5.1 Wprowadzenie
System operacyjny komputera Commodore-64 jest dostarczany z komputerem w pamięci tylko do odczytu (ROM). Liczba lokalizacji bajtów pamięci dla Commodore-64 waha się od 0000 $ do FFFF (tj. 000016 do FFFF16, czyli od 010 do 65,53510). System operacyjny mieści się w przedziale od $E000 do $FFFF (tj. od 57,34410 do 65,53610).
Dlaczego warto uczyć się systemu operacyjnego Commodore-64
Po co badać system operacyjny Commodore-64 dzisiaj, skoro był to system operacyjny komputera wydanego w 1982 roku? Cóż, komputer Commodore-64 wykorzystuje jednostkę centralną 6510, która jest ulepszeniem (choć nie większym) modelu 6502 µP.
6502 µP jest nadal produkowany w dużych ilościach; nie dotyczy to już komputerów domowych ani biurowych, ale urządzeń (urządzeń) elektrycznych i elektronicznych. Model 6502 µP jest także prosty w zrozumieniu i obsłudze w porównaniu z innymi mikroprocesorami tamtych czasów. Dzięki temu jest to jeden z najlepszych (jeśli nie najlepszy) mikroprocesor do nauki języka asemblera.
Mikroprocesor 65C02 µP, wciąż należący do klasy mikroprocesorów 6502, posiada 66 instrukcji w języku asemblera, których wszystkich można się nauczyć nawet na pamięć. Nowoczesne mikroprocesory mają wiele instrukcji w języku asemblera i nie można ich nauczyć się na pamięć. Każdy µP ma swój własny język asemblera. Każdy system operacyjny, czy to nowy, czy stary, jest oparty na języku asemblera. Dzięki temu język asemblera 6502 dobrze nadaje się do nauki systemu operacyjnego dla początkujących. Po nauczeniu się systemu operacyjnego, takiego jak Commodore-64, można łatwo nauczyć się nowoczesnego systemu operacyjnego, wykorzystując go jako podstawę.
Nie jest to tylko opinia autora (moja). Jest to rosnący trend na świecie. W Internecie pojawia się coraz więcej artykułów na temat ulepszenia systemu operacyjnego Commodore-64, aby wyglądał jak nowoczesny system operacyjny. Nowoczesne systemy operacyjne są wyjaśnione w rozdziale po następnym.
Notatka : System operacyjny Commodore-64 (Kernal) nadal dobrze współpracuje z nowoczesnymi urządzeniami wejścia i wyjścia (nie ze wszystkimi).
Komputer ośmiobitowy
W ośmiobitowym mikrokomputerze, takim jak Commodore 64, informacje są przechowywane, przesyłane i przetwarzane w postaci ośmiobitowych kodów binarnych.
Mapa pamięci
Mapa pamięci to skala, która dzieli cały zakres pamięci na mniejsze zakresy o różnych rozmiarach i pokazuje, co (podprogram i/lub zmienna) należy do jakiego zakresu. Zmienna to etykieta odpowiadająca konkretnemu adresowi pamięci, który ma wartość. Etykiety służą również do identyfikacji początku podprogramów. Ale w tym przypadku są one znane jako nazwy podprogramów. Podprogram można po prostu nazwać procedurą.
Mapa pamięci (układ) z poprzedniego rozdziału nie jest wystarczająco szczegółowa. To całkiem proste. Mapę pamięci komputera Commodore-64 można wyświetlić na trzech poziomach szczegółowości. Na poziomie średniozaawansowanym komputer Commodore-64 ma różne mapy pamięci. Domyślna mapa pamięci komputera Commodore-64 na poziomie średniozaawansowanym to:

Rys. 5.11 Mapa pamięci Commodore-64
W tamtych czasach istniał popularny język komputerowy o nazwie BASIC. Wielu użytkowników komputerów musiało znać pewne minimalne polecenia języka BASIC, takie jak ładowanie programu z dyskietki (dysku) do pamięci, uruchamianie (wykonywanie) programu w pamięci i zamykanie programu. Kiedy program BASIC jest uruchomiony, użytkownik musi wprowadzać dane, linia po linii. To nie jest tak, jak dzisiaj, gdy aplikacja (kilka programów tworzy aplikację) jest napisana w języku wysokiego poziomu z systemem Windows, a użytkownik musi jedynie zmieścić różne dane w wyspecjalizowanych miejscach okna. W niektórych przypadkach użyj myszki, aby wybrać zamówione w przedsprzedaży dane. BASIC był wówczas językiem wysokiego poziomu, ale jest dość zbliżony do języka asemblera.
Zauważ, że większość pamięci jest zajmowana przez BASIC w domyślnej mapie pamięci. BASIC zawiera polecenia (instrukcje), które są wykonywane przez tak zwany interpreter języka BASIC. W rzeczywistości interpreter języka BASIC znajduje się w pamięci ROM od lokalizacji $A000 do lokalizacji $BFFF (włącznie), która rzekomo jest obszarem pamięci RAM. To jest 8 KB, czyli całkiem sporo jak na tamte czasy! Właściwie znajduje się w pamięci ROM w tym miejscu całej pamięci. Ma taki sam rozmiar jak system operacyjny od E000 do $FFFF (włącznie). Programy napisane w języku BASIC również mieszczą się w przedziale od 0200 $ do $BFFF.
Pamięć RAM dla programu w języku asemblera użytkownika wynosi od $C000 do $CFFF, zaledwie 4 kilobajty z 64 kilobajtów. Dlaczego więc używamy lub uczymy się języka asemblera? Nowe i stare systemy operacyjne są oparte na językach asemblerowych. System operacyjny Commodore-64 znajduje się w pamięci ROM, od $E000 do $FFFF. Jest napisany w języku asemblera 65C02 µP (6510 µP). Składa się z podprogramów. Program użytkownika w języku asemblera musi wywoływać te podprogramy, aby móc współdziałać z urządzeniami peryferyjnymi (urządzeniami wejściowymi i wyjściowymi). Zrozumienie systemu operacyjnego Commodore-64 w języku asemblera umożliwia uczniowi zrozumienie systemów operacyjnych szybko i w znacznie mniej żmudny sposób. Ponownie, w tamtych czasach wiele programów użytkownika dla Commodore-64 zostało napisanych w języku BASIC, a nie w języku asemblera. W tamtych czasach języki asemblera były częściej używane przez samych programistów do celów technicznych.
Kernal, pisany jako K-e-r-n-a-l, to system operacyjny Commodore-64. Jest dostarczany z komputerem Commodore-64 w pamięci ROM, a nie na dysku (lub dyskietce). Kernal składa się z podprogramów. Aby uzyskać dostęp do urządzeń peryferyjnych, program użytkownika w języku asemblera (języku maszynowym) musi korzystać z tych podprogramów. Kernal nie powinien być mylony z jądrem, które w nowoczesnych systemach operacyjnych zapisuje się jako K-e-r-n-e-l, chociaż są one prawie tym samym.
Obszar pamięci od $C000 (49,15210) do $CFFF (6324810) wynoszący 4 KB10 pamięci to RAM lub ROM. Jeśli jest to pamięć RAM, służy ona do uzyskiwania dostępu do urządzeń peryferyjnych. Gdy jest to ROM, służy do drukowania znaków na ekranie (monitorze). Oznacza to, że albo znaki są drukowane na ekranie, albo uzyskiwany jest dostęp do urządzeń peryferyjnych za pomocą tej części pamięci. W jednostce systemowej (płycie głównej) znajduje się bank pamięci ROM (znakowej ROM), który w tym celu jest włączany i wyłączany z całej przestrzeni pamięci. Użytkownik może nie zauważyć przełączenia.
Obszar pamięci od 0100 $ (256 10 ) do 01FF (511 10 ) to stos. Jest używany zarówno przez system operacyjny, jak i programy użytkownika. Rolę stosu wyjaśniono w poprzednim rozdziale tego internetowego kursu kariery. Obszar pamięci od 0000 $ (0 10 ) do 00FF (255 10 ) jest używany przez system operacyjny. Przypisano tam wiele wskaźników.
Stół skokowy Kernala
Kernal posiada procedury wywoływane przez program użytkownika. Wraz z pojawieniem się nowych wersji systemu operacyjnego adresy tych procedur uległy zmianie. Oznacza to, że programy użytkownika nie mogły już współpracować z nowymi wersjami systemu operacyjnego. Tak się nie stało, ponieważ Commodore-64 dostarczył tabelę skoków. Tabela skoków to lista 39 wpisów. Każdy wpis w tabeli ma trzy adresy (z wyjątkiem ostatnich 6 bajtów), które nigdy się nie zmieniły nawet przy zmianie wersji systemu operacyjnego.
Pierwszy adres wpisu zawiera instrukcję JSR. Następne dwa adresy składają się ze wskaźnika dwubajtowego. Ten dwubajtowy wskaźnik jest adresem (lub nowym adresem) aktualnej procedury, która wciąż znajduje się w pamięci ROM systemu operacyjnego. Zawartość wskaźnika może się zmienić w nowych wersjach systemu operacyjnego, ale trzy adresy dla każdego wpisu tabeli przeskoku nigdy się nie zmieniają. Rozważmy na przykład adresy $FF81, $FF82 i $FF83. Te trzy adresy służą procedurze inicjalizacji obwodów (rejestrów) ekranu i klawiatury na płycie głównej. Adres $FF81 zawsze zawiera kod operacji (jeden bajt) JSR. Adresy $FF82 i $FF83 mają stary lub nowy adres podprogramu (wciąż w pamięci OS ROM), który ma wykonać inicjalizację. W pewnym momencie adresy $FF82 i $FF83 miały zawartość (adres) $FF5B, która mogła ulec zmianie w następnej wersji systemu operacyjnego. Jednakże adresy $FF81, $FF82 i $FF83 tabeli skoków nigdy się nie zmieniają.
Dla każdego wpisu trzech adresów pierwszy adres z JSR ma etykietę (nazwę). Etykieta dla $FF81 to PCINT. PCINT nigdy się nie zmienia. Tak więc, aby zainicjować rejestry ekranu i klawiatury, programista może po prostu wpisać „JSR PCINT”, co działa dla wszystkich wersji systemu operacyjnego Commodore-64. Lokalizacja (adres początkowy) rzeczywistego podprogramu, np. $FF5B, może zmieniać się w czasie w różnych systemach operacyjnych. Tak, w programie użytkownika korzystającym z systemu operacyjnego ROM biorą udział co najmniej dwie instrukcje JSR. W programie użytkownika znajduje się instrukcja JSR, która przeskakuje do wpisu w tabeli skoków. Z wyjątkiem ostatnich sześciu adresów w tablicy skoków, pierwszy adres wpisu w tablicy skoków zawiera instrukcję JSR. W Kernal niektóre podprogramy mogą wywoływać inne podprogramy.
Tabela skoków Kernala zaczyna się od $FF81 (włącznie) i idzie w górę w grupach po trójki, z wyjątkiem ostatnich sześciu bajtów, które są trzema wskaźnikami z adresami niższych bajtów: $FFFA, $FFFC i $FFFE. Wszystkie procedury ROM OS są kodami wielokrotnego użytku. Użytkownik nie musi więc ich przepisywać.
Schemat blokowy jednostki systemowej Commodore-64
Poniższy diagram jest bardziej szczegółowy niż ten w poprzednim rozdziale:
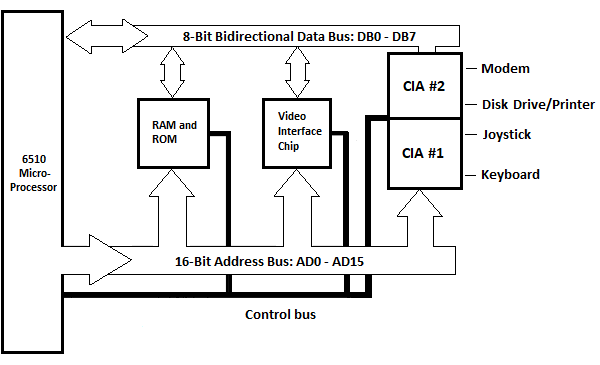
Rys. 5.12 Schemat blokowy jednostki systemowej Commodore_64
ROM i RAM są tutaj pokazane jako jeden blok. Tutaj pokazano układ interfejsu wideo (IC) do przesyłania informacji na ekran, który nie został pokazany w poprzednim rozdziale. Pojedynczy blok urządzeń wejścia/wyjścia, pokazany w poprzednim rozdziale, jest tutaj pokazany jako dwa bloki: CIA nr 1 i CIA nr 2. CIA oznacza złożony adapter interfejsu. Każdy z nich ma dwa równoległe ośmiobitowe porty (nie mylić z portami zewnętrznymi na pionowej powierzchni jednostki systemowej), zwane portem A i portem B. W tej sytuacji CIA jest podłączone do pięciu urządzeń zewnętrznych. Urządzeniami są klawiatura, joystick, napęd dyskowy/drukarka i modem. Drukarka jest podłączona z tyłu napędu dyskowego. Istnieje również obwód urządzenia interfejsu dźwiękowego i obwód programowalnej tablicy logicznej, które nie zostały pokazane.
Mimo to istnieje pamięć ROM znaków, którą można zamienić z obydwoma CIA, gdy postać jest wysyłana na ekran i nie jest ona pokazana na schemacie blokowym.
Adresy RAM od $D000 do $DFFF dla obwodów wejścia/wyjścia w przypadku braku znakowej pamięci ROM mają następującą szczegółową mapę pamięci:
| Tabela 5.11 Szczegółowa mapa pamięci od $D000 do $DFFF |
||
|---|---|---|
| Zakres podadresów | Okrążenie | Rozmiar (w bajtach) |
| D000 – D3FF | VIC (kontroler interfejsu wideo (chip)) | 1 tys |
| D400 – D7FF | SID (obwód dźwiękowy) | 1 tys |
| D800 – DBFF | Kolorowa pamięć RAM | 1 tys. przekąsek |
| DC00 – DCFF | CIA nr 1 (klawiatura, joystick) | 256 |
| DD00 – DDFF | CIA nr 2 (magistrala szeregowa, port użytkownika/RS-232) | 256 |
| DE00 – DEF | Otwórz gniazdo we/wy nr 1 | 256 |
| DF00 – DFFF | Otwórz gniazdo we/wy nr 2 | 256 |
5.2 Dwa złożone adaptery interfejsów
W jednostce systemowej Commodore-64 znajdują się dwa szczególne układy scalone (IC), a każdy z nich nazywany jest adapterem złożonego interfejsu. Te dwa chipy służą do łączenia klawiatury i innych urządzeń peryferyjnych z mikroprocesorem. Z wyjątkiem układu VIC i ekranu, wszystkie sygnały wejściowe/wyjściowe pomiędzy mikroprocesorem a urządzeniami peryferyjnymi przechodzą przez te dwa układy scalone. W przypadku Commodore-64 nie ma bezpośredniej komunikacji pomiędzy pamięcią a jakimkolwiek urządzeniem peryferyjnym. Komunikacja między pamięcią a dowolnymi urządzeniami peryferyjnymi odbywa się za pośrednictwem akumulatora mikroprocesorowego, a jednym z nich są adaptery CIA (IC). Komponenty IC nazywane są CIA nr 1 i CIA nr 2. CIA oznacza złożony adapter interfejsu.
Każda CIA ma 16 rejestrów. Z wyjątkiem rejestrów timerów/liczników w CIA, każdy rejestr ma szerokość 8 bitów i adres pamięci. Adresy rejestrów pamięci dla CIA #1 pochodzą z $DC00 (56320 10 ) na $DC0F (56335 10 ). Adresy rejestrów pamięci dla CIA #2 pochodzą z $DD00 (56576 10 ) na $DD0F (56591 10 ). Chociaż rejestry te nie znajdują się w pamięci układu scalonego, są częścią pamięci. Na mapie pamięci pośredniej obszar we/wy od $D000 do $DFFF obejmuje adresy CIA od $DC00 do $DC0F i od $DD00 do $DD0F. Większość obszaru pamięci RAM I/O od $D000 do $DFFF można zamienić na bank pamięci znakowej ROM dla znaków ekranowych. Dlatego też, gdy znaki są przesyłane na ekran, urządzenia peryferyjne nie mogą działać; chociaż użytkownik może tego nie zauważyć, ponieważ zamiana tam i z powrotem jest szybka.
W CIA nr 1 istnieją dwa rejestry zwane Portem A i Portem B. Ich adresy to odpowiednio $DC00 i $DC01. W CIA nr 2 są też dwa rejestry, zwane Portem A i Portem B. Oczywiście ich adresy są różne; są to odpowiednio $DD00 i $DD01.
Port A lub Port B w dowolnym CIA jest portem równoległym. Oznacza to, że może wysyłać dane do urządzenia peryferyjnego w ośmiu bitach jednocześnie lub odbierać dane z mikroprocesora w ośmiu bitach jednocześnie.
Z portem A lub portem B powiązany jest rejestr kierunku danych (DDR). Rejestr kierunku danych dla portu A CIA nr 1 (DDRA1) znajduje się w lokalizacji bajtów pamięci $DC02. Rejestr kierunku danych dla portu B CIA nr 1 (DDRB1) znajduje się w lokalizacji bajtów pamięci $DC03. Rejestr kierunku danych dla portu A CIA nr 2 (DDRA2) znajduje się w lokalizacji bajtów pamięci $DD02. Rejestr kierunku danych dla portu B CIA nr 2 (DDRB2) znajduje się w lokalizacji bajtów pamięci $DD03.
Teraz każdy bit portu A lub portu B może być ustawiony przez odpowiedni rejestr kierunku danych jako wejście lub wyjście. Wejście oznacza, że informacja przechodzi z urządzenia peryferyjnego do mikroprocesora za pośrednictwem CIA. Dane wyjściowe oznaczają, że informacja przechodzi z mikroprocesora do urządzenia peryferyjnego za pośrednictwem CIA.
Jeśli ma zostać wprowadzona komórka portu (rejestru), odpowiedni bit w rejestrze kierunku danych wynosi 0. Jeśli ma zostać wyprowadzona komórka portu (rejestru), odpowiedni bit w rejestrze kierunku danych wynosi 1. W większości przypadków wszystkie 8 bitów portu zaprogramowano jako wejście lub wyjście. Kiedy komputer jest włączony, port A jest zaprogramowany na wyjście, a port B na wejście. Poniższy kod sprawia, że port A CIA nr 1 jest wyjściem, a port B CIA nr 1 wejściem:
LDA#$FF
STA DDRA1 ; $DC00 jest kierowany przez $DC02
LDA#00 dolarów
STA DDRB1 ; $DC01 jest kierowany przez $DC03
DDRA1 to etykieta (nazwa zmiennej) lokalizacji bajtu pamięci $DC02, a DDRB1 to etykieta (nazwa zmiennej) lokalizacji bajtu pamięci $DC03. Pierwsza instrukcja ładuje 11111111 do akumulatora µP. Druga instrukcja kopiuje to do rejestru kierunku danych portu A CIA nr. 1. Trzecia instrukcja ładuje 00000000 do akumulatora µP. Czwarta instrukcja kopiuje to do rejestru kierunku danych portu B CIA nr. 1. Ten kod znajduje się w jednym z podprogramów systemu operacyjnego, który dokonuje tej inicjalizacji podczas włączania komputera.
Każda CIA ma linię żądania obsługi przerwania do mikroprocesora. Ten z CIA nr 1 trafia do Przerwanie pin µP. Ten z CIA nr 2 trafia do NMI pin µP. Zapamietaj to NMI ma wyższy priorytet niż Przerwanie .
5.3 Programowanie w języku asemblera klawiatury
Istnieją tylko trzy możliwe przerwania dla Commodore-64: Przerwanie , BRK i NMI . Wskaźnik tabeli skoków dla Przerwanie znajduje się pod adresami $FFFE i $FFFF w ROM (systemie operacyjnym), co odpowiada podprogramowi znajdującemu się nadal w systemie operacyjnym (ROM). Wskaźnik tabeli skoków dla BRK znajduje się pod adresami $FFFC i $FFFD w systemie operacyjnym, co odpowiada podprogramowi znajdującemu się nadal w systemie operacyjnym (ROM). Wskaźnik tabeli skoków dla NMI znajduje się pod adresami $FFFA i $FFFB w systemie operacyjnym, co odpowiada podprogramowi znajdującemu się nadal w systemie operacyjnym (ROM). Dla Przerwanie , w rzeczywistości istnieją dwa podprogramy. Zatem przerwanie programowe BRK (instrukcja) ma swój własny wskaźnik tablicy skoków. Wskaźnik tabeli skoków dla Przerwanie prowadzi do kodu, który decyduje, czy zaangażowane jest przerwanie sprzętowe, czy przerwanie programowe. Jeśli jest to przerwanie sprzętowe, procedura dla Przerwanie jest nazywany. Jeśli jest to przerwanie programowe (BRK), wywoływana jest procedura dla BRK. W jednej z wersji systemu operacyjnego podprogram dla Przerwanie wynosi $EA31, a podprogram dla BRK wynosi $FE66. Adresy te są poniżej FF81 $, więc nie są to wpisy w tabeli przeskoków i mogą się zmieniać w zależności od wersji systemu operacyjnego. Istnieją trzy procedury interesujące w tym temacie: ta, która sprawdza, czy jest to naciśnięty klawisz, czy BRK, ta, która kosztuje FE43 $ i ta, która może również zmieniać się w zależności od wersji systemu operacyjnego.
Komputer Commodore-64 z wyglądu przypomina ogromną maszynę do pisania (od góry) bez sekcji drukującej (głowicy i papieru). Klawiatura jest podłączona do CIA nr 1. Domyślnie CIA nr 1 samodzielnie skanuje klawiaturę co 1/60 sekundy, bez żadnej ingerencji w programowanie. Zatem co 1/60 sekundy CIA nr 1 wysyła wiadomość Przerwanie do µP. Tam jest tylko jeden Przerwanie przypnij do µP, które pochodzi tylko z CIA nr 1. Jeden pin wejściowy NMI µP, która różni się od Przerwanie , pochodzi wyłącznie z CIA nr 2 (patrz poniższa ilustracja). BRK jest w rzeczywistości instrukcją języka asemblera zakodowaną w programie użytkownika.
Zatem co 1/60 sekundy Przerwanie wywoływana jest procedura wskazywana przez $FFFE i $FFFF. Procedura sprawdza, czy naciśnięto klawisz lub napotkano instrukcję BRK. Jeśli klawisz zostanie naciśnięty, wywoływana jest procedura obsługująca naciśnięcie klawisza. Jeśli jest to instrukcja BRK, wywoływana jest procedura obsługująca BRK. Jeśli tak nie jest, nic się nie dzieje. Może się to nie zdarzyć, ale CIA nr 1 wysyła Przerwanie do µP co 1/60 sekundy.
Kolejka klawiatury, znana również jako bufor klawiatury, to zakres lokalizacji bajtów RAM od 0277 do 0280 dolarów włącznie; W sumie 1010 bajtów. Jest to bufor typu „pierwsze weszło, pierwsze wyszło”. Oznacza to, że pierwsza postać, która przyjdzie, jako pierwsza opuści. Znak zachodnioeuropejski zajmuje jeden bajt.
Tak więc, chociaż program nie zużywa żadnego znaku po naciśnięciu klawisza, kod klawisza trafia do tego bufora (kolejki). Bufor jest zapełniany, aż będzie dziesięć znaków. Żaden znak naciśnięty po dziesiątym znaku nie jest rejestrowany. Jest ignorowany, dopóki przynajmniej jeden znak nie zostanie pobrany (zużyty) z kolejki. Tabela skoków zawiera wpis dla podprogramu, który pobiera pierwszy znak z kolejki do mikroprocesora. Oznacza to, że pobiera pierwszy znak, który trafia do kolejki i umieszcza go w akumulatorze µP. Podprogram tabeli skoków służący do tego nazywa się GETIN (od Get-In). Pierwszy bajt trzybajtowego wpisu w tablicy skoków jest oznaczony jako GETIN (adres $FFE4). Następne dwa bajty to wskaźnik (adres) wskazujący rzeczywistą procedurę w pamięci ROM (OS). Wywołanie tej procedury jest obowiązkiem programisty. W przeciwnym razie bufor klawiatury pozostanie pełny, a wszystkie ostatnio wciśnięte klawisze zostaną zignorowane. Wartość trafiająca do akumulatora jest odpowiednią wartością klucza ASCII.
W jaki sposób kody kluczy trafiają do kolejki? Istnieje procedura tabeli przeskoków o nazwie SCNKEY (dla klawisza skanowania). Ta procedura może być wywoływana zarówno przez oprogramowanie, jak i sprzęt. W tym przypadku jest on wywoływany przez obwód elektroniczny (fizyczny) w mikroprocesorze, gdy pojawia się sygnał elektryczny Przerwanie jest niski. W tym internetowym kursie kariery nie opisano, jak dokładnie to się robi.
Kod umożliwiający pobranie pierwszego kodu klawisza z bufora klawiatury do akumulatora A to tylko jedna linia:
GETIN
Jeśli bufor klawiatury jest pusty, w akumulatorze umieszczane jest 00 $. Pamiętaj, że kod ASCII oznaczający zero to nie 00 $; to jest 30 dolarów. 00 $ oznacza Null. W programie może zaistnieć moment, w którym program będzie musiał poczekać na naciśnięcie klawisza. Kod do tego to:
CZEKAJ JSR GETIN
CMP # 00 dolarów
ŻABA CZEKAJ
W pierwszej linii „WAIT” to etykieta identyfikująca adres RAM, w którym umieszczana jest (wpisana) instrukcja JSR. GETIN jest także adresem. Jest to adres pierwszego z odpowiednich trzech bajtów tablicy skoków. Wpis GETIN, podobnie jak wszystkie wpisy w tablicy skoków (z wyjątkiem trzech ostatnich), składa się z trzech bajtów. Pierwszym bajtem wpisu jest instrukcja JSR. Następne dwa bajty to adres treści aktualnego podprogramu GETIN, który nadal znajduje się w pamięci ROM (OS), ale poniżej tabeli skoków. Zatem wpis mówi, aby przejść do podprogramu GETIN. Jeżeli kolejka klawiatury nie jest pusta, GETIN umieszcza w akumulatorze kod klucza ASCII kolejki First-In-First-Out. Jeśli kolejka jest pusta, do akumulatora zostaje wrzucona wartość Null (00 $).
Druga instrukcja porównuje wartość akumulatora z 00 $. Jeśli wynosi 00 $, oznacza to, że kolejka klawiatury jest pusta, a instrukcja CMP wysyła 1 do flagi Z rejestru stanu procesora (zwanego po prostu rejestrem stanu). Jeśli wartość w A nie jest równa 00, instrukcja CMP wysyła 0 do flagi Z rejestru stanu.
Trzecia instrukcja „BEQ WAIT” odsyła program z powrotem do pierwszej instrukcji, jeśli flaga Z rejestru stanu wynosi 1. Pierwsza, druga i trzecia instrukcja są wykonywane wielokrotnie w kolejności aż do naciśnięcia klawisza na klawiaturze . Jeżeli żaden klawisz nie zostanie wciśnięty, cykl będzie się powtarzał w nieskończoność. Taki segment kodu jest zwykle zapisywany z segmentem kodu taktowania, który po pewnym czasie opuszcza pętlę, jeśli klawisz nie jest nigdy naciśnięty (patrz poniższe omówienie).
Notatka : Klawiatura jest domyślnym urządzeniem wejściowym, a ekran domyślnym urządzeniem wyjściowym.
5.4 Kanał, numer urządzenia i numer pliku logicznego
Urządzenia peryferyjne użyte w tym rozdziale do wyjaśnienia systemu operacyjnego Commodore-64 to klawiatura, ekran (monitor), napęd dyskowy z dyskietką, drukarka i modem podłączony przez interfejs RS-232C. Aby komunikacja pomiędzy tymi urządzeniami a jednostką systemową (mikroprocesorem i pamięcią) mogła nastąpić, konieczne jest ustanowienie kanału.
Kanał składa się z bufora, numeru urządzenia, numeru pliku logicznego i opcjonalnie adresu dodatkowego. Wyjaśnienie tych terminów jest następujące:
Bufor
Zauważ z poprzedniej sekcji, że po naciśnięciu klawisza jego kod musi przejść do lokalizacji bajtowej w pamięci RAM w serii dziesięciu kolejnych lokalizacji. Ta seria dziesięciu lokalizacji to bufor klawiatury. Każde urządzenie wejściowe lub wyjściowe (peryferyjne) ma szereg kolejnych lokalizacji w pamięci RAM zwanych buforem.
Numer urządzenia
W przypadku Commodore-64 każde urządzenie peryferyjne otrzymuje numer urządzenia. Poniższa tabela przedstawia różne urządzenia i ich numery:
| Tabela 5.41 Numery urządzeń Commodore 64 i ich urządzenia |
|
|---|---|
| Numer | Urządzenie |
| 0 | Klawiatura |
| 1 | Napęd taśmowy |
| 2 | Interfejs RS 232C do m.in. modem |
| 3 | Ekran |
| 4 | Drukarka nr 1 |
| 5 | Drukarka nr 2 |
| 6 | Ploter nr 1 |
| 7 | Ploter nr 2 |
| 8 | Napęd |
| 9 ¦ ¦ ¦ 30 |
Od 8 (włącznie) do 22 dodatkowych urządzeń pamięci masowej |
Istnieją dwa typy portów w komputerze. Jeden typ jest zewnętrzny, na pionowej powierzchni jednostki systemowej. Drugi typ jest wewnętrzny. Ten wewnętrzny port to rejestr. Commodore-64 ma cztery porty wewnętrzne: port A i port B dla CIA 1 oraz port A i Port B dla CIA 2. Commodore-64 ma jeden port zewnętrzny, nazywany portem szeregowym. Urządzenia o numerze 3 w górę podłącza się do portu szeregowego. Są one połączone w sposób łańcuchowy (jeden połączony za drugim), a każdy z nich można rozpoznać po numerze urządzenia. Urządzenia o numerze od 8 wzwyż to zazwyczaj urządzenia pamięci masowej.
Notatka : Domyślnym urządzeniem wejściowym jest klawiatura o numerze urządzenia 0. Domyślnym urządzeniem wyjściowym jest ekran o numerze urządzenia 3.
Logiczny numer pliku
Logiczny numer pliku to numer nadawany urządzeniu (urządzeniu peryferyjnemu) w kolejności, w jakiej są one otwierane w celu uzyskania dostępu. Wynoszą one od 010 do 255 10 .
Adres dodatkowy
Wyobraź sobie, że na dysku otwierane są dwa pliki (lub więcej niż jeden plik). Aby rozróżnić te dwa pliki, używane są adresy dodatkowe. Adresy dodatkowe to liczby, które różnią się w zależności od urządzenia. Znaczenie liczby 3 jako adresu dodatkowego dla drukarki różni się od znaczenia liczby 3 jako adresu dodatkowego dla stacji dysków. Znaczenie zależy od funkcji, takich jak otwarcie pliku do odczytu lub otwarcie pliku do zapisu. Możliwe liczby wtórne zaczynają się od 0 10 do 15 10 dla każdego urządzenia. W przypadku wielu urządzeń liczba 15 służy do wysyłania poleceń.
Notatka : Numer urządzenia jest również nazywany adresem urządzenia, a numer dodatkowy jest również nazywany adresem dodatkowym.
Identyfikacja celu peryferyjnego
W przypadku domyślnej mapy pamięci Commodore adresy pamięci od $0200 do $02FF (strona 2) są używane wyłącznie przez system operacyjny w pamięci ROM (Kernal), a nie przez system operacyjny i język BASIC. Chociaż BASIC może nadal korzystać z lokalizacji poprzez system operacyjny ROM.
Modem i drukarka to dwa różne urządzenia peryferyjne. Jeśli z dysku zostaną otwarte dwa pliki, będą to dwa różne cele. W przypadku domyślnej mapy pamięci istnieją trzy kolejne tabele (listy), które można postrzegać jako jedną dużą tabelę. W tych trzech tabelach znajdują się zależności pomiędzy numerami plików logicznych, numerami urządzeń i adresami dodatkowymi. Dzięki temu można zidentyfikować konkretny kanał lub cel wejścia/wyjścia. Trzy tabele nazywane są tabelami plików. Adresy pamięci RAM i ich zawartość to:
$0259 — $0262: Tabela z etykietą LAT zawierającą maksymalnie dziesięć aktywnych numerów plików logicznych.
$0263 — $026C: Tabela z etykietą, FAT, zawierającą maksymalnie dziesięć odpowiednich numerów urządzeń.
$026D — $0276: Tabela z etykietą, SAT, dziesięciu odpowiednich adresów dodatkowych.
Tutaj „-” oznacza „do”, a liczba zajmuje jeden bajt.
Czytelnik może zapytać: „Dlaczego bufor dla każdego urządzenia nie jest uwzględniany przy identyfikacji kanału?” Cóż, odpowiedź jest taka, że w przypadku Commodore-64 każde urządzenie zewnętrzne (peryferyjne) ma stałą serię bajtów w pamięci RAM (mapa pamięci). Bez otwartego kanału ich pozycje nadal znajdują się w pamięci. Na przykład bufor klawiatury ma stałą wartość od 0277 do 0280 USD (włącznie) dla domyślnej mapy pamięci.
Podprogramy Kernala SETLFS i SETNAM
SETLFS i SETNAM to procedury Kernala. Kanał może być postrzegany jako plik logiczny. Aby kanał został otwarty, należy podać numer pliku logicznego, numer urządzenia i opcjonalny adres dodatkowy. Może być również potrzebna opcjonalna nazwa pliku (tekst). Procedura SETLFS konfiguruje numer pliku logicznego, numer urządzenia i opcjonalny adres dodatkowy. Liczby te umieszczono w odpowiednich tabelach. Procedura SETNAM ustawia ciąg znaków dla pliku, który może być obowiązkowy dla jednego kanału i opcjonalny dla innego kanału. Składa się ze wskaźnika (adresu dwubajtowego) w pamięci. Wskaźnik wskazuje początek ciągu (nazwy), który może znajdować się w innym miejscu pamięci. Nazwa ciągu zaczyna się od bajtu o długości łańcucha, po którym następuje tekst (nazwa). Nazwa może mieć maksymalnie szesnaście bajtów (długa).
Aby wywołać procedurę SETLFS, program użytkownika musi wykonać skok (JSR) pod adres $FFBA tablicy skoków systemu operacyjnego w pamięci ROM dla domyślnej mapy pamięci. Pamiętaj, że z wyjątkiem ostatnich sześciu bajtów tabeli skoków, każdy wpis składa się z trzech bajtów. Pierwszy bajt to instrukcja JSR, która następnie przeskakuje do podprogramu, rozpoczynając od adresu w kolejnych dwóch bajtach. Aby wywołać procedurę SETNAM, program użytkownika musi wykonać skok (JSR) pod adres $FFBD tablicy skoków systemu operacyjnego w pamięci ROM. Użycie tych dwóch procedur pokazano w poniższym omówieniu.
5.5 Otwieranie kanału, otwieranie pliku logicznego, zamykanie pliku logicznego i zamykanie wszystkich kanałów we/wy
Kanał składa się z bufora pamięci, logicznego numeru pliku, numeru urządzenia (adresu urządzenia) i opcjonalnego adresu dodatkowego (liczby). Plik logiczny (abstrakcja), który jest identyfikowany przez numer pliku logicznego, może odnosić się do urządzenia peryferyjnego, takiego jak drukarka, modem, napęd dyskowy itp. Każde z tych różnych urządzeń powinno mieć różne numery plików logicznych. Na dysku znajduje się wiele plików. Plik logiczny może również odnosić się do konkretnego pliku na dysku. Ten konkretny plik ma również logiczny numer pliku, który różni się od numerów urządzeń peryferyjnych, takich jak drukarka czy modem. Numer logiczny pliku nadawany jest przez programistę. Może to być dowolna liczba z zakresu od 010 (00 USD) do 25510 ($FF).
Procedura OS SETLFS
Procedura OS SETLFS, do której można uzyskać dostęp poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFBA, konfiguruje kanał. Musi umieścić logiczny numer pliku w tabeli plików, czyli LAT (0259 $ - 0262 $). Musi umieścić odpowiedni numer urządzenia w tabeli plików, czyli FAT (0263 $ – 026C). Jeśli dostęp do pliku (urządzenia) wymaga numeru dodatkowego, należy umieścić odpowiedni adres dodatkowy (numer) w tabeli plików, czyli SAT (026D – 0276 USD).
Aby działać, podprogram SETLFS musi uzyskać numer pliku logicznego z akumulatora µP; musi uzyskać numer urządzenia z rejestru µP X. Jeśli kanał tego potrzebuje, musi uzyskać adres wtórny z rejestru µP Y.
O numerze logicznym pliku decyduje programista. Logiczne numery plików odnoszące się do różnych urządzeń są różne. Teraz, przed wywołaniem procedury SETLFS, programista powinien umieścić numer pliku logicznego w akumulatorze µP. Numer urządzenia odczytuje się z tabeli (dokumentu) takiej jak w tabeli 5.41. Programista powinien także wpisać numer urządzenia do rejestru µP X. Dostawca urządzenia takiego jak drukarka, napęd dyskowy itp. podaje możliwe adresy dodatkowe i ich znaczenie dla urządzenia. Jeśli kanał potrzebuje adresu dodatkowego, programista musi go uzyskać z dokumentu dołączonego do urządzenia (urządzenia peryferyjnego). Jeżeli konieczny jest adres wtórny (numer), programista musi umieścić go w rejestrze µP Y przed wywołaniem podprogramu SETLFS. Jeśli nie jest potrzebny adres dodatkowy, programista musi umieścić numer $FF w rejestrze µP Y przed wywołaniem podprogramu SETLFS.
Podprogram SETLFS jest wywoływany bez żadnych argumentów. Jego argumenty znajdują się już w trzech rejestrach 6502 µP. Po umieszczeniu odpowiednich liczb w rejestrach procedura jest wywoływana w programie po prostu z następującymi informacjami w osobnej linii:
JSR rozlicza
Procedura odpowiednio umieszcza różne liczby w swoich tabelach plików.
Procedura OS SETNAM
Dostęp do procedury OS SETNAM można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFBD. Nie wszystkie miejsca docelowe mają nazwy plików. W przypadku tych, które mają miejsca docelowe (takie jak pliki na dysku), należy ustawić nazwę pliku. Załóżmy, że nazwa pliku to „mydocum” i składa się z 7 bajtów bez cudzysłowów. Załóżmy, że ta nazwa znajduje się w lokalizacjach $C101 do $C107 (włącznie), a długość $07 znajduje się w lokalizacji $C100. Adres początkowy znaków ciągu to $C101. Dolny bajt adresu początkowego to $01, a wyższy bajt to $C1.
Przed wywołaniem procedury SETNAM programista musi umieścić liczbę $07 (długość łańcucha) w akumulatorze µP. Dolny bajt adresu początkowego łańcucha $01 jest umieszczany w rejestrze µP X. Wyższy bajt adresu początkowego łańcucha $C1 jest umieszczany w rejestrze µP Y. Podprogram jest wywoływany w prosty sposób za pomocą następujących poleceń:
JSR SETNAM
Procedura SETNAM kojarzy wartości z trzech rejestrów z kanałem. Następnie wartości nie muszą pozostać w rejestrach. Jeśli kanał nie potrzebuje nazwy pliku, programista musi włożyć 00 $ do akumulatora µP. W tym przypadku ignorowane są wartości znajdujące się w rejestrach X i Y.
Procedura OS OTWARTA
Dostęp do procedury OS OPEN uzyskuje się poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFC0. Ta procedura wykorzystuje logiczny numer pliku, numer urządzenia (i bufor), możliwy adres dodatkowy i możliwą nazwę pliku, aby zapewnić połączenie między komputerem Commodore a plikiem w urządzeniu zewnętrznym lub samym urządzeniem zewnętrznym.
Ta procedura, podobnie jak wszystkie inne procedury ROM Commodore OS, nie przyjmuje żadnych argumentów. Chociaż wykorzystuje rejestry µP, żaden z rejestrów nie musiał być wstępnie ładowany argumentami (wartościami). Aby to zakodować, po prostu wpisz następujące polecenie po wywołaniu SETLFS i SETNAM:
JSR OTWARTE
W procedurze OPEN mogą wystąpić błędy. Na przykład plik może nie zostać znaleziony do odczytu. Gdy wystąpi błąd, procedura kończy się niepowodzeniem i umieszcza odpowiedni numer błędu w akumulatorze µP oraz ustawia flagę przeniesienia (na 1) rejestru stanu µP. W poniższej tabeli przedstawiono numery błędów i ich znaczenie:
| Tabela 5.51 Numery błędów jądra i ich znaczenie dla procedury OS ROM OPEN |
||
|---|---|---|
| Numer błędu | Opis | Przykład |
| 1 | ZBYT DUŻO PLIKÓW | OPEN, gdy otwartych jest już dziesięć plików |
| 2 | PLIK OTWARTY | OTWARTE 1,3: OTWARTE 1,4 |
| 3 | PLIK NIE OTWARTY | PRINT#5 bez OPEN |
| 4 | NIE ZNALEZIONO PLIKU | WCZYTAJ „NIEISTNIEJĄCE”, 8 |
| 5 | URZĄDZENIE NIE OBECNE | OTWÓRZ 11,11: DRUKUJ#11 |
| 6 | NIE PLIK WEJŚCIOWY | OTWÓRZ „SEQ, S, W”: GET#8,X$ |
| 7 | NIE PLIK WYJŚCIOWY | OTWÓRZ 1,0: DRUKUJ#1 |
| 8 | BRAKUJĄCA NAZWA PLIKU | ŁADUJ „”, 8 |
| 9 | NIELEGALNY NR URZĄDZENIA | ZAŁADUJ „PROGRAM”,3 |
Tabela ta jest przedstawiona w sposób, który czytelnik prawdopodobnie zobaczy w wielu innych miejscach.
Procedura OS CHKIN
Dostęp do procedury OS CHKIN można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFC6. Po otwarciu pliku (pliku logicznego) należy zdecydować, czy otwarcie ma służyć wejściu, czy wyjściu. Procedura CHKIN powoduje otwarcie kanału wejściowego. Ta procedura wymaga odczytania numeru pliku logicznego z rejestru µP X. Zatem programista musi umieścić logiczny numer pliku w rejestrze X przed wywołaniem tej procedury. Nazywa się to po prostu:
JSR CHKIN
Procedura CHKOUT systemu operacyjnego
Dostęp do procedury OS CHKOUT można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFC9. Po otwarciu pliku (pliku logicznego) należy zdecydować, czy otwarcie ma służyć wejściu, czy wyjściu. Procedura CHKOUT sprawia, że otwarcie staje się kanałem wyjściowym. Ta procedura wymaga odczytania numeru pliku logicznego z rejestru µP X. Zatem programista musi umieścić logiczny numer pliku w rejestrze X przed wywołaniem tej procedury. Nazywa się to po prostu:
CHKOUT JSR
Procedura ZAMKNIĘCIA systemu operacyjnego
Dostęp do procedury OS CLOSE uzyskuje się poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFC3. Po otwarciu pliku logicznego i przesłaniu bajtów plik logiczny musi zostać zamknięty. Zamknięcie pliku logicznego zwalnia bufor w jednostce systemowej, który może zostać wykorzystany przez inny plik logiczny, który ma jeszcze zostać otwarty. Odpowiednie parametry w trzech tabelach plików również zostaną usunięte. Lokalizacja pamięci RAM dla liczby otwartych plików jest zmniejszana o 1.
Po włączeniu zasilania komputera następuje reset sprzętowy mikroprocesora i innych głównych układów (układów scalonych) na płycie głównej. Następnie następuje inicjalizacja niektórych lokalizacji pamięci RAM i niektórych rejestrów w niektórych układach na płycie głównej. W procesie inicjalizacji bajtowa lokalizacja adresu $0098 na stronie zerowej jest podawana za pomocą etykiety NFILES lub LDTND, w zależności od wersji systemu operacyjnego. Podczas pracy komputera ta jednobajtowa lokalizacja składająca się z 8 bitów przechowuje liczbę otwieranych plików logicznych oraz indeks adresu początkowego kolejnych trzech tablic plików. Innymi słowy, ten bajt zawiera liczbę otwartych plików, która jest zmniejszana o 1, gdy plik logiczny jest zamykany. Po zamknięciu pliku logicznego dostęp do urządzenia końcowego (docelowego) lub rzeczywistego pliku na dysku nie jest już możliwy.
Aby zamknąć plik logiczny programista musi umieścić numer pliku logicznego w akumulatorze µP. Jest to ten sam logiczny numer pliku, który jest używany do otwierania pliku. Procedura CLOSE potrzebuje tego, aby zamknąć ten konkretny plik. Podobnie jak inne procedury OS ROM, procedura CLOSE nie przyjmuje argumentu, chociaż wartość używana z akumulatora jest w pewnym sensie argumentem. Linia instrukcji języka asemblera wygląda po prostu:
JSR ZAMKNIĘTE
Niestandardowe lub predefiniowane podprogramy (procedury) języka asemblera 6502 nie przyjmują argumentów. Jednakże argumenty pojawiają się nieformalnie poprzez umieszczenie wartości, których będzie używał podprogram, w rejestrach mikroprocesora.
Procedura CLRCHN
Dostęp do procedury OS CLRCHN można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM w $FFCC. CLRCHN oznacza CLeaR CHanneL. Kiedy plik logiczny jest zamykany, jego parametry takie jak numer pliku logicznego, numer urządzenia i ewentualny adres dodatkowy są usuwane. Zatem kanał dla pliku logicznego jest wyczyszczony.
W instrukcji jest napisane, że procedura OS CLRCHN czyści wszystkie otwarte kanały i przywraca domyślne numery urządzeń oraz inne wartości domyślne. Czy to oznacza, że można zmienić numer urządzenia peryferyjnego? Cóż, nie do końca. Podczas inicjalizacji systemu operacyjnego lokalizacja bajtu adresu $0099 jest podawana wraz z etykietą DFLTI, która przechowuje bieżący numer urządzenia wejściowego podczas pracy komputera. Commodore-64 może uzyskać dostęp tylko do jednego urządzenia peryferyjnego na raz. Podczas inicjalizacji systemu operacyjnego lokalizacja bajtu adresu $009A jest podawana wraz z etykietą DFLTO, która przechowuje bieżący numer urządzenia wyjściowego podczas pracy komputera.
Po wywołaniu podprogram CLRCHN ustawia zmienną DFLTI na 0 (00 $), co jest domyślnym numerem urządzenia wejściowego (klawiatury). Ustawia zmienną DFLTO na 3 (03 $), która jest domyślnym numerem urządzenia wyjściowego (ekranu). Inne zmienne numeru urządzenia są resetowane w podobny sposób. Takie jest znaczenie resetowania (lub przywracania) urządzeń wejścia/wyjścia do normalnego stanu (wartości domyślne).
Instrukcja Commodore-64 mówi, że po wywołaniu procedury CLRCHN otwarte pliki logiczne pozostają otwarte i nadal mogą przesyłać bajty (dane). Oznacza to, że procedura CLRCHN nie usuwa odpowiednich wpisów w tablicach plików. Nazwa CLRCHN jest raczej niejednoznaczna ze względu na swoje znaczenie.
5.6 Wysyłanie postaci na ekran
Główny układ scalony (IC) obsługujący wyświetlanie znaków i grafiki na ekranie nazywa się kontrolerem interfejsu wideo (chipem), który w Commodore-64 jest w skrócie VIC (właściwie VIC II dla VIC wersja 2). Aby informacja (wartości) trafiła na ekran, musi przejść przez VIC II, zanim dotrze na ekran.
Ekran składa się z 25 wierszy i 40 kolumn komórek znakowych. Daje to 40 x 25 = 1000 znaków, które można wyświetlić na ekranie. VIC II odczytuje odpowiednio 1000 kolejnych bajtów pamięci RAM dla znaków. Łącznie te 1000 lokalizacji nazywa się pamięcią ekranu. To, co trafia do tych 1000 lokalizacji, to kody znaków. W przypadku Commodore-64 kody znaków różnią się od kodów ASCII.
Kod znaku nie jest wzorcem znaków. Istnieje również tak zwana pamięć ROM znakowa. Znakowa pamięć ROM składa się z różnego rodzaju wzorców znaków, z których część odpowiada wzorom znaków na klawiaturze. Znakowa pamięć ROM różni się od pamięci ekranu. Gdy znak ma być wyświetlony na ekranie, kod znaku wysyłany jest na pozycję spośród 1000 pozycji w pamięci ekranu. Stamtąd wybierany jest odpowiedni wzór ze znaku ROM, który ma zostać wyświetlony na ekranie. Wybór prawidłowego wzorca w znakowej pamięci ROM z kodu znaku odbywa się za pomocą VIC II (sprzęt).
Wiele lokalizacji pamięci pomiędzy $D000 a $DFFF ma dwa cele: są używane do obsługi operacji wejścia/wyjścia inne niż ekran lub używane jako znakowa pamięć ROM na ekranie. Dotyczy to dwóch bloków pamięci. Jeden to RAM, a drugi to ROM dla znakowej pamięci ROM. Zamiana banków w celu obsługi wejścia/wyjścia lub wzorców znaków (znakowa pamięć ROM) odbywa się za pomocą oprogramowania (procedura systemu operacyjnego w pamięci ROM od $F000 do $FFFF).
Notatka : VIC posiada rejestry adresowane adresami przestrzeni pamięci z zakresu $D000 i $DFFF.
Procedura CHROUT
Dostęp do procedury OS CHROUT można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFD2. Ta procedura po wywołaniu pobiera bajt, który programista umieścił w akumulatorze µP i wypisuje na ekranie, na którym znajduje się kursor. Segment kodu, w którym drukowany jest na przykład znak „E”, to:
LDA #05 dolarów
CHROUT
0516 nie jest kodem ASCII dla „E”. Commodore-64 ma własne kody znaków na ekranie, gdzie 05 oznacza „E”. Numer #$05 jest umieszczany w pamięci ekranu, zanim VIC wyśle go na ekran. Te dwie linie kodujące powinny pojawić się po skonfigurowaniu kanału, otwarciu pliku logicznego i wywołaniu procedury CHKOUT w celu uzyskania wyniku. Pełny kod to:
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#$03; numer urządzenia dla ekranu to 03 USD
LDY #$FF ; brak adresu dodatkowego
JSR SETLFS ; skonfiguruj kanał prawidłowo
; nie SETNAM, ponieważ ekran nie potrzebuje nazwy
;
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wyjścia
LDX#40 dolarów; logiczny numer pliku
CHKOUT JSR
;
; Wyprowadź znak na ekran
LDA #05 dolarów
JSR CHROUT
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
Otwór należy zamknąć przed uruchomieniem kolejnego programu. Załóżmy, że użytkownik komputera wpisuje znak na klawiaturze w oczekiwanym momencie. Poniższy program wypisuje znak z klawiatury na ekran:
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#$03; numer urządzenia dla ekranu to 03 USD
LDY #$FF ; brak adresu dodatkowego
JSR SETLFS ; skonfiguruj kanał prawidłowo
; nie SETNAM, ponieważ ekran nie potrzebuje nazwy
;
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wyjścia
LDX#40 dolarów; logiczny numer pliku
CHKOUT JSR
;
; Wprowadź znak z klawiatury
CZEKAJ JSR GETIN ; wstawia 00 $ do A, jeśli kolejka klawiatury jest pusta
CMP#$00; Jeśli 00 dolarów trafiło do A, wówczas Z w porównaniu wynosi 1
BEQ CZEKAJ ; GETIN z kolejki ponownie, jeśli 0 trafiło do akumulatora
BNE PRNSCRN ; przejdź do PRNSCRN, jeśli Z wynosi 0, ponieważ A nie ma już 00 $
; Wyprowadź znak na ekran
PRNSCRN JSR CHROUT ; wyślij znak w A na ekran
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
Notatka : WAIT i PRNSCRN to etykiety identyfikujące adresy. Bajt z klawiatury docierający do akumulatora µP jest kodem ASCII. Odpowiedni kod wysyłany na ekran przez Commodore-64 musi być inny. Dla uproszczenia nie zostało to uwzględnione w poprzednim programie.
5.7 Wysyłanie i odbieranie bajtów na dysk
W jednostce systemowej (płycie głównej) Commodore-64 znajdują się dwa adaptery kompleksowego interfejsu, zwane VIA #1 i CIA #2. Każda jednostka CIA ma dwa porty równoległe, nazywane portem A i portem B. Na pionowej powierzchni z tyłu jednostki systemowej Commodre-64 znajduje się zewnętrzny port, nazywany portem szeregowym. Port ten ma 6 pinów, z czego jeden przeznaczony jest do transmisji danych. Dane wchodzą lub opuszczają jednostkę systemową szeregowo, bit po bicie.
Na przykład osiem równoległych bitów z wewnętrznego portu A CIA nr 2 może wyjść z jednostki systemowej przez zewnętrzny port szeregowy po przekształceniu na dane szeregowe przez rejestr przesuwny w CIA. Ośmiobitowe dane szeregowe z zewnętrznego portu szeregowego mogą trafiać do wewnętrznego portu A CIA nr 2 po przekształceniu ich w dane równoległe przez rejestr przesuwny w CIA.
Jednostka systemowa Commodore-64 (jednostka bazowa) wykorzystuje zewnętrzny napęd dyskowy z dyskietką. Drukarkę można podłączyć do tego napędu dyskowego w sposób łańcuchowy (połączenie urządzeń szeregowo w postaci ciągu). Kabel danych napędu dyskowego jest podłączony do zewnętrznego portu szeregowego jednostki systemowej Commodore-64. Oznacza to, że drukarka połączona łańcuchowo jest również podłączona do tego samego portu szeregowego. Te dwa urządzenia są identyfikowane za pomocą dwóch różnych numerów urządzeń (zazwyczaj odpowiednio 8 i 4).
Wysyłanie lub odbieranie danych na dysk odbywa się według tej samej procedury, co opisano wcześniej. To jest:
- Ustawienie nazwy pliku logicznego (liczby) takiej samej jak nazwa rzeczywistego pliku dyskowego przy użyciu procedury SETNAM.
- Otwarcie pliku logicznego za pomocą procedury OPEN.
- Decydowanie, czy jest to wejście, czy wyjście, za pomocą procedury CHKOUT lub CHKIN.
- Wysyłanie lub odbieranie danych za pomocą instrukcji STA i/lub LDA.
- Zamknięcie pliku logicznego za pomocą procedury CLOSE.
Plik logiczny musi zostać zamknięty. Zamknięcie pliku logicznego skutecznie zamyka ten konkretny kanał. Podczas konfigurowania kanału dla napędu dyskowego o numerze pliku logicznego decyduje programista. Jest to liczba z zakresu od 00 USD do FF (włącznie). Nie powinien to być numer, który został już wybrany dla innego urządzenia (lub aktualnego pliku). Numer urządzenia to 8, jeśli jest tylko jeden napęd dyskowy. Adres dodatkowy (numer) uzyskuje się z instrukcji napędu dysku. Poniższy program używa 2. Program zapisuje literę „E” (ASCII) do pliku na dysku o nazwie „mydoc.doc”. Zakłada się, że nazwa ta zaczyna się od adresu pamięci $C101. Zatem dolny bajt $01 musi znajdować się w rejestrze X, a wyższy bajt $C1 musi znajdować się w rejestrze Y, zanim zostanie wywołana procedura SETNAM. Rejestr A powinien także mieć numer $09 przed wywołaniem procedury SETNAM.
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#08 USD; numer urządzenia dla pierwszego napędu dyskowego
LDY#$02; adres dodatkowy
JSR SETLFS ; skonfiguruj kanał prawidłowo
;
; Plik na dysku wymaga nazwy (jest już w pamięci)
LDA #09 USD
LDX #01 USD
LDY#$C1
JSR SETNAM
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wyjścia
LDX#40 dolarów; logiczny numer pliku
JSR CHKOUT ;do pisania
;
; Wyprowadź znak na dysk
LDA #45 dolarów
JSR CHROUT
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
Aby wczytać bajt z dysku do rejestru µP Y należy powtórzyć poprzedni program z następującymi zmianami: Zamiast „JSR CHKOUT ; do pisania”, użyj „JSR CHKIN ; do czytania'. Zamień segment kodu na „; Wyprowadź znak na dysk” za pomocą następujących poleceń:
; Wprowadź znak z dysku
JSR CHRIS
Dostęp do procedury OS CHRIN uzyskuje się poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFCF. Ta procedura po wywołaniu pobiera bajt z kanału, który jest już ustawiony jako kanał wejściowy i umieszcza go w rejestrze µP A. Zamiast CHRIN można także zastosować procedurę GETIN ROM OS.
Wysyłanie bajtu do drukarki
Wysyłanie bajtu do drukarki odbywa się w podobny sposób jak wysyłanie bajtu do pliku na dysku.
5.8 Procedura ZAPISANIA systemu operacyjnego
Dostęp do procedury OS SAVE można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFD8. Procedura OS SAVE w pamięci ROM zapisuje (zrzuca) część pamięci na dysk jako plik (z nazwą). Adres początkowy sekcji w pamięci musi być znany. Adres końcowy sekcji również musi być znany. Dolny bajt adresu początkowego jest umieszczany na stronie zerowej w pamięci RAM pod adresem $002B. Wyższy bajt adresu początkowego jest umieszczany w następnym bajcie w pamięci pod adresem $002C. Na stronie zerowej etykieta TXTTAB odnosi się do tych dwóch adresów, chociaż TXTTAB w rzeczywistości oznacza adres $002B. Dolny bajt adresu końcowego umieszczany jest w rejestrze µP X. Wyższy bajt adresu końcowego plus 1 jest umieszczany w rejestrze µP Y. Rejestr µP A przyjmuje wartość 2B dla TXTTAB (002B). Dzięki temu można wywołać procedurę SAVE za pomocą następujących poleceń:
JSR ZAPISZ
Sekcją pamięci, która ma zostać zapisana, może być program w języku asemblera lub dokument. Przykładem dokumentu może być list lub esej. Aby skorzystać z procedury zapisywania, należy postępować zgodnie z poniższą procedurą:
- Skonfiguruj kanał za pomocą procedury SETLFS.
- Ustaw nazwę pliku logicznego (liczbę), która jest taka sama jak nazwa rzeczywistego pliku dyskowego, używając procedury SETNAM.
- Otwórz plik logiczny za pomocą procedury OPEN.
- Utwórz plik wyjściowy za pomocą CHKOUT.
- Tutaj znajduje się kod zapisu pliku, który kończy się na „JSR SAVE”.
- Zamknij plik logiczny za pomocą procedury CLOSE.
Poniższy program zapisuje plik rozpoczynający się od komórek pamięci od $C101 do $C200:
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#08 USD; numer urządzenia dla pierwszego napędu dyskowego
LDY#$02; adres dodatkowy
JSR SETLFS ; skonfiguruj kanał prawidłowo
;
; Nazwa pliku na dysku (już w pamięci w $C301)
LDA #09 USD; długość nazwy pliku
LDX #01 USD
LDY#$C3
JSR SETNAM
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wyjścia
LDX#40 dolarów; logiczny numer pliku
CHKOUT JSR ; do pisania
;
; Plik wyjściowy na dysk
LDA #01 USD
STA $2 miliardy; TXTTAB
LDA#$C1
STA $2c
LDX#00 dolarów
LDY#$C2
LDA #2 miliardy dolarów
JSR ZAPISZ
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
Należy pamiętać, że jest to program, który zapisuje inną część pamięci (nie sekcję programu) na dysku (dyskietce dla Commodore-64).
5.9 Procedura ładowania systemu operacyjnego
Dostęp do procedury OS LOAD można uzyskać poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFD5. Kiedy na dysku zapisywany jest fragment (duży obszar) pamięci, zapisywany jest on z nagłówkiem zawierającym adres początkowy sekcji w pamięci. Podprogram OS LOAD ładuje bajty pliku do pamięci. W przypadku tej operacji LOAD wartość akumulatora musi wynosić 010 (00 USD). Aby operacja LOAD odczytała adres początkowy z nagłówka pliku na dysku i umieściła bajty pliku w pamięci RAM, zaczynając od tego adresu, adres pomocniczy kanału musi wynosić 1 lub 2 (poniższy program używa 2). Ta procedura zwraca adres plus 1 z najwyższej załadowanej lokalizacji RAM. Oznacza to, że młodszy bajt ostatniego adresu pliku w RAM plus 1 jest umieszczany w rejestrze µP X, a starszy bajt ostatniego adresu pliku w RAM plus 1 jest umieszczany w rejestrze µP Y.
Jeżeli ładowanie nie powiedzie się, rejestr µP A przechowuje numer błędu (prawdopodobnie 4, 5, 8 lub 9). Ustawiona jest także flaga C rejestru stanu mikroprocesora (wartość 1). Jeżeli ładowanie się powiedzie, ostatnia wartość rejestru A nie jest istotna.
Teraz, w poprzednim rozdziale tego kursu kariery online, pierwsza instrukcja programu w języku asemblera znajduje się pod adresem w pamięci RAM, pod którym program został uruchomiony. To nie musi tak być. Oznacza to, że pierwsza instrukcja programu nie musi znajdować się na początku programu w pamięci RAM. Instrukcja startowa programu może znajdować się w dowolnym miejscu pliku w pamięci RAM. Programiście zaleca się oznaczenie początku instrukcji języka asemblerowego znakiem START. Dzięki temu po załadowaniu program zostaje ponownie uruchomiony (wykonany) z następującą instrukcją języka asemblera:
START JSR
„JSR START” znajduje się w programie w języku asemblera, który ładuje program do uruchomienia. Język asemblera, który ładuje inny plik języka asemblera i uruchamia załadowany plik, ma następującą procedurę kodu:
- Ustaw kanał za pomocą procedury SETLFS.
- Ustaw nazwę pliku logicznego (liczbę), która jest taka sama jak nazwa rzeczywistego pliku dyskowego, używając procedury SETNAM.
- Otwórz plik logiczny za pomocą procedury OPEN.
- Ustaw go jako plik wejściowy za pomocą CHKIN.
- Tutaj znajduje się kod ładowania pliku, który kończy się na „JSR LOAD”.
- Zamknij plik logiczny za pomocą procedury CLOSE.
Poniższy program ładuje plik z dysku i uruchamia go:
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#08 USD; numer urządzenia dla pierwszego napędu dyskowego
LDY#$02; adres dodatkowy
JSR SETLFS ; skonfiguruj kanał prawidłowo
;
; Nazwa pliku na dysku (już w pamięci w $C301)
LDA #09 USD; długość nazwy pliku
LDX #01 USD
LDY#$C3
JSR SETNAM
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wejścia
LDX#40 dolarów; logiczny numer pliku
JSR CHKIN ; do czytania
;
; Plik wejściowy z dysku
LDA#00 dolarów
ŁADOWANIE JSR
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
; Uruchom załadowany program
START JSR
5.10 Modem i standard RS-232
Modem to urządzenie (urządzenie peryferyjne), które przetwarza bity z komputera na odpowiednie elektryczne sygnały audio, które mają być przesyłane linią telefoniczną. Po stronie odbiorczej przed komputerem odbierającym znajduje się modem. Ten drugi modem konwertuje elektryczne sygnały audio na bity dla komputera odbierającego.
Modem należy podłączyć do komputera poprzez port zewnętrzny (na pionowej powierzchni komputera). Standard RS-232 odnosi się do szczególnego typu złącza, które (w przeszłości) łączy modem z komputerem. Innymi słowy, wiele komputerów w przeszłości miało port zewnętrzny będący złączem RS-232 lub złączem zgodnym z RS-232.
Jednostka systemowa Commodore-64 (komputer) ma na swojej tylnej pionowej powierzchni port zewnętrzny, nazywany portem użytkownika. Ten port użytkownika jest kompatybilny z RS-232. Można tam podłączyć urządzenie modemowe. Commodore-64 komunikuje się z modemem poprzez ten port użytkownika. System operacyjny ROM dla Commodore-64 zawiera podprogramy do komunikacji z modemem zwane procedurami RS-232. Procedury te mają wpisy w tabeli skoków.
Szybkość transmisji
Ośmiobitowy bajt z komputera jest konwertowany na serię ośmiu bitów przed wysłaniem do modemu. Odwrotnie postępujemy z modemu do komputera. Szybkość transmisji to liczba bitów przesyłanych szeregowo na sekundę.
Dno pamięci
Termin „dół pamięci” nie odnosi się do lokalizacji bajtów pamięci adresu 0000 $. Odnosi się do najniższej lokalizacji pamięci RAM, w której użytkownik może rozpocząć umieszczanie swoich danych i programów. Domyślnie jest to 0800 USD. Przypomnijmy sobie z poprzedniej dyskusji, że wiele lokalizacji pomiędzy 0800 $ a $BFFF jest używanych przez język komputerowy BASIC i jego programistów (użytkowników). Jedynie lokalizacje adresów $C000 do $CFFF pozostają do wykorzystania dla programów i danych w języku asemblera; jest to 4 KB z 64 KB pamięci.
Szczyt pamięci
W tamtych czasach, gdy klienci kupowali komputery Commodore-64, niektórzy nie dostarczali wszystkich lokalizacji pamięci. Takie komputery miały pamięć ROM z systemem operacyjnym od E000 do $FFFF. Mieli pamięć RAM od 0000 USD do limitu, który nie jest DFFF, obok E000 USD. Limit był poniżej $DFFF i ten limit nazywa się „Top of Memory”. Zatem górna część pamięci nie odnosi się do lokalizacji $FFFF.
Bufory Commodore-64 do komunikacji RS-232
Bufor transmisji
Bufor transmisji RS-232 (wyjście) zajmuje 256 bajtów od góry pamięci w dół. Wskaźnik tego bufora nadawczego jest oznaczony jako ROBUF. Ten wskaźnik znajduje się na stronie zerowej z adresami $00F9, po których następuje $00FA. ROBUF faktycznie identyfikuje $00F9. Tak więc, jeśli adres początku bufora to $BE00, dolny bajt $BE00, czyli 00 $, znajduje się w lokalizacji $00F9, a wyższy bajt $BE00, czyli $BE, znajduje się w $00FA Lokalizacja.
Bufor odbiorczy
Bufor do odbioru bajtów RS-232 (wejście) zajmuje 256 bajtów od dołu bufora nadawczego. Wskaźnik tego bufora odbiorczego jest oznaczony jako RIBUF. Ten wskaźnik znajduje się na stronie zerowej z adresami $00F7, po których następuje $00F8. RIBUF faktycznie identyfikuje $00F7. Tak więc, jeśli adres początku bufora to $BF00, dolny bajt $BF00, czyli 00 $, znajduje się w lokalizacji $00F7, a wyższy bajt $BF00, czyli $BF, znajduje się w $00F8 Lokalizacja. Zatem 512 bajtów z górnej części pamięci jest wykorzystywane jako całkowity bufor RS-232 RAM.
Kanał RS-232
Gdy modem jest podłączony do (zewnętrznego) portu użytkownika, komunikacja z modemem odbywa się wyłącznie poprzez komunikację RS-232. Procedura uzyskania pełnego kanału RS-232 jest prawie taka sama jak w poprzedniej dyskusji, ale z jedną istotną różnicą: nazwa pliku to kod, a nie ciąg znaków w pamięci. Kod $0610 to dobry wybór. Oznacza to prędkość transmisji 300 bitów/s i inne parametry techniczne. Nie ma też adresu dodatkowego. Należy pamiętać, że numer urządzenia to 2. Procedura konfiguracji pełnego kanału RS-232 jest następująca:
- Ustawianie kanału za pomocą procedury SETLFS.
- Ustawienie nazwy pliku logicznego, $0610.
- Otwarcie pliku logicznego za pomocą procedury OPEN.
- Uczyń go plikiem wyjściowym za pomocą CHKOUT lub plikiem wejściowym za pomocą CHKIN.
- Wysyłanie pojedynczych bajtów za pomocą CHROUT lub odbieranie pojedynczych bajtów za pomocą GETIN.
- Zamknięcie pliku logicznego za pomocą procedury CLOSE.
Dostęp do procedury OS GETIN uzyskuje się poprzez skok (JSR) do tabeli skoków OS ROM pod adresem $FFE4. Ta procedura, gdy zostanie wywołana, pobiera bajt wysłany do bufora odbiornika i umieszcza go (zwraca) do akumulatora µP.
Poniższy program wysyła bajt „E” (ASCII) do modemu podłączonego do portu użytkownika kompatybilnego z RS-232:
; Konfiguracja kanału
LDA #40 dolarów; logiczny numer pliku
LDX#$02; numer urządzenia dla RS-232
LDY #$FF ; brak adresu dodatkowego
JSR SETLFS ; skonfiguruj kanał prawidłowo
;
; Nazwa dla RS-232 to kod np.: 0610 dolarów
LDA#$02; długość kodu wynosi 2 bajty
LDX#10 dolarów
LDY#$06
JSR SETNAM
;
; Otwórz plik logiczny
JSR OTWARTE
; Ustaw kanał dla wyjścia
LDX#40 dolarów; logiczny numer pliku
CHKOUT JSR
;
; Znak wyjściowy na RS-232, np. modem
LDA #45 dolarów
JSR CHROUT
; Zamknij plik logiczny
LDA #40 dolarów
JSR ZAMKNIĘTE
Aby otrzymać bajt, kod jest bardzo podobny, z tą różnicą, że „JSR CHKOUT” zostaje zastąpiony przez „JSR CHKIN” i:
LDA #45 dolarów
JSR CHROUT
zostaje zastąpiony przez „JSR GETIN”, a wynik zostaje umieszczony w rejestrze A.
Ciągłe wysyłanie lub odbieranie bajtów odbywa się poprzez pętlę odpowiednio do wysyłania lub odbierania segmentu kodu.
Należy zauważyć, że wejście i wyjście na Commodore jest w większości przypadków podobne, z wyjątkiem klawiatury, gdzie niektóre procedury nie są wywoływane przez programistę, ale przez system operacyjny.
5.11 Liczenie i synchronizacja
Rozważmy sekwencję odliczania, która jest następująca:
2, 1, 0
To jest odliczanie od 2 do 0. Teraz rozważ powtarzającą się sekwencję odliczania:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Jest to powtarzające się odliczanie tej samej sekwencji. Sekwencja jest powtarzana czterokrotnie. Cztery razy oznacza, że czas wynosi 4. Liczenie odbywa się w obrębie jednej sekwencji. Powtarzanie tej samej sekwencji to wyczucie czasu.
W jednostce systemowej Commodore-64 znajdują się dwa adaptery kompleksowego interfejsu. Każda CIA ma dwa obwody liczników/zegarów o nazwach Timer A (TA) i Timer B (TB). Obwód zliczający nie różni się od obwodu czasowego. Licznik lub timer w Commodore-64 odnosi się do tego samego. W rzeczywistości każdy z nich zasadniczo odnosi się do jednego 16-bitowego rejestru, który zawsze odlicza do 0 w przypadku impulsów zegara systemowego. W rejestrze 16-bitowym można ustawić różne wartości. Im większa wartość, tym dłużej trwa odliczanie do zera. Za każdym razem, gdy jeden z liczników przekroczy zero, następuje Przerwanie Sygnał przerwania jest wysyłany do mikroprocesora. Kiedy licznik spada powyżej zera, nazywa się to niedomiarem.
W zależności od sposobu zaprogramowania obwodu czasowego, timer może działać w trybie jednorazowym lub w trybie ciągłym. Na poprzedniej ilustracji tryb jednorazowy oznacza „zrób 2, 1, 0” i zatrzymaj się, aż impulsy zegara będą kontynuowane. Tryb ciągły to „2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0 itd.” który kontynuuje się wraz z impulsami zegara. Oznacza to, że gdy przekroczy zero, jeśli nie zostanie podana żadna instrukcja, sekwencja odliczania się powtarza. Największa liczba jest zwykle znacznie większa niż 2.
Generuje się licznik czasu A (TA) CIA nr 1 Przerwanie w regularnych odstępach czasu (czasie trwania) w celu serwisowania klawiatury. W rzeczywistości jest to domyślnie co 1/60 sekundy. Przerwanie jest wysyłany do mikroprocesora co 1/60 sekundy. To tylko kiedy Przerwanie wysyłane jest powiadomienie, że program może odczytać wartość klucza z kolejki klawiatury (bufora). Pamiętaj, że mikroprocesor ma tylko jeden pin dla Przerwanie sygnał. Mikroprocesor ma również tylko jeden pin dla NMI sygnał. Sygnał ¯NMI do mikroprocesora zawsze pochodzi z CIA nr 2.
16-bitowy rejestr czasowy ma dwa adresy pamięci: jeden dla młodszego bajtu i jeden dla starszego bajtu. Każda CIA ma dwa obwody czasowe. Obie CIA są identyczne. W przypadku CIA nr 1 adresy dwóch timerów to: DC04 i DC05 dla TA oraz DC06 i DC07 dla TB. W przypadku CIA nr 2 adresy dwóch timerów to: DD04 i DD05 dla TA oraz DD06 i DD07 dla TB.
Załóżmy, że numer 25510 ma zostać wysłany do licznika czasu TA CIA nr 2 w celu odliczania. 25510 = 00000000111111112 składa się z szesnastu bitów. 00000000111111112 = 000FFF w formacie szesnastkowym. W tym przypadku $FF wysyłane jest do rejestru na adres $DD04, a 00 $ do rejestru na adres $DD05 – mała endianność. Następujący segment kodu wysyła numer do rejestru:
LDA#$FF
STAN $DD04
LDA#00 dolarów
STAN $DD05
Chociaż rejestry w CIA mają adresy RAM, fizycznie znajdują się w CIA, a CIA to odrębny układ scalony niż RAM i ROM.
To nie wszystko! Gdy timerowi zostanie nadany numer do odliczania, tak jak w przypadku poprzedniego kodu, odliczanie nie rozpoczyna się. Odliczanie rozpoczyna się w momencie przesłania ośmiobitowego bajtu do odpowiedniego rejestru sterującego timera. Pierwszy bit tego bajtu rejestru sterującego wskazuje, czy powinno rozpocząć się odliczanie. Wartość 0 dla tego pierwszego bitu oznacza zatrzymanie odliczania, natomiast wartość 1 oznacza rozpoczęcie odliczania. Bajt musi także wskazywać, czy odliczanie odbywa się w trybie jednorazowym (jednorazowym), czy w trybie swobodnym (tryb ciągły). Tryb jednorazowy odlicza i zatrzymuje się, gdy wartość rejestru timera osiągnie zero. W trybie pracy swobodnej odliczanie jest powtarzane po osiągnięciu wartości 0. Czwarty (indeks 3) bit bajtu wysyłany do rejestru sterującego wskazuje tryb: 0 oznacza tryb pracy swobodnej, a 1 oznacza tryb jednorazowy.
Odpowiednią liczbą do rozpoczęcia liczenia w trybie jednorazowym jest 000010012 = 09 USD w formacie szesnastkowym. Odpowiednią liczbą do rozpoczęcia liczenia w trybie swobodnym jest 000000012 = 01 $ w formacie szesnastkowym. Każdy rejestr timera ma swój własny rejestr kontrolny. W CIA nr 1 rejestr kontrolny timera A ma adres RAM DC0E16, a rejestr kontrolny timera B ma adres RAM DC0F16. W CIA nr 2 rejestr kontrolny timera A ma adres RAM DD0E16, a rejestr kontrolny timera B ma adres RAM DD0F16. Aby rozpocząć odliczanie szesnastobitowej liczby w TA CIA nr 2, w trybie jednorazowym, użyj następującego kodu:
LDA #09 USD
STA$DD0E
Aby rozpocząć odliczanie szesnastobitowej liczby w TA CIA #2, w trybie swobodnym, użyj następującego kodu:
LDA #01 USD
STA$DD0E
5.12 Przerwanie I NMI Upraszanie
Mikroprocesor 6502 ma tzw Przerwanie I NMI linie (kołki). Zarówno CIA nr 1, jak i CIA nr 2 mają Przerwanie pin do mikroprocesora. The Przerwanie pin CIA nr 2 jest podłączony do NMI pin µP. The Przerwanie pin CIA nr 1 jest podłączony do Przerwanie pin µP. To jedyne dwie linie przerwań, które łączą mikroprocesor. Zatem, Przerwanie PIN CIA nr 2 to NMI źródło i może być również postrzegane jako linia ¯NMI.
CIA nr 1 ma pięć możliwych bezpośrednich źródeł generowania Przerwanie sygnał dla µP. CIA nr 2 ma taką samą strukturę jak CIA nr 1. Zatem CIA nr 2 ma tym razem pięć możliwych bezpośrednich źródeł generowania sygnału przerwania, czyli: NMI sygnał. Pamiętaj, że kiedy µP odbierze NMI sygnał, jeśli obsługuje Przerwanie żądanie, zawiesza je i obsługuje NMI wniosek. Kiedy zakończy obsługę NMI żądanie, następnie wznawia obsługę pliku Przerwanie wniosek.
CIA nr 1 jest zwykle podłączana zewnętrznie do klawiatury i urządzenia do gier, takiego jak joystick. Klawiatura wykorzystuje więcej portu A CIA nr 1 niż port B. Urządzenie do gier wykorzystuje więcej portu B CIA nr 1 niż port A. CIA nr 2 jest zwykle podłączone zewnętrznie do napędu dyskowego (połączone łańcuchowo z drukarką) i modem. Napęd dyskowy wykorzystuje więcej portu A CIA nr 2 (choć przez zewnętrzny port szeregowy) niż swój port B. Modem (RS-232) wykorzystuje więcej portu B CIA nr 2 niż swój port A.
Skąd jednostka systemowa wie, co jest przyczyną problemu Przerwanie Lub NMI przerywać? CIA nr 1 i CIA nr 2 mają pięć bezpośrednich źródeł przerwań. Jeśli sygnał przerwania do µP wynosi NMI , źródło jest jednym z pięciu bezpośrednich źródeł z CIA nr 2. Jeśli sygnał przerwania do µP wynosi Przerwanie , źródłem jest jedno z pięciu bezpośrednich źródeł z CIA nr 1.
Następne pytanie brzmi: „W jaki sposób jednostka systemowa rozróżnia pięć bezpośrednich źródeł każdej CIA?” Każda CIA ma ośmiobitowy rejestr nazywany rejestrem kontroli przerwań (ICR). ICR obsługuje oba porty CIA. Poniższa tabela pokazuje znaczenie ośmiu bitów rejestru sterującego przerwaniami, zaczynając od bitu 0:
| Tabela 5.13 Rejestr kontroli przerwań |
|
|---|---|
| Indeks bitowy | Oznaczający |
| 0 | Ustaw (wykonaj 1) przez niedopełnienie timera A |
| 1 | Ustawiane przy przekroczeniu limitu czasowego B |
| 2 | Ustaw, kiedy zegar czasu dziennego zrówna się z alarmem |
| 3 | Ustawiane, gdy port szeregowy jest pełny |
| 4 | Ustawiane przez urządzenie zewnętrzne |
| 5 | Nieużywany (zrobiony 0) |
| 6 | Nieużywany (zrobiony 0) |
| 7 | Ustawiane, gdy ustawiony jest dowolny z pierwszych pięciu bitów |
Jak widać z tabeli, każde z bezpośrednich źródeł jest reprezentowane przez jeden z pierwszych pięciu bitów. Tak więc, gdy sygnał przerwania zostanie odebrany w µP, należy wykonać kod, aby odczytać zawartość rejestru sterującego przerwaniem i poznać dokładne źródło przerwania. Adres RAM dla ICR CIA nr 1 to DC0D16. Adres RAM dla ICR CIA nr 2 to DD0D16. Aby odczytać (zwrócić) zawartość ICR CIA nr 1 do akumulatora µP, wpisz następującą instrukcję:
LDA$DC0D
Aby odczytać (zwrócić) zawartość ICR CIA #2 do akumulatora µP, wpisz następującą instrukcję:
LDA$DD0D
5.13 Program działający w tle sterowany przerwaniami
Klawiatura zwykle przerywa działanie mikroprocesora co 1/60 sekundy. Wyobraź sobie, że program jest uruchomiony i osiąga pozycję oczekiwania na klawisz z klawiatury, zanim będzie mógł kontynuować wykonywanie poniższych segmentów kodu. Załóżmy, że jeśli na klawiaturze nie zostanie naciśnięty żaden klawisz, program wykona jedynie małą pętlę w oczekiwaniu na klawisz. Wyobraź sobie, że program jest uruchomiony i oczekuje klawisza z klawiatury zaraz po wydaniu przerwania klawiaturowego. W tym momencie cały komputer pośrednio się zatrzymuje i nie robi nic poza wykonaniem pętli oczekiwania. Wyobraź sobie, że klawisz klawiatury zostaje naciśnięty tuż przed kolejnym wydaniem kolejnego przerwania klawiaturowego. Oznacza to, że komputer nie zrobił nic przez około jedną sześćdziesiątą sekundy! To długi czas, w którym komputer nie mógł nic zrobić, nawet w czasach Commodore-64. W tym czasie (czasie trwania) komputer mógł robić coś innego. W programie jest wiele takich czasów trwania.
Można napisać drugi program tak, aby działał w takich „bezczynnych” okresach czasu. Mówi się, że taki program działa w tle programu głównego (lub pierwszego). Łatwym sposobem na osiągnięcie tego jest po prostu wymuszenie zmodyfikowanej obsługi przerwania BRK, gdy oczekuje się naciśnięcia klawisza z klawiatury.
Wskaźnik instrukcji BRK
W kolejnych lokalizacjach pamięci RAM adresów $0316 i $0317 znajduje się wskaźnik (wektor) aktualnej procedury instrukcji BRK. Domyślny wskaźnik jest tam umieszczany, gdy komputer jest włączany przez system operacyjny zapisany w pamięci ROM. Ten domyślny wskaźnik jest adresem, który nadal wskazuje na domyślną procedurę obsługi instrukcji BRK w pamięci ROM systemu operacyjnego. Wskaźnik jest adresem 16-bitowym. Dolny bajt wskaźnika jest umieszczany w lokalizacji bajtowej adresu $0306, a wyższy bajt wskaźnika jest umieszczany w lokalizacji bajtowej $0317.
Drugi program można napisać w taki sposób, że gdy system jest „bezczynny”, niektóre kody drugiego programu są wykonywane przez system. Oznacza to, że drugi program musi składać się z podprogramów. Gdy system jest „bezczynny” i oczekuje na klawisz z klawiatury, wykonywany jest kolejny podprogram dla drugiego programu. Interakcja człowieka z komputerem jest powolna w porównaniu z pracą jednostki systemowej.
Rozwiązanie tego problemu jest łatwe: za każdym razem, gdy komputer musi czekać na klawisz z klawiatury, wstaw do kodu instrukcję BRK i zamień wskaźnik na $0316 (i $0317) wskaźnikiem następnego podprogramu drugiej ( niestandardowego) programu. W ten sposób oba programy będą działać w czasie niewiele dłuższym niż czas trwania głównego programu działającego samodzielnie.
5.14 Montaż i kompilacja
Asembler zastępuje wszystkie etykiety adresami. Program w języku asemblera jest zwykle pisany tak, aby zaczynał się od określonego adresu. Wynik asemblera (po asemblacji) nazywany jest „kodem obiektowym”, w którym wszystko jest binarne. Wynikiem jest plik wykonywalny, jeśli jest to program, a nie dokument. Dokument nie jest wykonywalny.
Aplikacja składa się z więcej niż jednego programu (w języku asemblera). Zwykle jest program główny. Sytuacji tej nie należy mylić z sytuacją programów działających w tle sterowanych przerwaniami. Wszystkie programy tutaj są programami pierwszego planu, ale istnieje program pierwszy, czyli główny.
Jeśli istnieje więcej niż jeden program na pierwszym planie, potrzebny jest kompilator zamiast asemblera. Kompilator składa każdy z programów w kod obiektowy. Pojawiłby się jednak problem: niektóre segmenty kodu będą się na siebie nakładać, ponieważ programy są prawdopodobnie pisane przez różne osoby. Rozwiązaniem kompilatora jest przesunięcie wszystkich nakładających się programów z wyjątkiem pierwszego w przestrzeni pamięci, tak aby programy się nie nakładały. Teraz, jeśli chodzi o przechowywanie zmiennych, niektóre adresy zmiennych nadal będą się nakładać. Rozwiązaniem jest zastąpienie nakładających się adresów nowymi adresami (z wyjątkiem pierwszego programu), tak aby nie nakładały się już na siebie. W ten sposób różne programy będą pasować do różnych części (obszarów) pamięci.
Dzięki temu możliwe jest, że jedna procedura w jednym programie wywoła procedurę w innym programie. Zatem kompilator wykonuje łączenie. Łączenie oznacza posiadanie adresu początkowego podprogramu w jednym programie, a następnie wywoływanie go w innym programie; oba są częścią aplikacji. W tym celu oba programy muszą używać tego samego adresu. Efektem końcowym jest jeden duży kod obiektowy ze wszystkim w formacie binarnym (bity).
5.15 Zapisywanie, ładowanie i uruchamianie programu
Język asemblera jest zwykle napisany w jakimś edytorze (który może być dostarczony z programem asemblera). Program edytora wskazuje, gdzie program zaczyna się i kończy w pamięci (RAM). Procedura Kernal SAVE pamięci ROM systemu operacyjnego Commodore-64 może zapisać program z pamięci na dysk. Po prostu zrzuca na dysk sekcję (blok) pamięci, która może zawierać wywołanie instrukcji. Wskazane jest, aby instrukcja wywołująca SAVE była oddzielona od programu, który jest zapisywany, tak aby program po załadowaniu do pamięci z dysku nie zapisał się ponownie po uruchomieniu. Ładowanie programu w języku asemblera z dysku jest wyzwaniem innego rodzaju, ponieważ program nie może załadować się sam.
Program nie może załadować się z dysku do miejsca, w którym zaczyna się i kończy w pamięci RAM. W tamtych czasach Commodore-64 był zwykle wyposażony w interpreter języka BASIC, umożliwiający uruchamianie programów w języku BASIC. Kiedy maszyna (komputer) jest włączona, wszystko zostaje ustalone w wierszu poleceń: GOTOWY. Stamtąd można wpisywać polecenia lub instrukcje języka BASIC, naciskając klawisz „Enter” po wpisaniu. Polecenie BASIC (instrukcja) ładowania pliku to:
Wczytaj „nazwę pliku”, 8,1
Polecenie zaczyna się od słowa zastrzeżonego języka BASIC, którym jest LOAD. Po tym następuje spacja, a następnie nazwa pliku w cudzysłowie. Po numerze urządzenia 8 następuje poprzedzony przecinkiem. Po dodatkowym adresie dysku wynoszącym 1 następuje przecinek. W przypadku takiego pliku adres początkowy programu w języku asemblera znajduje się w nagłówku pliku na dysku. Kiedy BASIC zakończy ładowanie programu, zwracany jest ostatni adres RAM plus 1 programu. Słowo „zwrócone” oznacza tutaj, że dolny bajt ostatniego adresu plus 1 jest umieszczany w rejestrze µP X, a wyższy bajt ostatniego adresu plus 1 jest umieszczany w rejestrze µP Y.
Po załadowaniu programu należy go uruchomić (wykonać). Użytkownik programu musi znać adres początkowy wykonania w pamięci. Ponownie potrzebny jest tutaj kolejny program w języku BASIC. Jest to polecenie SYS. Po wykonaniu polecenia SYS program w języku asemblera uruchomi się (i zatrzyma). Jeśli podczas działania potrzebne jest jakiekolwiek wejście z klawiatury, program w języku asemblera powinien o tym poinformować użytkownika. Po wpisaniu przez użytkownika danych na klawiaturze i naciśnięciu klawisza „Enter”, program w języku asemblera będzie kontynuował działanie, korzystając z wpisów z klawiatury, bez ingerencji interpretera języka BASIC.
Zakładając, że początkowy adres RAM wykonania (bieżącego) programu języka asemblera to C12316, C123 jest konwertowany na dziesiątkę przed użyciem go za pomocą polecenia SYS. Konwersja C12316 na bazę dziesiątkową wygląda następująco:
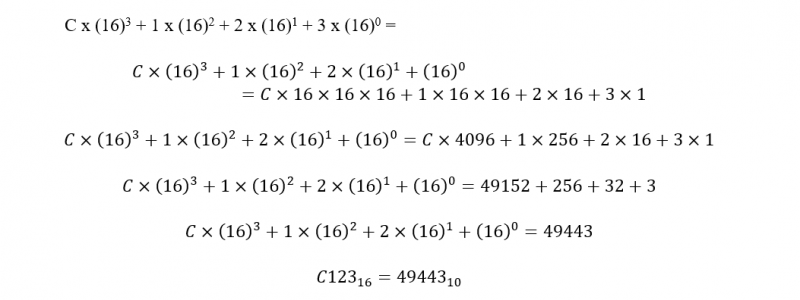
Zatem polecenie BASIC SYS to:
SYS 49443
5.16 Uruchamianie Commodore-64
Uruchamianie Commodore-64 składa się z dwóch faz: fazy resetowania sprzętu i fazy inicjalizacji systemu operacyjnego. System operacyjny to Kernal w pamięci ROM (a nie na dysku). Istnieje linia resetowania (właściwie OZE ), który łączy się z pinem 6502 µP i z pinem o tej samej nazwie we wszystkich statkach specjalnych, takich jak CIA 1, CIA 2 i VIC II. W fazie resetowania, dzięki tej linii, wszystkie rejestry w µP iw specjalnych chipach są resetowane do 0 (zero dla każdego bitu). Następnie przez sprzęt mikroprocesora nadawany jest wskaźnik stosu i rejestr stanu procesora wraz z ich wartościami początkowymi w mikroprocesorze. Licznik programu otrzymuje wówczas wartość (adres) w lokalizacjach $FFFC i $FFFD. Przypomnijmy, że licznik programu przechowuje adres następnej instrukcji. Przechowywana tutaj treść (adres) dotyczy podprogramu rozpoczynającego inicjalizację oprogramowania. Wszystko jak dotąd odbywa się za pomocą sprzętu mikroprocesorowego. Na tym etapie cała pamięć nie jest dotknięta. Następnie rozpoczyna się następna faza inicjalizacji.
Inicjalizacja odbywa się za pomocą niektórych procedur systemu operacyjnego ROM. Inicjalizacja oznacza nadanie wartości początkowych lub domyślnych niektórym rejestrom w specjalnych chipach. Inicjalizacja rozpoczyna się od nadania wartości początkowych lub domyślnych niektórym rejestrom w specjalnych chipach. Przerwanie na przykład musi zaczynać się co 1/60 sekundy. Zatem odpowiadający mu zegar w CIA nr 1 musi zostać ustawiony na wartość domyślną.
Następnie Kernal przeprowadza test pamięci RAM. Testuje każdą lokalizację, wysyłając bajt do lokalizacji i odczytując go. Jeśli jest jakaś różnica, to przynajmniej ta lokalizacja jest zła. Kernal identyfikuje również górną i dolną część pamięci i ustawia odpowiednie wskaźniki na stronie 2. Jeśli górna część pamięci to $DFFF, $FF jest umieszczane w lokalizacji $0283, a $DF jest umieszczane w lokalizacji bajtowej $0284. Zarówno $0283, jak i $0284 mają etykietę HIRAM. Jeśli dolna część pamięci wynosi 0800 USD, 00 USD jest umieszczane w lokalizacji 0281 USD, a 08 USD w lokalizacji 0282 USD. Zarówno $0281, jak i $0282 mają etykietę LORAM. Test pamięci RAM faktycznie zaczyna się od 0300 $ do szczytu pamięci (RAM).
Na koniec wektory wejściowe/wyjściowe (wskaźniki) są ustawiane na wartości domyślne. Test pamięci RAM faktycznie rozpoczyna się od 0300 $ do szczytu pamięci (RAM). Oznacza to, że inicjowane są strony 0, strony 1 i strony 2. W szczególności strona 0 zawiera wiele wskaźników OS ROM, a strona 2 ma wiele wskaźników BASIC. Wskaźniki te nazywane są zmiennymi. Pamiętaj, że strona 1 to stos. Wskaźniki nazywane są zmiennymi, ponieważ mają nazwy (etykiety). Na tym etapie pamięć ekranu jest czyszczona dla ekranu (monitora). Oznacza to wysłanie kodu o wartości 20 dolarów za miejsce (co jest tym samym, co 20 dolarów w kodzie ASCII) do lokalizacji na ekranie 1000 RAM. Na koniec Kernal uruchamia interpreter BASIC-a, aby wyświetlić wiersz poleceń BASIC-a, który jest GOTOWY na górze monitora (ekran).
5.17 Problemy
Czytelnikowi zaleca się rozwiązanie wszystkich problemów zawartych w danym rozdziale przed przejściem do następnego rozdziału.
- Napisz kod w języku asemblera, który uczyni wszystkie bity portu A CIA nr 2 jako wyjście i portu B CIA nr 2 jako wejście.
- Napisz kod języka asemblera 6502, który czeka na klawisz klawiatury, aż zostanie naciśnięty.
- Napisz program w języku asemblera 6502, który wysyła znak „E” na ekran Commodore-64.
- Napisz program w języku asemblera 6502, który pobiera znak z klawiatury i wysyła go na ekran Commodore-64, ignorując kod klawisza i synchronizację.
- Napisz program w języku asemblera 6502, który odbiera bajt z dyskietki Commodore-64.
- Napisz program w języku asemblera 6502, który zapisuje plik na dyskietce Commodore-64.
- Napisz program w języku asemblera 6502, który ładuje plik programu z dyskietki Commodore-64 i uruchamia go.
- Napisz program w języku asemblera 6502, który wysyła bajt „E” (ASCII) do modemu podłączonego do portu Commodore-64 zgodnego z RS-232 użytkownika.
- Wyjaśnij, w jaki sposób liczenie i synchronizacja są wykonywane w komputerze Commodore-64.
- Wyjaśnij, w jaki sposób jednostka systemowa Commodore-64 może zidentyfikować 10 różnych źródeł natychmiastowych żądań przerwań, w tym żądania przerwań niemaskowalnych.
- Wyjaśnij, jak program działający w tle może działać z programem pierwszoplanowym na komputerze Commodore-64.
- Krótko wyjaśnij, w jaki sposób programy w języku asemblera można skompilować w jedną aplikację dla komputera Commodore-64.
- Krótko wyjaśnij proces uruchamiania komputera Commodore-64.