Skalowalność
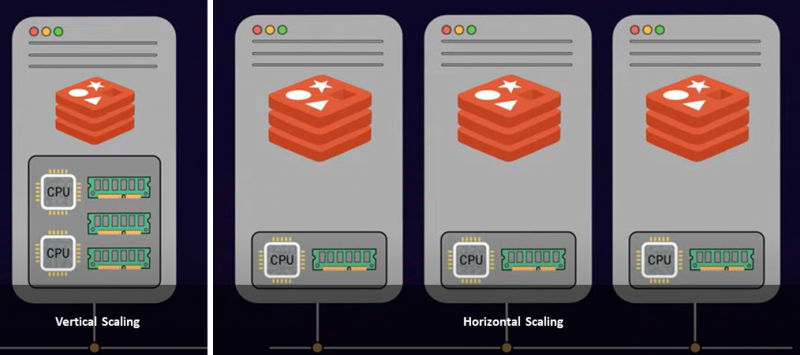
Istnieją dwa popularne podejścia do skalowania serwera: skalowanie w pionie i skalowanie w poziomie. Skalowanie w pionie lub skalowanie w górę polega na dodaniu do serwera większej mocy i zasobów, takich jak więcej procesorów, pamięci i pamięci masowej, co jest kosztowne. Z drugiej strony skalowanie w poziomie polega na dodawaniu wielu węzłów do istniejącej puli zasobów. Nazywa się to skalowaniem w poziomie. Tak więc, w oparciu o twoje ograniczenia i wymagania, od ciebie zależy posiadanie jednej większej instancji serwera lub wdrożenie wielu węzłów serwera.
Załóżmy, że masz 100 GB pamięci RAM i potrzebujesz przechowywać 200 GB danych. W takim przypadku masz dwie możliwości:
- Zwiększ skalę, dodając więcej pamięci RAM do systemu
- Zwiększ skalę, dodając kolejną instancję serwera ze 100 GB pamięci RAM
Jeśli osiągnąłeś maksymalny limit pamięci RAM w swojej infrastrukturze, skalowanie w poziomie jest idealnym podejściem. Ponadto skalowanie w poziomie znacznie zwiększy przepustowość bazy danych.
Dzielenie Redisa
Wiadomo, że Redis działa na jednym wątku. Tak więc Redis nie jest w stanie wykorzystać wielu rdzeni procesora serwera do przetwarzania poleceń. Dlatego dodanie większej liczby rdzeni procesora nie zapewnia dużej przepustowości ani wydajności w Redis. Inaczej jest w przypadku dzielenia danych na wiele instancji serwera. Dodanie kilku serwerów i dystrybucja zbioru danych między nimi umożliwia równoległe przetwarzanie żądań klientów, co zwiększa przepustowość. Ponadto ogólna wydajność może wzrosnąć prawie liniowo.
Takie podejście do dzielenia lub dystrybucji danych między wiele serwerów z myślą o skalowaniu nazywa się dzielenie . Wszystkie serwery, które przechowują części danych, są nazywane odłamki .
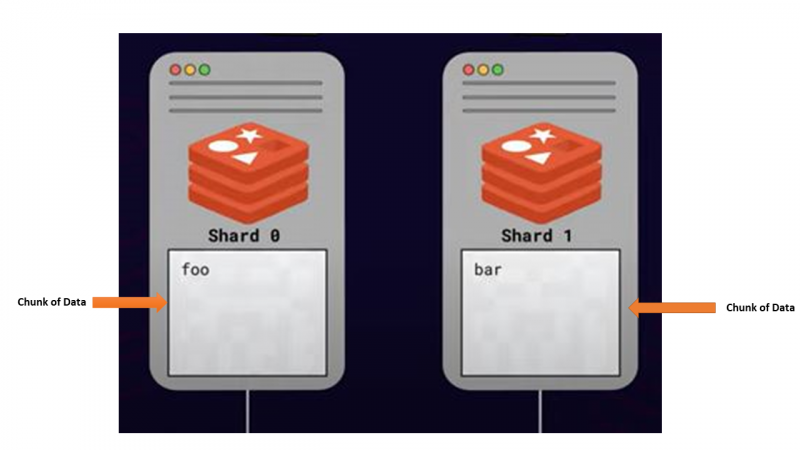
Jak odbywa się dzielenie — dzielenie algorytmiczne
Jednym z głównych problemów związanych z shardingiem było zlokalizowanie danego klucza wśród wielu węzłów Redis. Ponieważ dany klucz może być przechowywany w dowolnych dostępnych fragmentach, wysyłanie zapytań do wszystkich fragmentów w celu znalezienia określonego klucza nie jest najlepszą opcją. Powinien więc istnieć sposób na mapowanie każdego klucza do określonego odłamka, a Redis używa algorytmicznej strategii shardingu.
Najczęstszym podejściem jest obliczenie wartości skrótu przy użyciu nazwy klucza Redis i modulo. Następnie podziel to przez dostępne fragmenty Redis w systemie.
HASH_SLOT = CRC16 (klucz) mod 16384Jest to całkiem dobre rozwiązanie, o ile łączna liczba odłamków jest stała. Za każdym razem, gdy dodajesz nową instancję serwera Reids, wynikowa wartość dla danego klucza może się zmienić, ponieważ wzrosła całkowita liczba odłamków. Skończy się to zapytaniem o niewłaściwy fragment Redis. Dlatego należy postępować zgodnie z procesem reshardingu, obliczając nowy shard dla każdego klucza i przesyłając dane na właściwy serwer, co jest uciążliwym i nietrywialnym zadaniem, jeśli całkowita liczba shardów rośnie od czasu do czasu.
Redis używa nowej jednostki logicznej o nazwie a gniazdo haszujące aby zapobiec temu problemowi. Dla danego fragmentu dostępnych jest kilka miejsc na skróty, a jedno miejsce na skróty może przechowywać wiele kluczy Redis. W klastrze bazy danych Redis znajduje się 16384 miejsc na skróty, które pozostają niezmienione. Podział modulo odbywa się za pomocą liczby miejsc hash zamiast liczby odłamków. Zapewnia prawidłową pozycję gniazda skrótu dla określonego klucza, nawet gdy liczba odłamków wzrosła. Upraszcza proces reshardingu, przenosząc gniazda skrótu z jednego fragmentu do nowego, który dzieli dane między różne instancje Redis zgodnie z wymaganiami.
Korzyści z dzielenia Redis
Dzielenie na fragmenty Redis zapewnia kilka korzyści systemowi bazy danych przy minimalnych zmianach.
Wysoka przepustowość
Ponieważ Redis jest jednowątkowy, przetwarzanie wielu żądań klientów nie może być przetwarzane równolegle przy użyciu wielu rdzeni procesora. Tak więc dodanie nowych fragmentów lub instancji serwera gwarantuje, że możesz równolegle wykonywać operacje Redis. Zwiększa liczbę operacji na sekundę w bazie danych Redis, co ostatecznie zapewnia wysoką przepustowość.
Duża dostępność
Dzięki podejściu dzielenia na fragmenty klaster Redis może skonfigurować architekturę master-replica, która zapewnia wysoką dostępność i trwałość.
Przeczytaj repliki
Dzielenie na fragmenty umożliwia zachowanie dokładnej kopii danych i zapewnianie operacji odczytu za pośrednictwem oddzielnych instancji Redis, co zwiększa wydajność wykonywania zapytań odczytu.
Oprócz tych korzyści sharding może powodować sytuacje podziału mózgu, gdy masz parzystą liczbę shardów w klastrze Redis. Dlatego zaleca się przechowywanie nieparzystej liczby odłamków w klastrze Redis.
Wniosek
Podsumowując, sharding Redis polega na dzieleniu danych między wiele serwerów, co umożliwia skalowanie i wysoką przepustowość bazy danych. Jak omówiono, Redis używa algorytmicznej strategii dzielenia na fragmenty, aby kierować żądania klientów do właściwego fragmentu. Ma to pewne wady, gdy zwiększa się całkowita liczba odłamków. Tak więc, zamiast całkowitej liczby odłamków, Redis używa liczby miejsc mieszania, aby obliczyć odpowiedni odłamek. Dzięki wprowadzeniu dzielenia na fragmenty bazy danych Redis zapewniają wysoką dostępność, wysoką przepustowość i wysoką wydajność.