Procedura
Ten artykuł pokaże praktyczną demonstrację metody tworzenia wdrożenia dla Kubernetes. Aby pracować z Kubernetes, musimy najpierw upewnić się, że mamy platformę, na której możemy uruchomić Kubernetes. Platformy te obejmują: platformę chmurową Google, Linux/Ubuntu, AWS itp. Możemy używać dowolnej z wymienionych platform, aby pomyślnie uruchomić Kubernetes.
Przykład nr 01
Ten przykład pokaże, jak możemy stworzyć wdrożenie w Kubernetes. Przed rozpoczęciem wdrażania Kubernetes musielibyśmy najpierw utworzyć klaster, ponieważ Kubernetes to platforma typu open source, która służy do zarządzania i koordynowania wykonywania aplikacji kontenerów w wielu klastrach komputerów. Klaster dla Kubernetes ma dwa różne typy zasobów. Każdy zasób ma swoją funkcję w klastrze i są to „płaszczyzna kontroli” i „węzły”. Płaszczyzna kontrolna w klastrze działa jako menedżer dla klastra Kubernetes.
To koordynuje i zarządza każdą możliwą aktywnością w klastrze od planowania aplikacji, utrzymywania lub utrzymywania pożądanego stanu aplikacji, kontrolowania nowej aktualizacji, a także efektywnego skalowania aplikacji.
Klaster Kubernetes ma w sobie dwa węzły. Węzłem w klastrze może być maszyna wirtualna lub komputer w postaci fizycznej (fizycznej), a jego funkcjonalność polega na działaniu tak, jak maszyna pracuje dla klastra. Każdy węzeł ma swój kubelet i komunikuje się z płaszczyzną kontrolną klastra Kubernetes, a także zarządza węzłem. Tak więc funkcja klastra, za każdym razem, gdy wdrażamy aplikację na Kubernetes, pośrednio informujemy płaszczyznę kontrolną w klastrze Kubernetes, aby uruchomiła kontenery. Następnie płaszczyzna kontrolna sprawia, że kontenery działają na węzłach klastrów Kubernetes.
Węzły te koordynują następnie z płaszczyzną sterowania za pośrednictwem interfejsu API Kubernetes, który jest udostępniany przez panel sterowania. Mogą one być również używane przez użytkownika końcowego do interakcji z klastrem Kubernetes.
Klaster Kubernetes możemy wdrożyć zarówno na komputerach fizycznych, jak i maszynach wirtualnych. Na początek z Kubernetes możemy skorzystać z platformy wdrożeniowej Kubernetes „MiniKube”, która umożliwia pracę maszyny wirtualnej na naszych lokalnych systemach i jest dostępna dla każdego systemu operacyjnego, takiego jak Windows, Mac i Linux. Zapewnia również operacje ładowania początkowego, takie jak uruchamianie, status, usuwanie i zatrzymywanie. Teraz utwórzmy ten klaster i utwórzmy na nim pierwsze wdrożenie Kubernetes.
Do wdrożenia będziemy używać Minikube, który mamy preinstalowany w systemach. Teraz, aby zacząć z nim pracować, najpierw sprawdzimy, czy minikube działa i jest poprawnie zainstalowany i aby to zrobić w oknie terminala, wpisz następujące polecenie:
$ Wersja minikubeWynikiem polecenia będzie:

Teraz przejdziemy dalej i spróbujemy uruchomić minikube bez polecenia jako
$ uruchom minikube 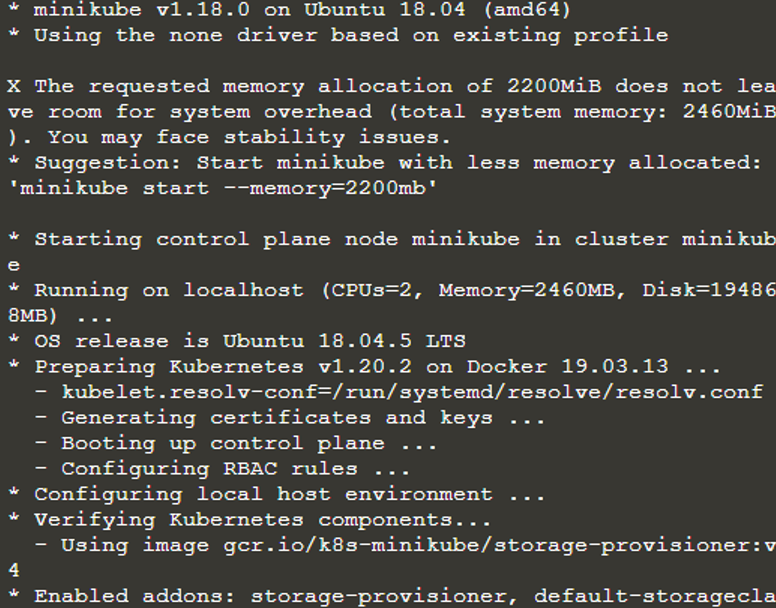
Po wykonaniu powyższego polecenia minikube uruchomił teraz oddzielną maszynę wirtualną, a na tej maszynie wirtualnej działa teraz klaster Kubernetes. Tak więc mamy teraz działający klaster Kubernetes w terminalu. Aby wyszukać lub uzyskać informacje o klastrze, użyjemy interfejsu poleceń „kubectl”. W tym celu sprawdzimy, czy kubectl jest zainstalowany, wpisując polecenie „wersja kubectl”.
$ wersja kubectla 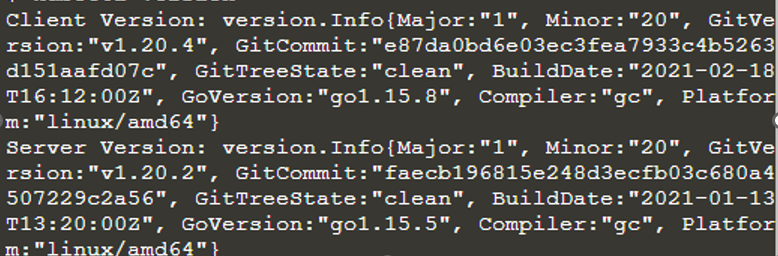
Kubectl jest zainstalowany i skonfigurowany. Zawiera również informacje o kliencie i serwerze. Teraz uruchamiamy klaster Kubernetes, abyśmy mogli dowiedzieć się o jego szczegółach, używając polecenia kubectl jako „kubectl cluster-info”.
$ informacje o klastrze kubectl 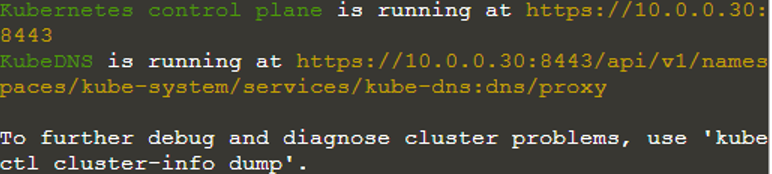
Sprawdźmy teraz, czy istnieją węzły klastra Kubernetes, używając polecenia „kubectl get nodes”.
$ kubectl pobiera węzły 
Klaster ma tylko jeden węzeł i jego stan to gotowy, co oznacza, że ten węzeł jest już gotowy do przyjmowania zgłoszeń.
Utworzymy teraz wdrożenie przy użyciu interfejsu wiersza poleceń kubectl, który obsługuje interfejs API Kubernetes i współdziała z klastrem Kubernetes. Kiedy tworzymy nowe wdrożenie, musimy określić obraz aplikacji i liczbę kopii aplikacji, które można wywołać i zaktualizować po utworzeniu wdrożenia. Aby utworzyć nowe wdrożenie do uruchomienia na Kubernetes, użyj polecenia „Kubernetes utwórz wdrożenie”. W tym celu określ nazwę wdrożenia, a także lokalizację obrazu dla aplikacji.

Teraz wdrożyliśmy nową aplikację, a powyższe polecenie wyszukało węzeł, na którym aplikacja może działać, co w tym przypadku było tylko jednym. Teraz pobierz listę wdrożeń za pomocą polecenia „kubectl get wdrożenia”, a otrzymamy następujące dane wyjściowe:
$ kubectl pobierz wdrożenia 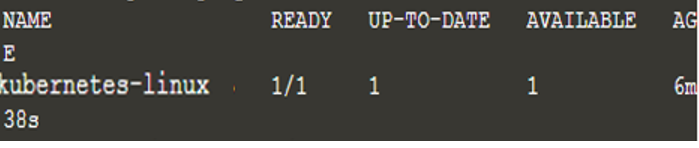
Przejrzymy aplikację na hoście proxy, aby opracować połączenie między hostem a klastrem Kubernetes.
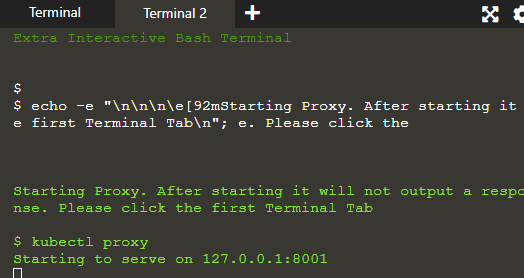
Serwer proxy działa w drugim terminalu, gdzie wykonywane są polecenia podane w terminalu 1, a ich wynik jest wyświetlany w terminalu 2 na serwerze: 8001.
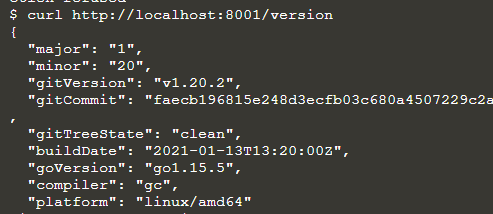
Pod jest jednostką wykonania dla aplikacji Kubernetes. Więc tutaj określimy nazwę kapsuły i uzyskamy do niej dostęp przez API.

Wniosek
W tym przewodniku omówiono metody tworzenia wdrożenia w Kubernetes. Uruchomiliśmy wdrożenie na wdrożeniu Minikube Kubernetes. Najpierw nauczyliśmy się tworzyć klaster Kubernetes, a następnie za pomocą tego klastra stworzyliśmy wdrożenie do uruchamiania określonej aplikacji na Kubernetes.