich kolumn w DataFrame za pomocą Pandy „set_option()”. Wyjaśnimy szczegóły każdego kroku implementacji tej metody Pythona.
Pierwszym warunkiem praktycznej implementacji skryptu Pythona jest znalezienie najlepszego narzędzia, w którym wykonujesz swój program. Narzędziem, którego użyliśmy do naszej ilustracji, jest narzędzie „Spyder”. Uruchomiliśmy narzędzie i rozpoczęliśmy pracę nad skryptem Python.
Zaczynając od kodu, najpierw musimy zaimportować wymagane biblioteki, których potrzebujemy w tym programie. Pierwszą biblioteką, którą załadowaliśmy do naszego pliku Pythona, jest biblioteka Pandas, ponieważ funkcje, których tutaj używamy, są dostarczane przez Pandas. Nazwaliśmy tę bibliotekę aliasem „pd”. Drugą biblioteką, którą załadowaliśmy, jest biblioteka NumPy. NumPy (Numerical Python) to pakiet do obliczeń numerycznych opracowany przez programowanie w Pythonie. Sekcja Importuj NumPy kodu nakazuje Pythonowi zintegrowanie modułu NumPy z bieżącym plikiem Pythona. Część skryptu „as np” następnie nakazuje Pythonowi przypisanie do NumPy skrótu „np”. Umożliwia korzystanie z metod NumPy, wprowadzając „np.nazwa_funkcji” zamiast NumPy.
Teraz zaczynamy od głównego kodu. Najważniejszą i podstawową potrzebą naszego programu jest Pandas DataFrame. Wyświetlamy więc wszystkie zawarte w nim kolumny. Teraz całkowicie od Ciebie zależy, czy chcesz utworzyć ramkę DataFrame z określonymi wartościami, czy chcesz zaimportować plik CSV. Wybraliśmy dla tej instancji utworzenie DataFrame z wartościami NaN. Wywołaliśmy metodę „pd.DataFrame()”, aby skonstruować DataFrame. Tutaj podaliśmy dwa parametry – „indeks” i „kolumny”. Argument „indeks” odnosi się do wierszy, co oznacza, że ustawiamy wiersze dla DataFrame.
Przypisaliśmy parametrowi „indeks” i funkcji NumPy „np.arange() z liczbą wartości „6”. Generuje sześć wierszy dla DataFrame. Wypełnia wszystkie wpisy wartościami NaN, ponieważ nie podaliśmy mu żadnej wartości. Argument „kolumny”, jak określa nazwa, służy do ustawiania kolumn dla DataFrame. Jest również przypisana funkcja „np.arange()” z liczbą wartości „25” dla kolumn. W ten sposób konstruuje 25 kolumn dla DataFrame.
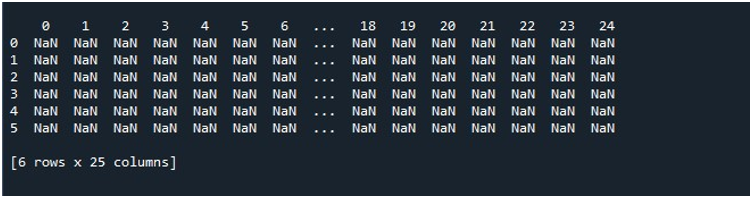
W związku z tym, gdy wywołujemy funkcję „pd.DataFrame()”, mamy ramkę DataFrame z 25 kolumnami i 6 wierszami wypełnionymi wartościami null. Aby zachować tę DataFrame, musimy zbudować obiekt DataFrame, który przechowuje jego zawartość. Dlatego stworzyliśmy obiekt DataFrame „losowy” i przypisaliśmy mu wynik, który otrzymujemy z metody „pd.DataFrame()”. Teraz na pewno chcesz zobaczyć generowaną ramkę DataFrame. Python udostępnia nam metodę wyświetlania danych wyjściowych na ekranie, którą jest funkcja „print()”. Wywołaliśmy tę metodę, przekazując obiekt DataFrame „losowo” jako jego parametr.
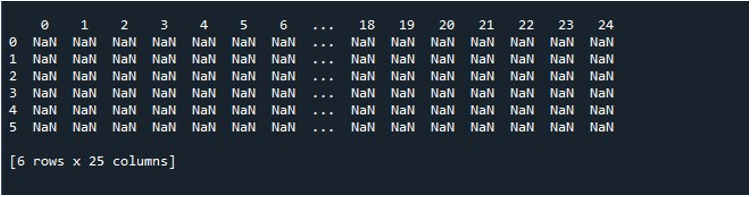
Kiedy wykonujemy ten fragment kodu, otrzymujemy naszą ramkę DataFrame z wartościami NaN wyświetlanymi na terminalu. Tutaj możemy zaobserwować, że widoczne są niektóre z pierwszych kolumn i tylko kilka z końca. Wszystkie kolumny pomiędzy nimi są obcinane. Domyślnie ukrywa niektóre wiersze i kolumny, aby uniknąć frustracji użytkownika przez wyświetlanie ogromnych zestawów danych.
Możesz nawet sprawdzić liczbę wszystkich kolumn w DataFrame za pomocą funkcji „len()” Pandy. Napisz funkcję „len()” w konsoli swojego narzędzia „Spyder”. Wpisz nazwę DataFrame w nawiasach z właściwością „.columns”. Zwraca nam całkowitą długość kolumn w Twojej DataFrame.

Zwraca długość naszej DataFrame, która wynosi 25.
Teraz kolejnym i podstawowym zadaniem jest zmiana domyślnej opcji wyświetlania danych wyjściowych. Mogą zaistnieć okoliczności, w których chcesz wyświetlić całą ramkę DataFrame na terminalu. Z powodu wartości domyślnych wiele wpisów zostaje obciętych, co powoduje rozczarowanie użytkownika. Tutaj dowiesz się, jak rozwiązać ten problem. Pandas udostępnia nam funkcję „pd.set_option()” do zmiany domyślnych ustawień wyświetlania. Zaraz po wyświetleniu DataFrame na konsoli wywołujemy metodę „pd.set_option()”. Podajemy parametr w nawiasach tej funkcji, którego musimy użyć, aby wyświetlić wszystkie kolumny DataFrame.
Tutaj użyliśmy „display.max_columns”, aby wyświetlić maksymalne kolumny w naszej ramce DataFrame. Możemy również zdefiniować wartość tego parametru, czyli maksymalne kolumny, które chcemy wyświetlić. Z drugiej strony ustawiamy „display.max_columns” na „Brak”, co powoduje wyświetlanie wszystkich kolumn z DataFrame o maksymalnej długości. Na koniec zastosowaliśmy funkcję „print()”, aby wyświetlić wynikową ramkę DataFrame ze wszystkimi kolumnami widocznymi na terminalu.
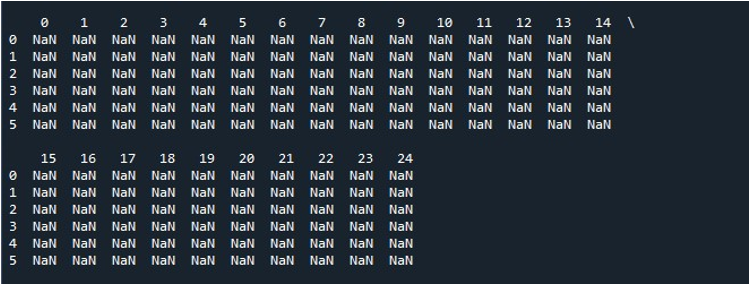
Kiedy klikniemy opcję „Uruchom plik” w narzędziu „Spyder”, możemy wyświetlić wystawianą ramkę DataFrame. Ta ramka DataFrame ma sześć wierszy, a liczba kolumn, które przechowuje, wynosi 25. Nie ma żadnych kolumn, które zostałyby obcięte, ponieważ funkcja „pd.set_option()” z maksymalną długością kolumny jest teraz włączona.
Możemy nawet zresetować opcję wyświetlania, ponieważ gdy ustawimy długość wyświetlania na maksymalną, nadal wyświetla ona ramki DataFrames ze wszystkimi kolumnami w tym konkretnym pliku Pythona. W tym celu używamy Pandy „pd.reset_option()”. Wywołujemy tę funkcję i podajemy „display.max_columns” jako parametr tej funkcji.

To daje nam początkowe ustawienia wyświetlania dla dostarczonej ramki DataFrame.
Wniosek
Przeglądanie pełnych danych wyjściowych na terminalu z ogromnym zbiorem danych czasami wpędza nas w kłopoty, gdy domyślne ustawienia narzędzia stoją w sprzeczności z potrzebami użytkownika. Aby rozwiązać ten problem, Pandas udostępnia nam metodę „pd.set_option()”. W tym przewodniku edukacyjnym przedstawiliśmy Ci tę metodę i potrzebę jej zastosowania. Zademonstrowaliśmy temat z praktycznie skompilowanymi i wykonanymi przykładowymi kodami Pythona. Przedstawiliśmy wyniki ilustracji wykonanej na „Spyder”. Wyjaśniliśmy, jak wyświetlić wszystkie kolumny DataFrame na konsoli, zmieniając ustawienia domyślne, a także resetując wszystkie ustawienia do początkowych. Poświęcenie w pełni skoncentrowanej uwagi na praktycznej implementacji modułu pozwala na wykorzystanie go w przypadku wystąpienia takich problemów.