W tym artykule zbadamy znaczenie struktury danych , różne rodzaje struktury danych dostępne w języku C++ i jak efektywnie wykorzystywać je w swoich programach.
Czym jest struktura danych w C++
The struktura danych jest podstawową koncepcją w programowaniu i odgrywa istotną rolę w przechowywaniu i organizowaniu danych. W języku C++ strukturę danych można zdefiniować jako sposób przechowywania danych i zarządzania nimi w określonym formacie. Pozwala to na efektywny dostęp do danych i manipulowanie nimi, ułatwiając programistom pisanie i utrzymywanie kodu.
W C++ tzw struktury danych mieć następującą składnię:
struktura nazwa_struktury {
nazwa typu danych11 ;
nazwa typu danych22 ;
nazwa typu danych33 ;
nazwa typu danych44 ;
..
..
..
} nazwa_obiektu ;
W powyższej składni słowo kluczowe struktury służy do definiowania struktury i nazwa_struktury jest zdefiniowaną przez użytkownika nazwą struktury i może być różna. The typ danych1 jest typem danych członka struktury i nazwa1 jest nazwą członka struktury i nazwa_obiektu jest nazwą obiektu, dla którego zdefiniowano strukturę.
Przykład
W poniższym przykładzie informacje o strukturze składa się z trzech członków: imię Wiek, I obywatelstwo.
struktura Informacje
{
zwęglać nazwa [ pięćdziesiąt ] ;
int obywatelstwo ;
int wiek ;
}
Uruchommy ten kod w C++, zdefiniowaliśmy wszystkich tych członków w strukturze osoba i nie przydzieliliśmy żadnej przestrzeni. W funkcji main zainicjowaliśmy te elementy z określonymi wartościami i wydrukowaliśmy je:
#includeprzy użyciu przestrzeni nazw std ;
struktura Informacje
{
nazwa ciągu ;
int wiek ;
} ;
int główny ( próżnia ) {
struktura Informacje str ;
P. nazwa = 'Zainab' ;
P. wiek = 23 ;
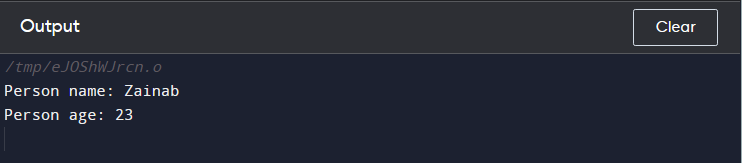
cout << 'Imię osoby: ' << P. nazwa << koniec ;
cout << 'Wiek osoby: ' << P. wiek << koniec ;
powrót 0 ;
}
Kod definiuje strukturę o nazwie Informacje z dwoma atrybutami: imieniem i wiekiem. W głównej funkcji nowy Informacje tworzony jest obiekt i przypisywana jest jego nazwa i wiek. Na koniec wartości tych pól są drukowane w konsoli za pomocą cout.
Klasyfikacja struktury danych w C++
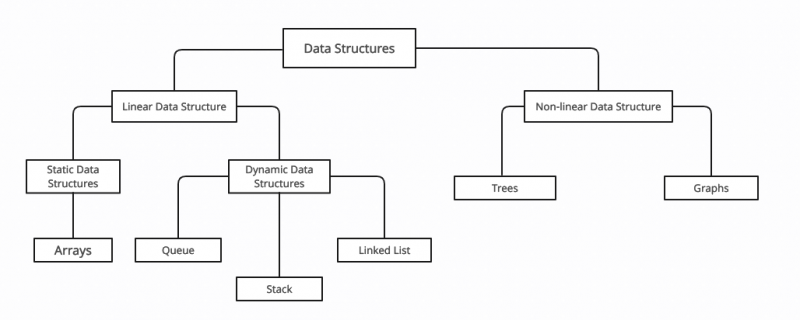
W C++ tzw struktura danych dzieli się na dwie szerokie kategorie: Liniowe i nieliniowe struktury danych . Struktury danych są podzielone na podstawie następujących cech:
| Charakterystyka | Wyjaśnienie | Przykład |
| Liniowy | Dane są ułożone w sekwencji liniowej | Tablice |
| Nieliniowy | Pozycje danych nie są w sekwencji liniowej | Wykres, drzewo |
| Statyczny | Lokalizacja, rozmiar i pamięć są stałe | Tablice |
| Dynamiczny | Rozmiar zmienia się w zależności od wykonania programu | Połączona lista |
| Jednorodny | Przedmioty są tego samego typu | Tablice |
| Niejednorodny | Elementy mogą, ale nie muszą, być tego samego typu | Struktury |
Kategorie struktur danych w C++ to:
1: Tablice
Tablice to najbardziej podstawowe struktury danych w C++. Tablica to grupa elementów o tym samym typie danych. Tablice ułatwiają wykonywanie operacji na całym zbiorze danych. Wartości przechowywane w tablicach są znane jako elementy.
2: Połączona lista
Elementy danych na liście Połączone są połączone za pomocą węzłów. Każdy węzeł ma adres i dane następnego węzła. Najlepiej nadają się do dodawania i usuwania węzłów. Listy połączone mają dwa typy, jeden to listy pojedyncze, a drugi to listy podwójnie połączone. Na liście pojedynczo połączonej poprzedni węzeł ma dane węzła następującego po nim, ale następny węzeł nie jest świadomy poprzedniego węzła. Na podwójnie połączonej liście kierunek jest zarówno do przodu, jak i do tyłu.
3: Stosy
Stosy to abstrakcyjny typ danych zgodny z zasadą LIFO (Last in First Out). Ta reguła oznacza, że element wstawiony jako ostatni zostanie usunięty jako pierwszy. Są one używane z rekurencyjnymi algorytmami śledzenia wstecznego.
4: Ogony
Kolejki są również abstrakcyjnym typem danych i są zgodne z zasadą FIFO (pierwsze weszło i pierwsze wyszło). Ta reguła oznacza, że element wstawiony jako pierwszy zostanie usunięty jako pierwszy. Są pomocne przy obsłudze interpretacji systemowych w czasie rzeczywistym.
5: Drzewa
Drzewa to zestaw nieliniowych struktur danych z wieloma węzłami. Pozwala tylko na jedną krawędź z dwoma wierzchołkami.
6: Wykresy
W grafie każdy węzeł jest wierzchołkiem, a każdy wierzchołek jest połączony z innym wierzchołkiem za pomocą krawędzi. Sfery to wierzchołki, a strzałki to krawędzie, służą do realizacji rzeczywistych scenariuszy lub sieci neuronowych. Grafy mają trzy różne typy: graf nieskierowany, graf dwukierunkowy i graf ważony.
Operacje wykonywane na strukturach danych
Na strukturach danych w C++ możemy wykonywać następujące funkcje:
- Wstawianie nowych elementów danych do struktur danych.
- Usunięcie istniejących elementów danych ze struktury danych.
- Wyświetl wszystkie elementy danych w strukturze danych.
- Wyszukaj określony element w strukturze danych.
- Ułóż wszystkie elementy w porządku rosnącym lub malejącym.
- Połącz elementy z dwóch struktur danych i utwórz nową.
Dolna linia
Struktury danych w C++ są sposobem wydajnej obsługi danych, aby można było uzyskać do nich dostęp. Ważne jest, aby wybrać odpowiednią strukturę danych dla swojego projektu, jeśli chcesz dodawać dane sekwencyjnie, wybierz tablice. Zrozumienie koncepcji struktury danych pomoże opanować sztukę programowania i projektowania algorytmów.