Składnia
Pełna składnia tej metody „read_json()” jest podana poniżej.
pandy. read_json ( ścieżka , Orient = Wartość , rodzaj = 'rama' , dtype = Wartość , konwertuj_osie = Wartość , konwertuj_daty = Prawdziwe , keep_default_dates = Prawdziwe , numpy = Fałszywy , precyzyjne_zmienne = Fałszywy , data_jednostka = Wartość , kodowanie = Wartość , kodowanie_błędy = 'rygorystyczny' , linie = Fałszywy , wielkość kawałka = Wartość , kompresja = 'wywnioskować' , nows = Wartość , opcje_magazynu = Wartość )Przykład 01
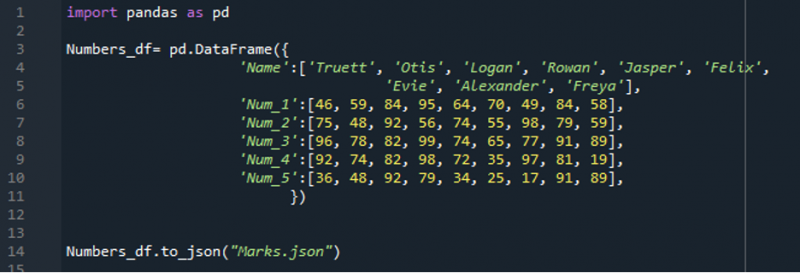
Te przykłady, które są przedstawione w tym przewodniku, są wykonywane w aplikacji „Spyder”. Przed użyciem metody „read_json()” najpierw generujemy plik JSON, którego dane odczytamy za pomocą metody „read_json()”. Omówiliśmy tutaj również, jak utworzyć plik JSON w „pandach”. Tutaj widać, że najpierw tworzymy DataFrame za pomocą metody „pd.DataFrame()”.
Następnie dodajemy „Nazwa, Num_1, Num_2, Num_3, Num_4 i Num_5” jako kolumnę tego DataFrame, a także wstawiamy niektóre dane w tych kolumnach. Następnie używamy metody „to_json()”, która pomaga w konwersji tego DataFrame do JSON. Wpisujemy nazwę, jaką chcemy nadać plikowi „JSON”, w którym będą przechowywane dane JSON. Nazwa, którą tu podajemy to „Marks.json”. Czyli po wykonaniu tego kodu zostanie utworzony plik JSON o nazwie „Marks.json” i będzie przechowywał dane w JSON, które tutaj wprowadziliśmy.
Po wykonaniu tego kodu przez naciśnięcie „Shift+Enter” tworzony jest plik JSON, a tutaj plik JSON jest również pokazany poniżej. To jest plik JSON, który otrzymujemy po wykonaniu powyższego kodu. Teraz pójdziemy dalej i odczytamy ten plik JSON za pomocą metody „read_json()”.

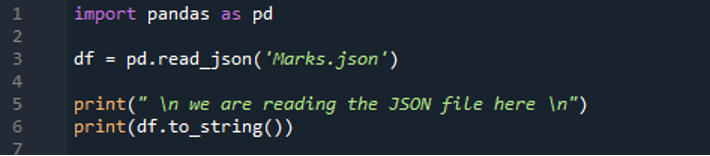
Teraz najpierw „importujemy” bibliotekę „pandy”, ponieważ musimy użyć tutaj metody „read_json()”, która jest metodą „pand”. Importujemy „pandy jako pd”. Poniżej wykorzystujemy metodę „read_json()” i umieszczamy nazwę pliku, którego dane chcemy odczytać. Tutaj umieszczamy plik, który stworzyliśmy powyżej, więc odczytamy dane tego pliku JSON. Ścieżkę do pliku przekazujemy w tej metodzie „read_json()”, czyli „Marks.json”, a także przypisujemy tę funkcję do zmiennej „df”. Tak więc po odczytaniu tego pliku JSON dane z pliku JSON są przechowywane w tej zmiennej „df”. Teraz wypisujemy te dane za pomocą „print()”, a także dodajemy metodę „to_string()” ze zmienną „df”. Ta metoda „to_string()” pomaga nam w drukowaniu DataFrame. Wydrukuje dane z pliku JSON w formacie DataFrame.
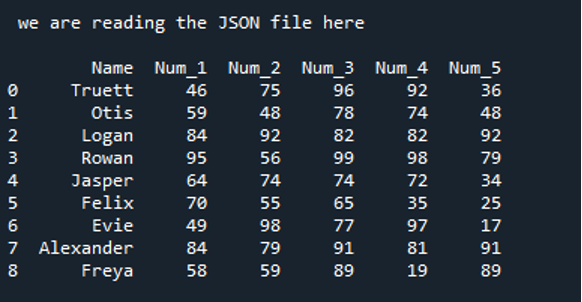
Dane przechowywane w powyższym pliku JSON są tutaj renderowane jako DataFrame poniżej. Możesz zauważyć, że wszystkie dane z pliku JSON są konwertowane na DataFrame i wyświetlane w danych wyjściowych.
Przykład 02
Możemy również odczytać ciąg JSON za pomocą metody „read_json()”. Po zaimportowaniu „pand” generujemy tutaj ciąg i zapisujemy go w zmiennej „my_str”. Ciąg, który tutaj stworzyliśmy zawiera dane, które są „Tematem”, a my umieszczamy nazwę podmiotu, który jest „Angielski”. Następnie dodajemy „Zapłać”, czyli tutaj „25000”, a także „Dni”, czyli „70 dni”. Po tym wszystkim dodajemy również „Rabat”, który wynosi tutaj „1000”. Tutaj jest uzupełniany ciąg JSON.
Teraz odczytujemy ten ciąg JSON za pomocą metody „read_json()” „pandy” i umieszczamy nazwę zmiennej, w której przechowywany jest ciąg. Nazwa tej zmiennej to „my_str” i dodajemy ją tutaj jako pierwszy parametr metody „read_json()”. Następnie dodajemy kolejny parametr, który jest tutaj parametrem „orient” i ustawiamy go na „rekordy”. Następnie dodajemy to „my_df” w metodzie „print()”, aby wyrenderowało się na terminalu po uruchomieniu tego kodu.

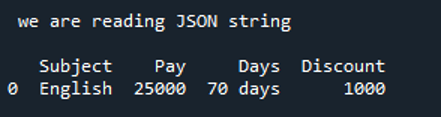
Dane, które otrzymamy po odczytaniu ciągu JSON, wyświetlają się poniżej. Tutaj dane są renderowane w DataFrame, które wprowadziliśmy jako ciąg JSON w naszym kodzie.
Przykład 03
Tutaj tworzymy kolejny ciąg JSON. Musisz pamiętać, że sznurek musisz umieścić tylko w jednej linii. Jeśli dodamy pozostałe dane ciągu w nowej linii, pojawi się komunikat o błędzie. Tak więc musisz napisać cały ciąg tylko w jednym wierszu. Tutaj ciąg JSON jest tworzony i przechowywany w zmiennej „string”. Następnie odczytujemy ciąg JSON za pomocą metody „read_json()”. Dodajemy „ciąg”, w którym przechowywany jest ciąg JSON w tej metodzie „read_json()”. Po przeczytaniu przechowujemy ten ciąg w zmiennej „JSON_Data”. Następnie używamy „print()” i dodajemy do niego „JSON_Data”, co pomoże w renderowaniu tego.

Poniżej renderowana jest ramka DataFrame, którą uzyskaliśmy po odczytaniu ciągu JSON. Data, którą wprowadziliśmy w naszym kodzie jako ciąg JSON, jest tutaj wyświetlana jako DataFrame.
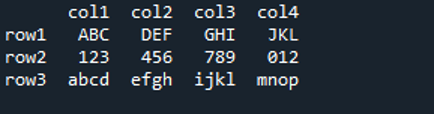
Przykład 04
To jest nasz plik JSON i zastosujemy metodę „read_json()” do tego pliku JSON. Odczyta dane znajdujące się w tym pliku JSON i wyrenderuje te dane w DataFrame.

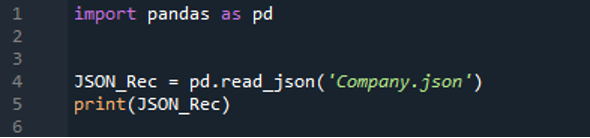
Teraz, ponieważ musimy użyć metody „read_json()” biblioteki „pandas”, musimy najpierw „zaimportować” bibliotekę. Pandy są importowane jako „pd”. Umieściliśmy plik, który pokazaliśmy powyżej, abyśmy mogli odczytać dane z tego pliku JSON. Ścieżka do pliku „Company.json” jest przekazywana do metody „read_json()”, a funkcja ta jest również przypisywana do zmiennej „JSON_Rec”. Informacje z pliku JSON są więc umieszczane w zmiennej „JSON_Rec” po jej odczytaniu. Teraz wstawiamy „print()” i dodajemy do niego „JSON_Rec”.
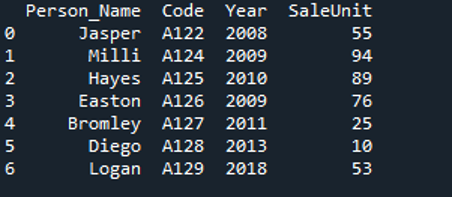
Dane zawarte we wspomnianym powyżej pliku JSON są wyświetlane poniżej jako DataFrame. Widać, że dane wyjściowe wyświetlają ramkę DataFrame z przekonwertowanymi na nią wszystkimi danymi z pliku JSON.
Wniosek
W tym przewodniku szczegółowo wyjaśniliśmy metodę „read_json()” dla „pand”. Przedstawiliśmy tutaj składnię metody „read_json()”, a także wykorzystaliśmy tę metodę „read_json()” w naszym kodzie „pand”. Przeczytaliśmy ciąg JSON, a także plik JSON za pomocą metody „read_json()” i wyjaśniliśmy, jak utworzyć plik JSON, a następnie jak odczytać ten plik JSON. Wyjaśniliśmy również, jak utworzyć ciąg JSON i jak odczytać ciąg JSON za pomocą metody „read_json()” w tym przewodniku.