Wieloprocesorowość jest porównywalna z wielowątkowością. Różni się jednak tym, że możemy wykonać tylko jeden wątek w danym momencie ze względu na GIL, który jest używany do wątkowania. Przetwarzanie wieloprocesorowe to proces sekwencyjnego wykonywania operacji na kilku rdzeniach procesora. Wątki nie mogą działać równolegle. Wieloprocesorowość pozwala nam jednak ustanowić procesy i uruchamiać je jednocześnie na różnych rdzeniach procesora. Pętla, taka jak pętla for, jest jednym z najczęściej używanych języków skryptowych. Powtarzaj tę samą pracę, używając różnych danych, aż zostanie osiągnięte kryterium, takie jak z góry określona liczba iteracji. Pętla wykonuje każdą iterację jeden po drugim.
Przykład 1: Wykorzystanie pętli For w module przetwarzania wieloprocesowego Pythona
W tym przykładzie używamy pętli for i procesu klasy modułu przetwarzania wieloprocesowego Pythona. Zaczniemy od bardzo prostego przykładu, abyś mógł szybko zrozumieć, jak działa wieloprocesorowa pętla for w Pythonie. Korzystając z interfejsu, który jest porównywalny z modułem wątków, wieloprocesorowość pakuje tworzenie procesów.
Wykorzystując podprocesy zamiast wątków, pakiet multiprocessing zapewnia zarówno lokalną, jak i odległą współbieżność, unikając w ten sposób globalnej blokady interpretera. Użyj pętli for, która może być obiektem łańcuchowym lub krotką, aby nieustannie przechodzić przez sekwencję. Działa to mniej jak słowo kluczowe w innych językach programowania, a bardziej jak metoda iteratora występująca w innych językach programowania. Rozpoczynając nowe przetwarzanie wieloprocesorowe, możesz uruchomić pętlę for, która wykonuje procedurę współbieżnie.
Zacznijmy od zaimplementowania kodu do wykonania kodu za pomocą narzędzia „spyder”. Uważamy, że „spyder” jest również najlepszy do uruchamiania Pythona. Importujemy proces modułu wieloprocesorowego, który jest uruchomiony w kodzie. Wieloprocesorowość w koncepcji Pythona określana jako „klasa procesów” tworzy nowy proces Pythona, nadaje mu metodę wykonywania kodu i daje aplikacji nadrzędnej sposób zarządzania wykonaniem. Klasa Process zawiera procedury start() i join(), z których obie są kluczowe.
Następnie definiujemy zdefiniowaną przez użytkownika funkcję o nazwie „func”. Ponieważ jest to funkcja zdefiniowana przez użytkownika, nadajemy jej wybraną przez nas nazwę. Wewnątrz ciała tej funkcji przekazujemy zmienną „subject” jako argument oraz wartość „maths”. Następnie wywołujemy funkcję „print()”, przekazując instrukcję „Nazwa wspólnego podmiotu to” oraz jej argument „subject”, który zawiera wartość. Następnie w kolejnym kroku używamy „if name== _main_”, które uniemożliwia uruchomienie kodu, gdy plik jest importowany jako moduł i pozwala na to tylko wtedy, gdy treść jest wykonywana jako skrypt.
Sekcja warunku, od której zaczynasz, może być w większości przypadków traktowana jako miejsce dostarczania treści, która powinna być wykonywana tylko wtedy, gdy plik działa jako skrypt. Następnie używamy tematu argumentu i przechowujemy w nim pewne wartości, takie jak „nauka”, „angielski” i „komputer”. W następnym kroku proces otrzymuje nazwę „process1[]”. Następnie używamy „process(target=func)”, aby wywołać funkcję w procesie. Target służy do wywołania funkcji, a proces ten zapisujemy w zmiennej „P”.
Następnie używamy „process1” do wywołania funkcji „append()”, która dodaje element na koniec listy, którą mamy w funkcji „func”. Ponieważ proces jest przechowywany w zmiennej „P”, przekazujemy „P” tej funkcji jako jej argument. Na koniec używamy funkcji „start()” z „P”, aby rozpocząć proces. Następnie ponownie uruchamiamy metodę, podając argument „subject” i używając „for” w temacie. Następnie ponownie używając „process1” i metody „add()” rozpoczynamy proces. Następnie proces jest uruchamiany, a dane wyjściowe są zwracane. Następnie nakazuje się zakończyć procedurę za pomocą techniki „join()”. Procesy, które nie wywołują procedury „join()”, nie zostaną zakończone. Jednym z kluczowych punktów jest to, że parametr słowa kluczowego „args” musi być użyty, jeśli chcesz podać jakiekolwiek argumenty w procesie.
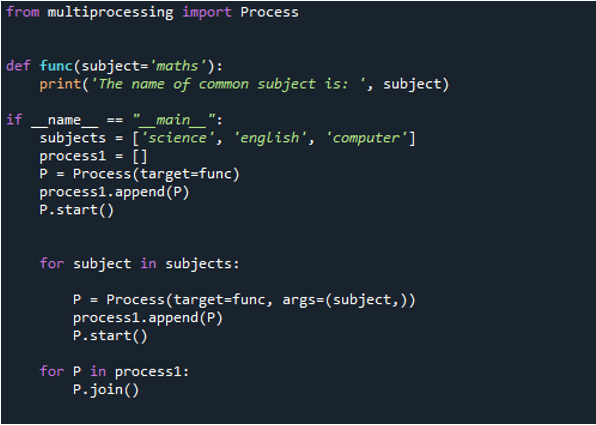
Teraz możesz zobaczyć na wyjściu, że instrukcja jest wyświetlana jako pierwsza, przekazując wartość dla przedmiotu „matematyka”, którą przekazujemy do funkcji „func”, ponieważ najpierw wywołujemy ją za pomocą funkcji „proces”. Następnie używamy polecenia „append()”, aby mieć wartości, które były już na liście, która jest dodawana na końcu. Następnie zaprezentowano „naukę”, „komputer” i „angielski”. Ale, jak widać, wartości nie są w prawidłowej kolejności. Dzieje się tak, ponieważ robią to zaraz po zakończeniu procedury i zgłaszają swoją wiadomość.
Przykład 2: Konwersja sekwencyjnej pętli for na wieloprocesorową równoległą pętlę for
W tym przykładzie zadanie pętli wieloprocesorowej jest wykonywane sekwencyjnie przed konwersją na równoległe zadanie pętli for. Za pomocą pętli for możesz przechodzić między sekwencjami, takimi jak kolekcja lub ciąg znaków, w kolejności ich występowania.
Teraz zacznijmy wdrażać kod. Najpierw importujemy „sen” z modułu czasu. Korzystając z procedury „sleep()” w module time, możesz zawiesić wykonywanie wywołującego wątku na tak długo, jak chcesz. Następnie używamy „random” z modułu random, definiujemy funkcję o nazwie „func” i przekazujemy słowo kluczowe „argu”. Następnie tworzymy losową wartość za pomocą „val” i ustawiamy ją na „random”. Następnie blokujemy na krótki okres za pomocą metody „sleep()” i przekazujemy „val” jako parametr. Następnie, aby przesłać komunikat, uruchamiamy metodę „print()”, przekazując jako jej parametr słowa „ready” i słowo kluczowe „arg”, a także „created” i wartość przekazujemy za pomocą „val”.
Na koniec używamy „flush” i ustawiamy go na „True”. Użytkownik może zdecydować, czy buforować dane wyjściowe, używając opcji flush w funkcji print Pythona. Domyślna wartość tego parametru False wskazuje, że dane wyjściowe nie będą buforowane. Dane wyjściowe są wyświetlane jako seria następujących po sobie wierszy, jeśli ustawisz to na true. Następnie używamy „if name== main”, aby zabezpieczyć punkty wejścia. Następnie wykonujemy zadanie sekwencyjnie. Tutaj ustawiamy zakres na „10”, co oznacza, że pętla kończy się po 10 iteracjach. Następnie wywołujemy funkcję „print()”, przekazujemy jej instrukcję wejściową „ready” i używamy opcji „flush=True”.
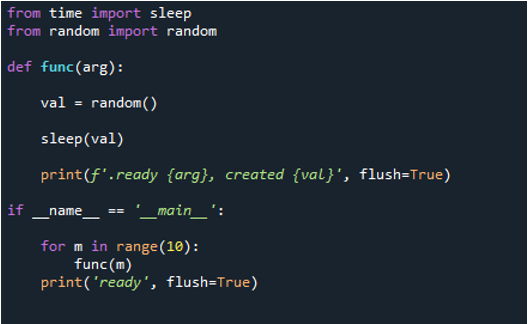
Możesz teraz zobaczyć, że kiedy wykonujemy kod, pętla powoduje wykonanie funkcji „10” razy. Iteruje 10 razy, zaczynając od indeksu zero i kończąc na indeksie dziewiątym. Każda wiadomość zawiera numer zadania, czyli numer funkcji, którą przekazujemy jako „arg” oraz numer kreacji.
Ta sekwencyjna pętla jest teraz przekształcana w wieloprocesorową równoległą pętlę for. Używamy tego samego kodu, ale przechodzimy do kilku dodatkowych bibliotek i funkcji do przetwarzania wieloprocesowego. Dlatego musimy zaimportować proces z przetwarzania wieloprocesowego, tak jak wyjaśniliśmy wcześniej. Następnie tworzymy funkcję o nazwie „func” i przekazujemy słowo kluczowe „arg” przed użyciem „val=random” w celu uzyskania losowej liczby.
Następnie, po wywołaniu metody „print()” w celu wyświetlenia komunikatu i podaniu parametru „val” w celu opóźnienia niewielkiego okresu, wykorzystujemy funkcję „if name= main” do zabezpieczenia punktów wejścia. Następnie tworzymy proces i wywołujemy funkcję w procesie za pomocą „proces” i przekazujemy „target=func”. Następnie przekazujemy „func”, „arg”, wartość „m” oraz zakres „10”, co oznacza, że pętla kończy działanie po „10” iteracjach. Następnie uruchamiamy proces za pomocą metody „start()” z „process”. Następnie wywołujemy metodę „join()”, aby poczekać na wykonanie procesu i zakończyć cały proces po.
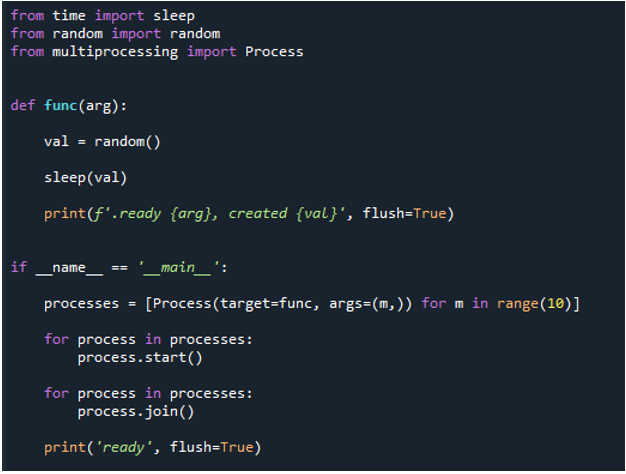
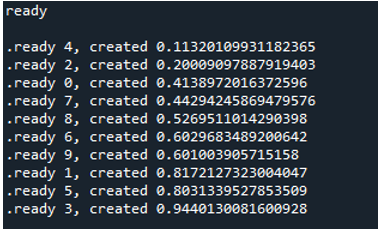
Dlatego, gdy wykonujemy kod, funkcje wywołują główny proces i rozpoczynają wykonywanie. Są one jednak wykonywane, dopóki wszystkie zadania nie zostaną wykonane. Widzimy to, ponieważ każde zadanie jest realizowane równolegle. Zgłasza swoją wiadomość, gdy tylko zostanie zakończona. Oznacza to, że chociaż komunikaty nie są uporządkowane, pętla kończy się po wykonaniu wszystkich „10” iteracji.
Wniosek
W tym artykule omówiliśmy wieloprocesorową pętlę for Pythona. Zaprezentowaliśmy też dwie ilustracje. Pierwsza ilustracja pokazuje, jak wykorzystać pętlę for w bibliotece wieloprocesorowej pętli Pythona. Druga ilustracja pokazuje, jak zamienić sekwencyjną pętlę for na równoległą wieloprocesową pętlę for. Przed skonstruowaniem skryptu dla wieloprocesorowości w Pythonie musimy zaimportować moduł wieloprocesorowy.