Chociaż JavaScript jest językiem jednowątkowym, Node.js może przypisywać zadania systemowi operacyjnemu, umożliwiając mu przetwarzanie wielu zadań jednocześnie. Należy wykonywać kilka zadań jednocześnie, ponieważ operacje w systemie operacyjnym są wielowątkowe. Wywołanie zwrotne powiązane z każdą operacją jest dodawane do kolejki zdarzeń i jest zaplanowane przez Node.js do uruchomienia po zakończeniu określonego zadania.
Aby napisać wydajny i niezawodny kod Node.js, użytkownik musi posiadać solidną wiedzę na temat pętli zdarzeń. Może również pomóc w skutecznym rozwiązywaniu problemów z wydajnością. Pętla zdarzeń w Node.js oszczędza pamięć i pozwala wykonywać wiele czynności na raz, bez konieczności czekania na zakończenie każdej z nich. Termin „asynchroniczny” odnosi się do dowolnej funkcji JavaScript działającej w tle bez blokowania przychodzących żądań.
Zanim przejdziemy bezpośrednio do pętli zdarzeń, przyjrzyjmy się różnym aspektom języka programowania JavaScript.
JavaScript jako asynchroniczny język programowania
Rzućmy okiem na koncepcje programowania asynchronicznego. JavaScript jest używany w aplikacjach internetowych, mobilnych i stacjonarnych, ale należy zauważyć, że JavaScript jest jednowątkowym, synchronicznym językiem programowania komputerowego.
Aby zrozumieć tę koncepcję, podano prosty przykład kodu.
metoda funkcyjna 1 ( ) {
konsola. dziennik ( „Funkcja 1” )
}
metoda funkcyjna 2 ( ) {
konsola. dziennik ( „Funkcja 2” )
}
metoda 1 ( )
metoda 2 ( )
W tym kodzie tworzone są dwie proste funkcje i najpierw wywoływana jest metoda 1, aby najpierw zarejestrować metodę 1, a następnie przejść do następnej.
Wyjście
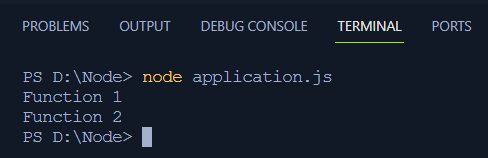
JavaScript jako synchroniczny język programowania
JavaScript jest synchronicznym językiem programowania i wykonuje każdą linię krok po kroku, przechodząc od góry do dołu, przy czym jednocześnie wykonywana jest tylko jedna linia. W przykładzie podanym powyżej, metoda 1 jest najpierw logowana w terminalu, a następnie metoda 2.
JavaScript jako język blokujący
Będąc językiem synchronicznym, javascript ma funkcję blokowania. Nie ma znaczenia, ile czasu zajmie zakończenie trwającego procesu, ale nowy proces nie zostanie rozpoczęty, dopóki poprzedni nie zostanie zakończony. W powyższym przykładzie kodu załóżmy, że w metodzie 1 znajduje się dużo skryptu kodu, niezależnie od tego, ile czasu zajmie to 10 sekund lub minut. Metoda 2 nie zostanie wykonana, dopóki cały kod w metodzie 1 nie zostanie wykonany.
Użytkownicy mogli doświadczyć tego podczas przeglądania. Kiedy aplikacja internetowa jest uruchamiana w przeglądarce w zapleczu, wykonywany jest ogromny fragment kodu, więc przeglądarka wydaje się być zamrożona na jakiś czas, zanim zwróci użytkownikowi dostęp kontrolny. To zachowanie jest znane jako blokowanie. Przeglądarka nie może przyjmować żadnych dalszych żądań przychodzących, dopóki bieżące żądanie nie zostanie przetworzone.
JavaScript jest językiem jednowątkowym
Do uruchomienia programu w JavaScript wykorzystywana jest funkcjonalność wątku. Wątki mogą wykonywać tylko jedno zadanie na raz. Inne języki programowania obsługują wielowątkowość i mogą wykonywać wiele zadań równolegle, javascript zawiera tylko jeden wątek do wykonywania dowolnego skryptu kodu.
Oczekiwanie w JavaScript
Jak wynika z nazwy w tej sekcji, aby móc kontynuować, musimy poczekać na przetworzenie naszej prośby. Oczekiwanie może potrwać kilka minut, podczas których nie są rozpatrywane żadne dalsze prośby. Jeśli skrypt kodu będzie kontynuowany bez czekania, w kodzie wystąpi błąd. Część funkcjonalności ma zostać zaimplementowana w JavaScript, a dokładniej w Node.js, aby kod był asynchroniczny.
Teraz, gdy zrozumieliśmy różne aspekty JavaScriptu, przyjrzyjmy się bliżej synchronii i asynchronii na kilku prostych przykładach.
Synchroniczne wykonanie kodu w JavaScript
Synchroniczny oznacza, że kod jest wykonywany sekwencyjnie lub prościej krok po kroku, zaczynając od góry i przesuwając się w dół linia po linii.
Poniżej podano przykład, który może pomóc zrozumieć:
// aplikacja.jskonsola. dziennik ( 'Jeden' )
konsola. dziennik ( 'Dwa' )
konsola. dziennik ( 'Trzy' )
W tym kodzie znajdują się trzy instrukcje console.log, z których każda coś drukuje. Najpierw pierwsza instrukcja, która wypisze „Jeden” w konsoli, jest wysyłana do stosu wywołań na 1 ms (szacunkowo), a następnie logowana do terminala. Następnie druga instrukcja jest umieszczana na stosie wywołań i teraz czas wynosi 2 ms, po dodaniu jednej z poprzedniej, a następnie rejestruje „Dwa” w konsoli. Na koniec ostatnia instrukcja jest umieszczana na stosie wywołań, na razie czas wynosi 3 ms i rejestruje „Trzy” w konsoli.
Powyższy kod można wykonać wywołując następującą komendę:
aplikacja węzła. jsWyjście
Funkcjonowanie wyjaśniono szczegółowo powyżej i biorąc to pod uwagę, dane wyjściowe są logowane do konsoli w mgnieniu oka:
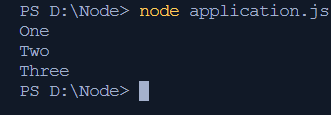
Asynchroniczne wykonanie kodu w JavaScript
Teraz przeanalizujmy ten sam kod, wprowadzając wywołania zwrotne i czyniąc kod asynchronicznym. Powyższy kod można refaktoryzować jako:
// aplikacja.jsfunkcja printOne ( oddzwonić ) {
ustaw limit czasu ( funkcjonować ( ) {
konsola. dziennik ( 'Jeden' ) ;
oddzwonić ( ) ;
} , 1000 ) ;
}
funkcja printTwo ( oddzwonić ) {
ustaw limit czasu ( funkcjonować ( ) {
konsola. dziennik ( 'Dwa' ) ;
oddzwonić ( ) ;
} , 2000 ) ;
}
funkcja printThree ( ) {
ustaw limit czasu ( funkcjonować ( ) {
konsola. dziennik ( 'Trzy' ) ;
} , 3000 ) ;
}
konsola. dziennik ( „Rozpoczęcie programu” ) ;
drukujJeden ( funkcjonować ( ) {
drukujDwa ( funkcjonować ( ) {
wydrukuj Trzy ( ) ;
} ) ;
} ) ;
konsola. dziennik ( „Koniec programu” ) ;
W powyższym kodzie:
- Zadeklarowano trzy funkcje do drukowania „Jeden”, „Dwa” i „Trzy”, każda funkcja ma parametr wywołania zwrotnego, który umożliwia sekwencyjne wykonanie kodu.
- Limit czasu jest ustawiany za pomocą funkcji setTimeout i istnieje instrukcja console.log umożliwiająca drukowanie po określonym opóźnieniu.
- Drukowane są dwa komunikaty „Start programu” i „Koniec programu”, które wskazują początek i koniec programu.
- Program rozpoczyna się wydrukiem „Start programu”, po czym wykonywana jest funkcja printOne z 1 sekundowym opóźnieniem, następnie funkcja printTwo jest wykonywana z 2 sekundowym opóźnieniem, a na koniec funkcja printThree jest wykonywana z 3 sekundowym opóźnieniem opóźnienie.
- Program nie czeka na asynchroniczne wykonanie kodu wewnątrz funkcji setTimeouts, które rejestrują instrukcję „Koniec programu” przed wydrukowaniem Jeden, Dwa i Trzy.
Wyjście
Uruchom powyższy kod, wykonując to polecenie w terminalu:
aplikacja węzła. jsTeraz dane wyjściowe w terminalu będą wyświetlane asynchronicznie jako:
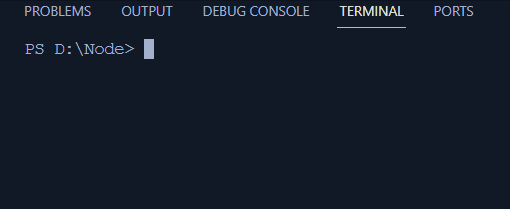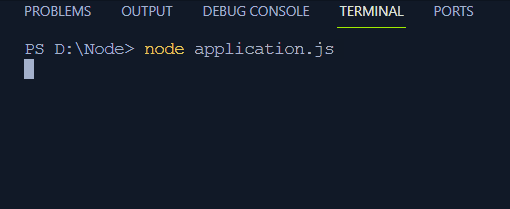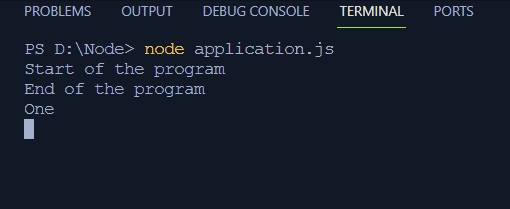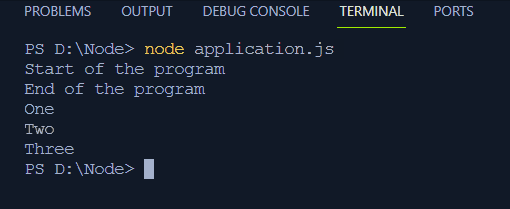
Teraz, gdy mamy już pełną wiedzę na temat wykonywania synchronicznego i asynchronicznego, przejdźmy do ugruntowania naszej koncepcji pętli zdarzeń w Node.js.
Node.js: Mechanizm pętli zdarzeń
Wykonaniem zadań zarówno synchronicznych, jak i asynchronicznych zarządza pętla zdarzeń w Node.js. Wykonanie jest wywoływane w momencie uruchomienia projektu Node.js i płynnie przekazuje złożone zadania do systemu. Dzięki temu inne zadania będą mogły działać płynnie w głównym wątku.
Wizualne wyjaśnienie pętli zdarzeń w Node.js
Pętla zdarzeń w Node.js jest ciągła i półnieskończona. Pętla zdarzeń jest wywoływana wraz z uruchomieniem skryptu kodu Node.js i odpowiada za wykonywanie asynchronicznych wywołań API i wywoływanie procesów.Tick(), a także planowanie timerów, a następnie wznawianie wykonywania pętli zdarzeń.
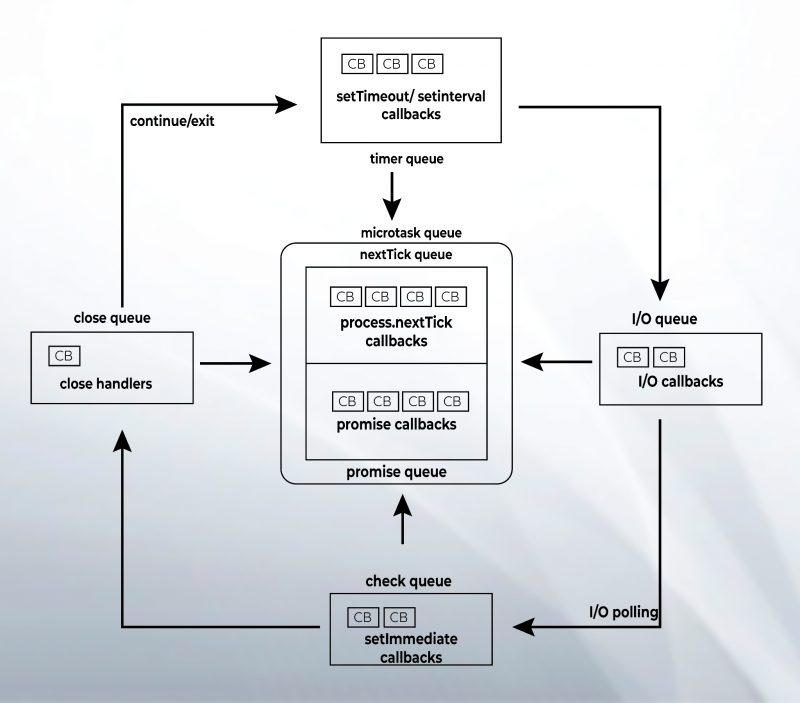
W Node.js pięć głównych typów kolejek obsługuje wywołania zwrotne:
- „Kolejka timera” powszechnie znana jako sterta min jest odpowiedzialna za obsługę wywołań zwrotnych związanych z „setTimeout” i „setInterval”.
- Wywołania zwrotne dla operacji asynchronicznych, takich jak moduły „fs” i „http”, są obsługiwane przez „Kolejkę I/O”.
- „Sprawdź kolejkę” zawiera wywołania zwrotne dla funkcji „setImmediate”, która jest unikalna dla Node.
- „Kolejka zamknięcia” zarządza wywołaniami zwrotnymi związanymi ze zdarzeniem zamykającym dowolne zadanie asynchroniczne.
- Wreszcie w kolejce „Micro Task” znajdują się dwie różne kolejki:
- Kolejka „nextTick” zawiera wywołania zwrotne powiązane z funkcją „process.nextTick”.
- Kolejka „Promise” kontroluje wywołania zwrotne związane z natywną Promise.
Funkcjonalność Event Loop w Node.js
Pętla zdarzeń działa zgodnie z określonymi wymaganiami, które kontrolują kolejność wykonywania wywołania zwrotnego. Synchroniczny kod JavaScript użytkownika ma priorytet na początku procesu, więc pętla zdarzeń rozpoczyna się dopiero po wyczyszczeniu stosu wywołań. Następująca sekwencja wykonania jest zgodna ze strukturalnym wzorcem:
Najwyższy priorytet mają wywołania zwrotne w kolejce mikrozadań, następnie przechodzą do wykonania zadań w kolejce nextTick, a następnie zadania w kolejce Promise. Następnie obsługiwane są procesy w wywołaniach zwrotnych kolejki timera, po czym kolejka mikrozadań jest ponownie odwiedzana po każdym wywołaniu zwrotnym timera. Wywołania zwrotne w kolejkach we/wy, sprawdzanie i zamykanie są następnie wykonywane w podobny sposób, z kolejką mikrozadań odwiedzaną po każdej fazie.
Pętla kontynuuje wykonywanie, jeśli jest więcej wywołań zwrotnych do przetworzenia. Po zakończeniu skryptu kodu lub braku wywołań zwrotnych do przetworzenia pętla zdarzeń kończy się skutecznie.
Teraz, gdy już dobrze rozumiemy pętlę zdarzeń, przyjrzyjmy się jej funkcjom.
Funkcje pętli zdarzeń w Node.js
Główne cechy to:
- Pętla zdarzeń jest pętlą nieskończoną i kontynuuje wykonywanie zadań, gdy tylko je otrzyma, i przechodzi w tryb uśpienia, jeśli nie ma żadnych zadań, ale zaczyna działać natychmiast po otrzymaniu zadania.
- Zadania w kolejce zdarzeń są wykonywane tylko wtedy, gdy stos jest pusty, co oznacza, że nie ma aktywnej operacji.
- W pętli zdarzeń można używać wywołań zwrotnych i obietnic.
- Ponieważ pętla zdarzeń działa na zasadzie kolejki danych abstrakcyjnych, wykonuje pierwsze zadanie, a następnie przechodzi do następnego.
Po dokładnym zrozumieniu pętli zdarzeń oraz logiki wykonań asynchronicznych i synchronicznych zrozumienie różnych faz może utrwalić koncepcje pętli zdarzeń.
Fazy pętli zdarzeń Node.js
Jak wspomniano powyżej, pętla zdarzeń jest półnieskończona. Ma wiele faz, ale niektóre fazy są wykorzystywane do obsługi wewnętrznej. Fazy te nie mają żadnego wpływu na skrypt kodu.
Pętla zdarzeń podąża za funkcjonalnością Queue i realizuje zadanie na zasadzie pierwszego wejścia i pierwszego wyjścia. Zaplanowane liczniki czasu będą obsługiwane przez system operacyjny do momentu ich wygaśnięcia. Wygasłe liczniki czasu są następnie dodawane do kolejki wywołań zwrotnych dla liczników.
Pętla zdarzeń wykonuje zadania z kolejki timera jedno po drugim, aż do wyczerpania zadań lub osiągnięcia maksymalnej dozwolonej liczby zadań. W poniższych sekcjach wyjaśniono podstawowe fazy pętli zdarzeń.
Faza timerów
W Node.js dostępne jest API timera, które pozwala zaplanować funkcje, które mają zostać wykonane w przyszłości. Po upływie przydzielonego czasu wywołanie zwrotne timera zostanie wykonane, gdy tylko będzie można je zaplanować; jednakże może wystąpić opóźnienie po stronie systemu operacyjnego lub spowodowane wykonaniem innych wywołań zwrotnych.
Interfejs API timerów ma trzy główne funkcje:
- ustaw limit czasu
- ustawNatychmiastowe
- ustawinterwał
Wyżej wymienione funkcje są synchroniczne. Faza timera w pętli zdarzeń ma swój zakres ograniczony do funkcji setTimeout i setInterval. Podczas gdy funkcja check obsługuje funkcję setImmediate.
Rozważmy prosty przykład, aby utrwalić część teoretyczną:
// aplikacja.jsfunkcja opóźnionaFunkcja ( ) {
konsola. dziennik ( „opóźniona funkcja jest wykonywana po przekroczeniu limitu czasu” ) ;
}
konsola. dziennik ( „Rozpoczęcie programu” ) ;
ustaw limit czasu ( opóźniona funkcja, 2000 ) ;
konsola. dziennik ( „Koniec programu” ) ;
W tym kodzie:
- Program uruchamia się poprzez zalogowanie na terminalu instrukcji „Start programu”.
- Następnie wywoływana jest funkcja opóźniona z zegarem 2 ms, skrypt kodu nie zatrzymuje się i kontynuuje obsługę opóźnienia w tle.
- Po pierwszej instrukcji logowana jest instrukcja „Koniec programu”.
- Po opóźnieniu wynoszącym 2 ms instrukcja w funkcji opóźnionej jest rejestrowana na terminalu.
Wyjście
Dane wyjściowe pojawią się jako:
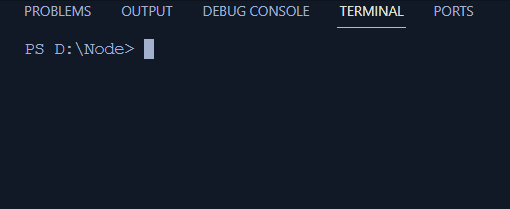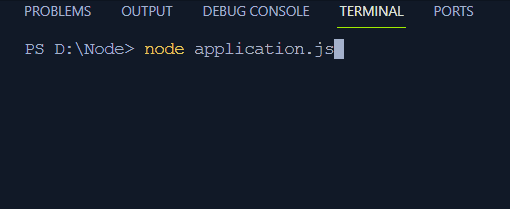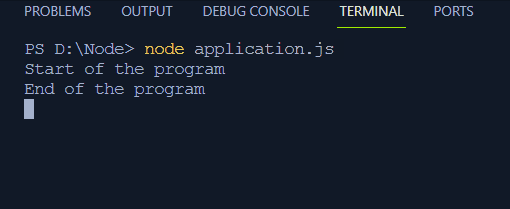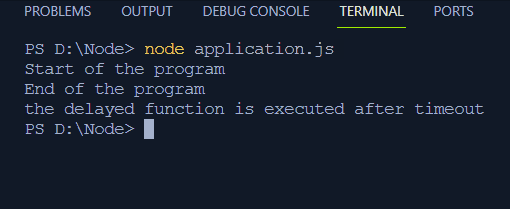
Można zauważyć, że kod nie jest zatrzymywany w celu przetworzenia funkcji opóźnionej; przesuwa się do przodu i po opóźnieniu przetwarzane jest wywołanie zwrotne funkcji.
Oczekujące wywołania zwrotne
Pętla zdarzeń sprawdza, czy w fazie odpytywania zachodzą zdarzenia, takie jak odczytywanie plików, działania sieciowe lub zadania wejścia/wyjścia. Warto wiedzieć, że w Node.js tylko niektóre zdarzenia są obsługiwane w tej fazie odpytywania. Jednakże w kolejnej iteracji pętli zdarzeń pewne zdarzenia mogą zostać odroczone do fazy oczekującej. Jest to kluczowa koncepcja, o której należy pamiętać podczas optymalizacji kodu Node.js i rozwiązywania problemów z nim, który obejmuje złożone operacje sterowane zdarzeniami.
Ważne jest, aby zrozumieć, że w fazie oczekiwania na wywołania zwrotne pętla zdarzeń dodaje przełożone zdarzenia do kolejki oczekujących wywołań zwrotnych i wykonuje je. Ta faza obsługuje również niektóre błędy gniazd TCP wygenerowane przez system, takie jak zdarzenia błędów ECONNREFUSED w niektórych systemach operacyjnych.
Poniżej znajduje się przykład mający na celu ugruntowanie koncepcji:
// aplikacja.jskonst fs = wymagać ( „fs” ) ;
funkcja readFileAsync ( filePath, wywołanie zwrotne ) {
fs. przeczytaj plik ( „./PromiseText.txt” , „utf8” , funkcja ( chyba, dane ) {
Jeśli ( błądzić ) {
konsola. błąd ( ` Błąd odczytanie pliku : $ { błądzić. wiadomość } ` ) ;
} w przeciwnym razie {
konsola. dziennik ( ` Plik treść : $ { dane } ` ) ;
}
oddzwonić ( ) ;
} ) ;
}
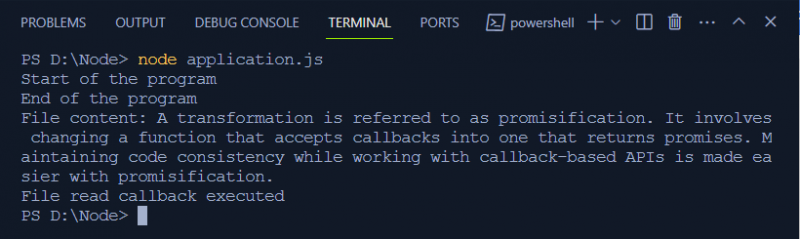
konsola. dziennik ( „Rozpoczęcie programu” ) ;
czytajFileAsync ( „./PromiseText.txt” , funkcja ( ) {
konsola. dziennik ( „Wykonano wywołanie zwrotne odczytu pliku” ) ;
} ) ;
konsola. dziennik ( „Koniec programu” ) ;
W tym kodzie:
- Program inicjuje się poprzez zarejestrowanie w terminalu instrukcji „Start programu”.
- Wartość readFileAsync jest zdefiniowana asynchronicznie w celu odczytania zawartości pliku „PromiseText.txt”. Jest to funkcja sparametryzowana, która po przeczytaniu pliku wykonuje funkcję wywołania zwrotnego.
- Funkcja readFileAsync wywoływana jest w celu rozpoczęcia procesu odczytu pliku.
- W procesie odczytu pliku program nie zatrzymuje się; zamiast tego przechodzi do kolejnej instrukcji i loguje ją do terminala „Koniec programu”.
- Asynchroniczne zdarzenie odczytu pliku jest przetwarzane w tle przez pętlę zdarzeń.
- Po asynchronicznym odczytaniu pliku i zarejestrowaniu zawartości na terminalu program rejestruje zawartość pliku na terminalu. Następnie rejestruje następujący komunikat: „Wykonano wywołanie zwrotne odczytu pliku”.
- Pętla zdarzeń obsługuje oczekujące operacje wywołania zwrotnego w następnej fazie.
Wyjście
Wynikiem powyższego wykonania jest:
Bezczynny, faza przygotowania w Node.js
Faza bezczynności służy do obsługi wewnętrznych funkcji Node.js, więc nie jest to faza standardowa. Nie ma to wpływu na skrypt kodu. Faza bezczynności przypomina okres przerwy w pętli zdarzeń, podczas której w tle zarządza zadaniami o niskim priorytecie. Prostym przykładem zrozumienia tej fazy jest:
konst { bezczynny } = wymagać ( „bezczynność-gc” ) ;bezczynny. ignorować ( ) ;
W tym kodzie zastosowano moduł „idle-gc”, który pozwala zignorować fazę bezczynności. Służy to do obsługi sytuacji, gdy pętla zdarzeń jest zajęta i zadania w tle nie są wykonywane. Użycie idle.ignore nie jest uważane za optymalne, ponieważ może powodować problemy z wydajnością.
Faza odpytywania w Node.js
Faza ankiety w Node.js służy do:
- Obsługuje zdarzenia w kolejce odpytywania i wykonuje odpowiadające im zadania.
- Decyduje, ile czasu spędzić na czekaniu i sprawdzaniu operacji we/wy w procesie.
Gdy pętla zdarzeń wejdzie w fazę odpytywania z powodu braku timera, zostanie wykonane jedno z poniższych zadań:
- W fazie odpytywania pętli zdarzeń w Node.js oczekujące zdarzenia we/wy są umieszczane w kolejce, a następnie wykonywane w procedurze sekwencyjnej zgodnie z zasadą First In i First Out, aż do opróżnienia kolejki. Podczas wykonywania wywołań zwrotnych działają także kolejki nextTick i mikrozadania. Zapewnia to płynność i pozwala na bardziej efektywną i niezawodną obsługę operacji we/wy.
- Jeżeli kolejka jest pusta i skrypt nie został zaplanowany przez funkcję setImmediate() to pętla zdarzeń zakończy się i przejdzie do kolejnej fazy (sprawdzenia). Z drugiej strony, jeśli planowanie skryptu zostało wykonane za pomocą funkcji setImmediate(), pętla zdarzeń pozwala na dodanie wywołań zwrotnych do kolejki, która będzie przez nią wykonywana.
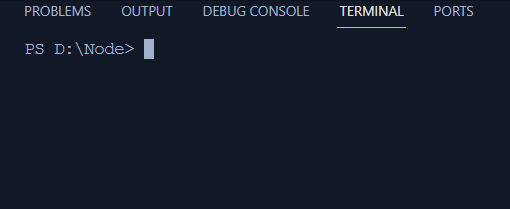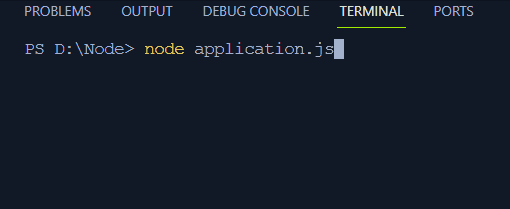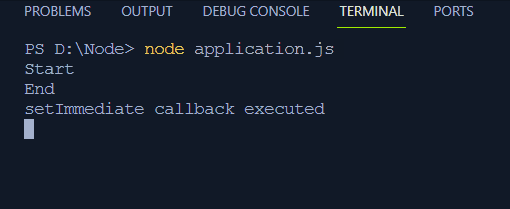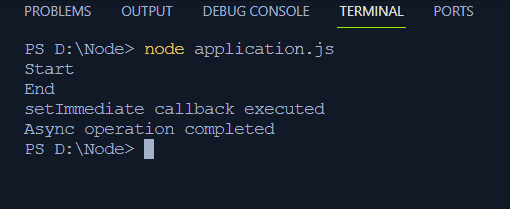
Najlepiej ilustruje to prosty przykład kodu:
ustaw limit czasu ( ( ) => {konsola. dziennik ( „Operacja asynchroniczna zakończona” ) ;
} , 2000 ) ;
konsola. dziennik ( 'Początek' ) ;
ustawNatychmiastowe ( ( ) => {
konsola. dziennik ( „Wykonano natychmiastowe wywołanie zwrotne setImmediate” ) ;
} ) ;
konsola. dziennik ( 'Koniec' ) ;
W tym kodzie:
- Dwa komunikaty „Start” i „Koniec” wskazują rozpoczęcie i zakończenie programu.
- Funkcja setTimeout() ustawia funkcję wywołania zwrotnego z opóźnieniem 2 ms i rejestruje na terminalu „Operację asynchroniczną zakończoną”.
- Funkcja setImmediate() rejestruje komunikat „setImmediate wywołanie zwrotne wykonane” na terminalu po zarejestrowaniu na terminalu komunikatu Start.
Wyjście
Dane wyjściowe pokażą komunikaty z krótką obserwacją, że „Zakończono operację asynchronizacji” wymaga czasu i zostaną wydrukowane po komunikacie „Koniec”:
Faza sprawdzania Node.js
Po wykonaniu fazy odpytywania, wykonywane są wywołania zwrotne w fazie sprawdzania. Jeśli skrypt kodu jest zaplanowany przy użyciu funkcji setImmediate(), a funkcja odpytywania jest wolna, pętla zdarzeń działa w ten sposób, że przechodzi bezpośrednio do fazy sprawdzania, zamiast pozostawać bezczynna. Funkcja setImmediate() to unikalny licznik czasu, który działa w różnych fazach pętli zdarzeń.
API libuv służy do planowania wywołań zwrotnych po zakończeniu fazy odpytywania. Podczas wykonywania kodu pętla zdarzeń wchodzi w fazę odpytywania, w której oczekuje na przychodzące żądania połączenia. W innym przypadku, jeśli zaplanowane jest wywołanie zwrotne przy użyciu funkcji setImmediate(), a faza odpytywania zakończy się bez żadnej aktywności, zamiast czekać, przejdzie do fazy sprawdzania. Rozważ poniższy przykład dla zrozumienia:
// aplikacja.jskonsola. dziennik ( 'Początek' ) ;
ustawNatychmiastowe ( ( ) => {
konsola. dziennik ( „Natychmiastowe oddzwonienie” ) ;
} ) ;
konsola. dziennik ( 'Koniec' ) ;
W tym kodzie do terminala logowane są trzy wiadomości. Następnie funkcja setImmediate() wysyła w końcu wywołanie zwrotne w celu zarejestrowania wiadomości „ Natychmiastowe oddzwonienie ”do terminala.
Wyjście
Dane wyjściowe powyższego kodu zostaną wyświetlone w następującej kolejności:
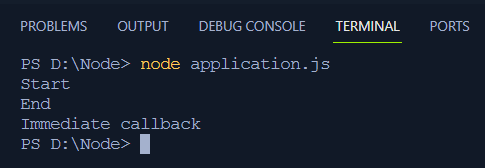
Node.js zamyka wywołania zwrotne
Node.js wykorzystuje tę fazę zamknięcia do uruchamiania wywołań zwrotnych w celu zamknięcia zdarzeń i zakończenia iteracji pętli zdarzeń. Po zamknięciu połączenia pętla zdarzeń obsługuje zdarzenia zamykające w tej fazie. W tej fazie pętli zdarzeń generowane są i przetwarzane „nextTick()” oraz mikrozadania, podobnie jak w innych fazach.
Funkcja Process.exit służy do zakończenia pętli zdarzeń w dowolnym momencie. Pętla zdarzeń zignoruje wszelkie oczekujące operacje asynchroniczne, a proces Node.js zostanie zakończony.
Prosty przykład do rozważenia to:
// aplikacja.jskonst internet = wymagać ( 'internet' ) ;
konst serwer = internet. utwórz serwer ( ( gniazdo elektryczne ) => {
gniazdo elektryczne. NA ( 'zamknąć' , ( ) => {
konsola. dziennik ( „Gniazdo zamknięte” ) ;
} ) ;
gniazdo elektryczne. NA ( 'dane' , ( dane ) => {
konsola. dziennik ( „Otrzymane dane:” , dane. doString ( ) ) ;
} ) ;
} ) ;
serwer. NA ( 'zamknąć' , ( ) => {
konsola. dziennik ( „Serwer zamknięty” ) ;
} ) ;
konst Port = 3000 ;
serwer. Słuchać ( Port, ( ) => {
konsola. dziennik ( `Serwer nasłuchuje na porcie $ { Port } ` ) ;
} ) ;
ustaw limit czasu ( ( ) => {
konsola. dziennik ( „Zamykanie serwera po 10 sekundach” ) ;
serwer. zamknąć ( ) ;
proces. Wyjście ( ) ;
} , 10000 ) ;
W tym kodzie:
- „ const netto = wymagaj („netto”) ” importuje moduł sieciowy wymagany do obsługi serwera TCP i „ serwer stały = net.createServer((gniazdo) => { ” tworzy nową instancję serwera TCP.
- „ gniazdo.on(‘zamknij’, () => {… } ” słucha „zamknięcia” na wszystkich gniazdach. Kiedy połączenie z gniazdem zostanie zamknięte, na terminalu zostanie zarejestrowany komunikat „Socket Closed”.
- „ gniazdo.on(‘dane’, (dane) => {} ” sprawdza przychodzące dane ze wszystkich poszczególnych gniazd i drukuje je za pomocą funkcji „.toString()”.
- „ serwer.on(‘zamknij’, () => {…} ” sprawdza, czy na samym serwerze wystąpiło zdarzenie „close”, a kiedy połączenie z serwerem zostanie zamknięte, rejestruje na terminalu komunikat „Server Closed”.
- „ serwer.listen(port, () => {…} ” nasłuchuje połączeń przychodzących na porcie.
- „ setTimeout(() => {…} ” ustawia licznik czasu na 10 ms, aby zamknąć serwer.
Na tym kończymy dyskusję na temat poszczególnych faz pętli zdarzeń w Node.js. Zanim przejdziemy do konkluzji, omówmy ostatnią kwestię, czyli sposób wyjścia z pętli zdarzeń w Node.js.
Wychodzenie z pętli zdarzeń w Node.js
Pętla zdarzeń znajduje się w fazie wykonania, dopóki we wszystkich kolejkach faz pętli zdarzeń znajdują się jakieś zadania. Pętla zdarzeń kończy się po wyemitowaniu fazy wyjściowej, a wywołanie zwrotne odbiornika wyjściowego powraca, jeśli w kolejkach nie ma już więcej zadań.
Wyraźnym sposobem zakończenia pętli zdarzeń jest użycie metody „.exit”. Aktywne procesy Node.js zostaną zakończone natychmiast po wywołaniu funkcji Process.exit. Wszystkie zaplanowane i oczekujące wydarzenia zostaną usunięte:
proces. NA ( 'Wyjście' , ( kod ) => {konsola. dziennik ( `Wyjście z kodem wyjścia : $ { kod } ` ) ;
} ) ;
proces. Wyjście ( 1 ) ;
Użytkownicy mogą odsłuchać funkcję .exit. Należy zauważyć, że funkcja „.exit” musi być synchroniczna, ponieważ program Node.js zakończy działanie natychmiast po odsłuchaniu tego zdarzenia.
To kończy dyskusję na temat pętli zdarzeń. Dogłębny artykuł, w którym omówiono wszystkie koncepcje, fazy i przykłady związane z pętlą zdarzeń.
Wniosek
Przed zrozumieniem pętli zdarzeń przegląd koncepcji synchronicznych i asynchronicznych może pomóc w zrozumieniu przepływu kodu w pętli zdarzeń. Wykonanie synchroniczne oznacza wykonanie krok po kroku, natomiast wykonanie asynchroniczne oznacza zatrzymanie niektórych kroków bez oczekiwania na ich zakończenie. W artykule omówiono działanie pętli zdarzeń wraz ze wszystkimi fazami wraz z odpowiednimi przykładami.