Przykład 1: Uzyskaj pozycję wzorca z ciągu znaków za pomocą funkcji Grep() w języku R
Aby wyodrębnić pozycję określonego wzorca z ciągu, używana jest funkcja grep() języka R.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=PRAWDA, wartość=FAŁSZ)Tutaj używamy funkcji grep(), w której wzorzec „+i” jest określony jako argument do dopasowania w wektorze ciągów. Ustawiamy wektory znaków zawierające cztery ciągi znaków. Następnie ustawiamy argument „perl” na wartość TRUE, co wskazuje, że R używa biblioteki wyrażeń regularnych kompatybilnej z Perlem, a parametr „value” jest określony wartością „FALSE”, która służy do pobierania indeksów elementów w wektorze pasującym do wzorca.
Pozycja wzorca „+i” z każdego ciągu znaków wektorowych jest wyświetlana w następującym wyniku:

Przykład 2: Dopasuj wzorzec za pomocą funkcji Gregexpr() w R
Następnie pobieramy pozycję indeksu wraz z długością konkretnego ciągu w R za pomocą funkcji gregexpr().
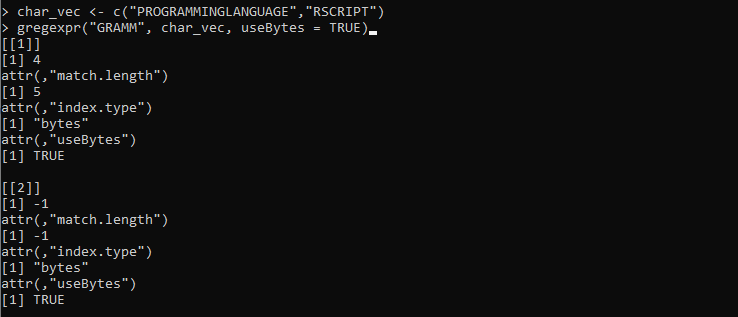
char_vec <- c('JĘZYK PROGRAMOWANIA','RSKRYPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
Tutaj ustawiamy zmienną „char_vect”, w której ciągi znaków mają różne znaki. Następnie definiujemy funkcję gregexpr(), która pobiera wzór ciągu „GRAMM” w celu dopasowania go do ciągów przechowywanych w pliku „char_vec”. Następnie ustawiamy parametr useBytes na wartość „TRUE”. Ten parametr wskazuje, że dopasowanie powinno być osiągane bajt po bajcie, a nie znak po znaku.
Poniższe dane wyjściowe pobrane z funkcji gregexpr() reprezentują indeksy i długość obu ciągów wektorowych:
Przykład 3: Policz całkowitą liczbę znaków w ciągu za pomocą funkcji Nchar() w języku R
Metoda nchar(), którą zaimplementujemy poniżej, pozwala nam również określić, ile znaków zawiera ciąg znaków:
Res <- nchar('Policz każdy znak')drukuj (rozdzielczość)
Tutaj wywołujemy metodę nchar(), która jest ustawiana w zmiennej „Res”. Metoda nchar() udostępnia długi ciąg znaków, który jest zliczany przez metodę nchar() i podaje liczbę znaków licznika w określonym ciągu. Następnie przekazujemy zmienną „Res” do metody print(), aby zobaczyć wyniki metody nchar().
Wynik jest odbierany w następującym wyniku, który pokazuje, że określony ciąg zawiera 20 znaków:

Przykład 4: Wyodrębnij podciąg z ciągu za pomocą funkcji Substring() w języku R
Używamy metody substring() z argumentami „start” i „stop”, aby wyodrębnić konkretny podciąg z ciągu.
str <- substring('RANEK', 2, 4)drukuj(str)
Tutaj mamy zmienną „str”, w której wywoływana jest metoda substring(). Metoda substring() jako pierwszy argument przyjmuje ciąg „MORNING”, jako drugi argument wartość „2”, co oznacza, że ma zostać wyodrębniony drugi znak z ciągu, a wartość argumentu „4” wskazuje, że czwarty znak ma zostać wyodrębniony. Metoda substring() wyodrębnia znaki z ciągu znaków pomiędzy określoną pozycją.
Poniższe dane wyjściowe wyświetlają wyodrębniony podciąg, który znajduje się pomiędzy drugą a czwartą pozycją w ciągu:

Przykład 5: Łączenie ciągu za pomocą funkcji Paste() w języku R
Funkcja paste() w R jest również używana do manipulacji ciągami, która łączy określone ciągi poprzez oddzielanie ograniczników.
msg1 <- 'Treść'msg2 <- 'Pisanie'
wklej(msg1, msg2)
Tutaj podajemy ciągi odpowiednio do zmiennych „msg1” i „msg2”. Następnie używamy metody paste() języka R, aby połączyć dostarczony ciąg znaków w jeden ciąg. Metoda paste() przyjmuje zmienną strings jako argument i zwraca pojedynczy ciąg znaków z domyślną spacją pomiędzy ciągami.
Po wykonaniu metody paste() wynikiem jest pojedynczy ciąg znaków ze spacją.

Przykład 6: Modyfikowanie ciągu za pomocą funkcji Substring() w języku R
Co więcej, możemy również zaktualizować ciąg, dodając podciąg lub dowolny znak do ciągu za pomocą funkcji substring() i następującego skryptu:
str1 <- „Bohaterowie”podciąg (str1, 5, 6) <- „ic”
cat(' Zmodyfikowany ciąg:', str1)
Ustawiamy ciąg „Heroes” w zmiennej „str1”. Następnie wdrażamy metodę substring(), w której określono „str1” wraz z wartościami indeksu „start” i „stop” podłańcucha. Do metody substring() przypisany jest podciąg „iz”, który umieszczany jest na pozycji określonej w funkcji dla danego ciągu. Następnie używamy funkcji cat() języka R, która reprezentuje zaktualizowaną wartość ciągu.
Dane wyjściowe wyświetlające ciąg znaków są aktualizowane nowym za pomocą metody substring ():

Przykład 7: Formatowanie ciągu za pomocą funkcji Format() w języku R
Jednak operacja manipulacji ciągiem w języku R obejmuje również odpowiednie formatowanie ciągu. W tym celu używamy funkcji format(), dzięki której można wyrównać ciąg i ustawić szerokość konkretnego ciągu.
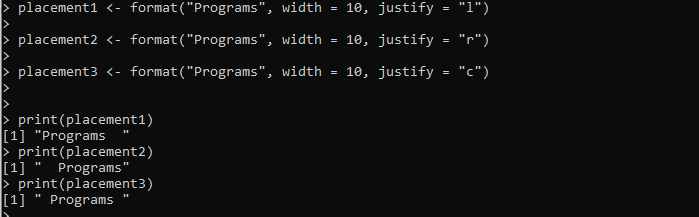
umieszczenie1 <- format('Programy', szerokość = 10, justify = 'l')umieszczenie2 <- format('Programy', szerokość = 10, justify = 'r')
umieszczenie3 <- format('Programy', szerokość = 10, justify = 'c')
drukuj (umieszczenie 1)
drukuj (umieszczenie2)
drukuj (umieszczenie3)
Tutaj ustawiamy zmienną „placement1”, która jest dostarczana z metodą format(). Do metody format() przekazujemy ciąg „programy” do sformatowania. Szerokość jest ustawiana, a wyrównanie ciągu jest ustawiane w lewo za pomocą argumentu „justify”. Podobnie tworzymy dwie kolejne zmienne, „placement2” i „placement2” i stosujemy metodę format(), aby odpowiednio sformatować podany ciąg znaków.
W wynikach zostaną wyświetlone trzy style formatowania tego samego ciągu na poniższym obrazku, w tym wyrównanie do lewej, prawej i do środka:
Przykład 8: Przekształć ciąg znaków na małe i wielkie litery w języku R
Dodatkowo możemy również przekształcić ciąg znaków na małe i wielkie litery, używając funkcji tolower() i toupper() w następujący sposób:
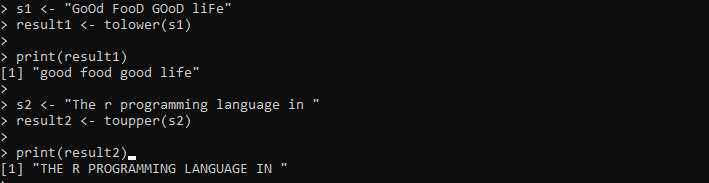
s1 <- 'Dobre jedzenie, dobre życie'wynik1 <- toniższy(s1)
drukuj (wynik 1)
s2 <- 'Język programowania r w '
wynik2 <- toupper(s2)
drukuj(wynik2)
Tutaj podajemy ciąg zawierający wielkie i małe litery. Następnie ciąg znaków jest przechowywany w zmiennej „s1”. Następnie wywołujemy metodę tolower() i przekazujemy do niej ciąg „s1”, aby przekształcić wszystkie znaki w ciągu na małe litery. Następnie wypisujemy wyniki metody tolower(), które zapisane są w zmiennej „result1”. Następnie ustawiamy kolejny ciąg znaków w zmiennej „s2”, która zawiera wszystkie znaki pisane małymi literami. Stosujemy metodę toupper() do tego ciągu „s2”, aby przekształcić istniejący ciąg na wielkie litery.
Dane wyjściowe wyświetlają oba ciągi w określonym przypadku na poniższym obrazku:
Wniosek
Nauczyliśmy się różnych sposobów zarządzania ciągami i analizowania ich, co nazywa się manipulacją ciągami. Wyodrębniliśmy pozycję znaku z ciągu, połączyliśmy różne ciągi i przekształciliśmy ciąg znaków w określoną wielkość liter. Ponadto sformatowaliśmy ciąg, zmodyfikowaliśmy ciąg i wykonujemy tutaj różne inne operacje w celu manipulacji ciągiem.