Ten przewodnik zilustruje proces wykorzystania pamięci encji w LangChain.
Jak korzystać z pamięci jednostek w LangChain?
Jednostka służy do przechowywania kluczowych faktów przechowywanych w pamięci w celu wydobycia ich na żądanie człowieka za pomocą zapytań/podpowiedzi. Aby poznać proces wykorzystania pamięci encji w LangChain wystarczy odwiedzić poniższy poradnik:
Krok 1: Zainstaluj moduły
Najpierw zainstaluj moduł LangChain za pomocą polecenia pip, aby uzyskać jego zależności:
pip zainstaluj langchain
Następnie zainstaluj moduł OpenAI, aby uzyskać biblioteki do budowania LLM i modeli czatów:
pip zainstaluj openai
Skonfiguruj środowisko OpenAI za pomocą klucza API, który można wyodrębnić z konta OpenAI:
import Ty
import przejść dalej
Ty . około [ „OPENAI_API_KEY” ] = przejść dalej . przejść dalej ( „Klucz API OpenAI:” )
Krok 2: Korzystanie z pamięci jednostek
Aby skorzystać z pamięci encji, zaimportuj wymagane biblioteki do zbudowania LLM przy użyciu metody OpenAI():
z łańcuch językowy. llms import OpenAIz łańcuch językowy. pamięć import Pamięć jednostki konwersacji
llm = OpenAI ( temperatura = 0 )
Następnie zdefiniuj pamięć zmienną przy użyciu metody ConversationEntityMemory() w celu uczenia modelu przy użyciu zmiennych wejściowych i wyjściowych:
pamięć = Pamięć jednostki konwersacji ( llm = llm )_wejście = { 'wejście' : „Joe Are Root robi projekt” }
pamięć. zmienne_pamięci_ładowania ( _wejście )
pamięć. zapisz_kontekst (
_wejście ,
{ 'wyjście' : „Świetnie! Co to za projekt?” }
)
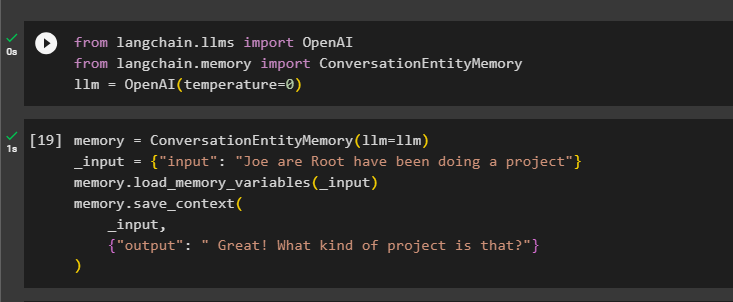
Teraz przetestuj pamięć za pomocą zapytania/podpowiedzi w pliku wejście zmienną, wywołując metodę loading_memory_variables():
pamięć. zmienne_pamięci_ładowania ( { 'wejście' : „kto jest rootem” } ) 
Teraz podaj trochę więcej informacji, aby model mógł dodać do pamięci jeszcze kilka elementów:
pamięć = Pamięć jednostki konwersacji ( llm = llm , wiadomości_powrotne = PRAWDA )_wejście = { 'wejście' : „Joe Are Root robi projekt” }
pamięć. zmienne_pamięci_ładowania ( _wejście )
pamięć. zapisz_kontekst (
_wejście ,
{ 'wyjście' : „Świetnie! Co to za projekt” }
)
Wykonaj następujący kod, aby uzyskać dane wyjściowe przy użyciu jednostek przechowywanych w pamięci. Jest to możliwe poprzez wejście zawierający zachętę:
pamięć. zmienne_pamięci_ładowania ( { 'wejście' : „kim jest Joe” } ) 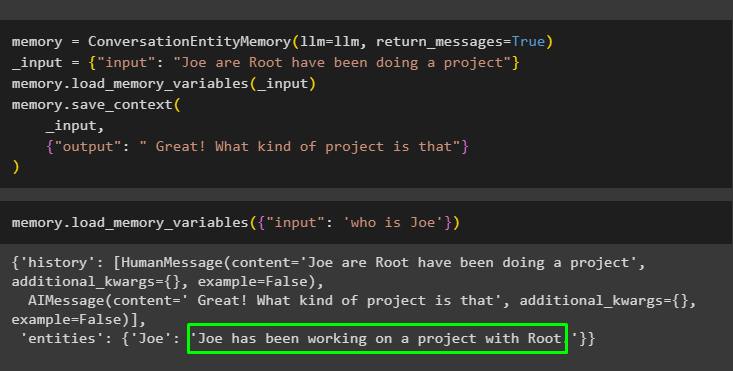
Krok 3: Używanie pamięci jednostek w łańcuchu
Aby użyć pamięci encji po zbudowaniu łańcucha, po prostu zaimportuj wymagane biblioteki, korzystając z następującego bloku kodu:
z łańcuch językowy. więzy import Łańcuch Rozmówz łańcuch językowy. pamięć import Pamięć jednostki konwersacji
z łańcuch językowy. pamięć . podpowiedź import ENTITY_MEMORY_CONVERSATION_TEMPLATE
z pydantyczny import Model podstawowy
z pisanie na maszynie import Lista , Dykt , Każdy
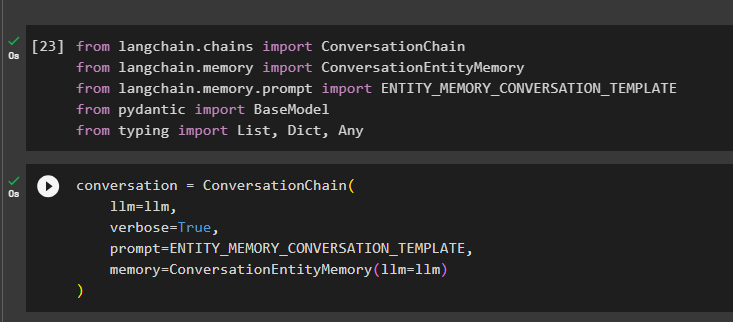
Zbuduj model konwersacji za pomocą metody ConversationChain(), używając argumentów takich jak llm:
rozmowa = Łańcuch Rozmów (llm = llm ,
gadatliwy = PRAWDA ,
podpowiedź = ENTITY_MEMORY_CONVERSATION_TEMPLATE ,
pamięć = Pamięć jednostki konwersacji ( llm = llm )
)
Wywołaj metodę konwersacji.predict() z danymi wejściowymi zainicjowanymi przez zachętę lub zapytanie:
rozmowa. przewidywać ( wejście = „Joe Are Root robi projekt” ) 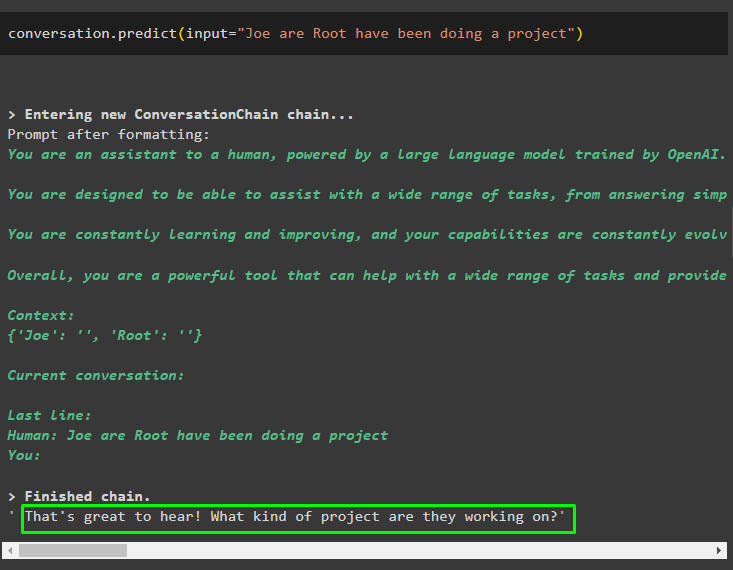
Teraz uzyskaj osobne dane wyjściowe dla każdej jednostki opisujące informacje na jej temat:
rozmowa. pamięć . sklep_encji . sklep 
Użyj danych wyjściowych modelu, aby podać dane wejściowe, aby model mógł przechowywać więcej informacji o tych jednostkach:
rozmowa. przewidywać ( wejście = „Próbują dodać do Langchain bardziej złożone struktury pamięci” ) 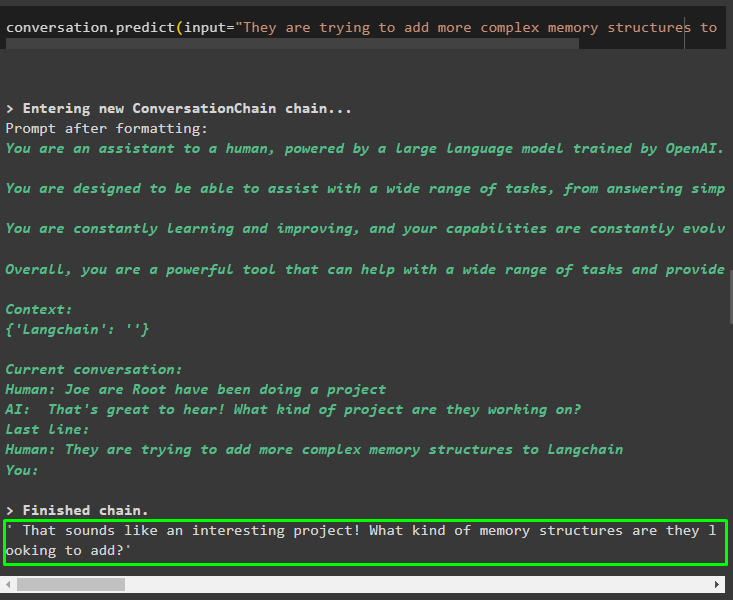
Po podaniu informacji przechowywanych w pamięci wystarczy zadać pytanie, aby wydobyć konkretne informacje o podmiotach:
rozmowa. przewidywać ( wejście = „Co wiesz o Joe i Roocie” ) 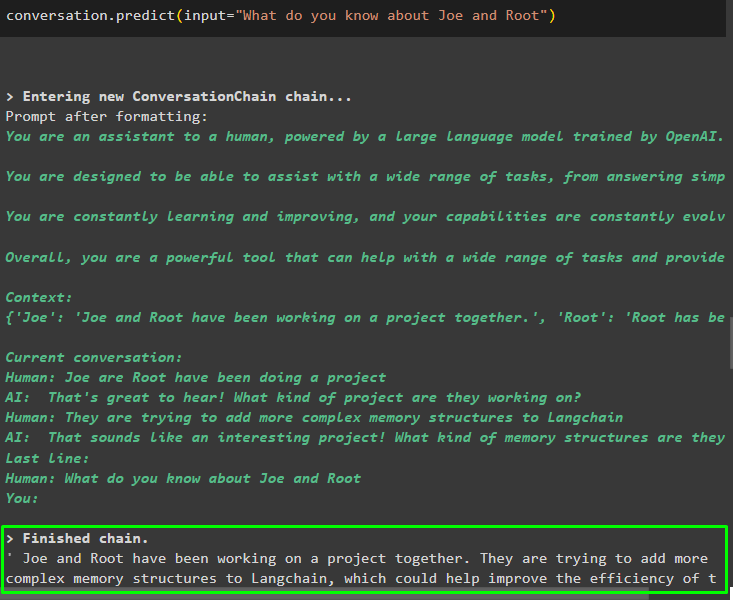
Krok 4: Testowanie magazynu pamięci
Użytkownik może bezpośrednio sprawdzić zasoby pamięci, aby uzyskać przechowywane w nich informacje, korzystając z następującego kodu:
z wydrukować import wydrukowaćwydrukować ( rozmowa. pamięć . sklep_encji . sklep )
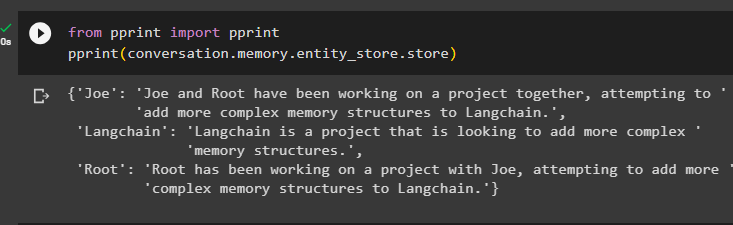
Podaj więcej informacji do zapisania w pamięci, ponieważ więcej informacji daje dokładniejsze wyniki:
rozmowa. przewidywać ( wejście = „Root założył firmę o nazwie HJRS” ) 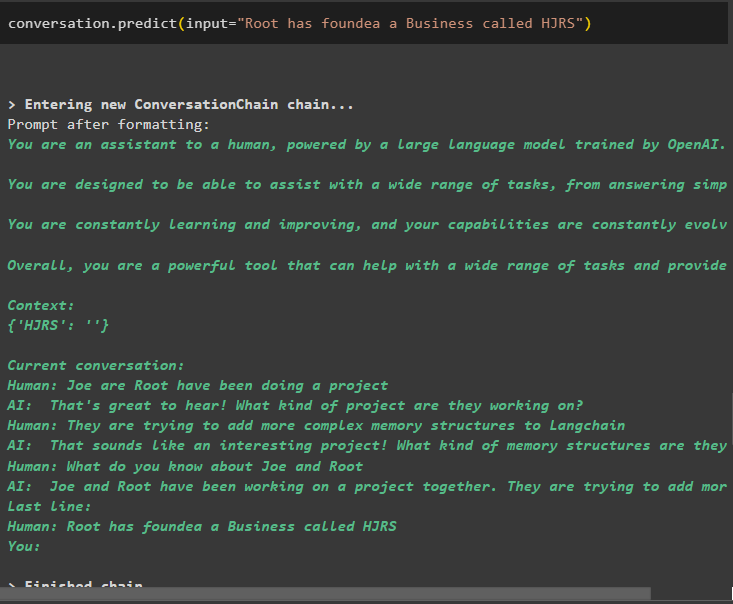
Wyodrębnij informacje z magazynu pamięci po dodaniu większej ilości informacji o jednostkach:
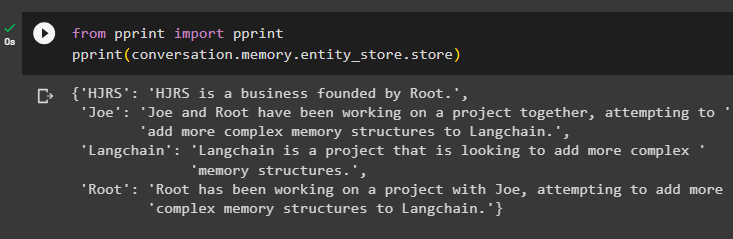
z wydrukować import wydrukowaćwydrukować ( rozmowa. pamięć . sklep_encji . sklep )
Pamięć zawiera informacje o wielu jednostkach, takich jak HJRS, Joe, LangChain i Root:
Teraz wyodrębnij informacje o konkretnym obiekcie za pomocą zapytania lub podpowiedzi zdefiniowanych w zmiennej wejściowej:
rozmowa. przewidywać ( wejście = „Co wiesz o Root” ) 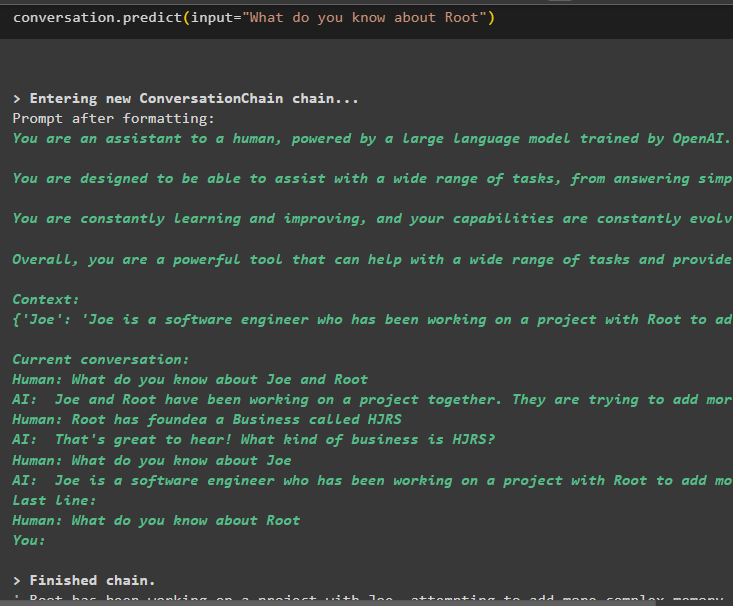
Chodzi o wykorzystanie pamięci jednostek przy użyciu frameworka LangChain.
Wniosek
Aby korzystać z pamięci encji w LangChain, wystarczy zainstalować wymagane moduły, aby zaimportować biblioteki wymagane do budowy modeli po skonfigurowaniu środowiska OpenAI. Następnie zbuduj model LLM i przechowuj encje w pamięci, podając informacje o encjach. Użytkownik może również wyodrębnić informacje za pomocą tych bytów i zbudować te wspomnienia w łańcuchach z mieszanymi informacjami o bytach. W tym poście szczegółowo omówiono proces wykorzystania pamięci encji w LangChain.