Rozdział 4: Samouczek języka asemblera mikroprocesora 6502
4.1 Wprowadzenie
Mikroprocesor 6502 został wypuszczony na rynek w 1975 roku. Był wówczas używany jako mikroprocesor w niektórych komputerach osobistych, takich jak Apple II, Commodore 64 i BBC Micro.
Mikroprocesor 6502 jest nadal produkowany w dużych ilościach. Nie jest to już jednostka centralna stosowana obecnie w komputerach osobistych (laptopach), ale nadal jest produkowana w dużych ilościach i stosowana obecnie w urządzeniach elektronicznych i elektrycznych. Aby zrozumieć bardziej nowoczesne architektury komputerów, bardzo pomocne jest zbadanie starszego, ale całkiem udanego mikroprocesora, takiego jak 6502.
Ponieważ jest prosty do zrozumienia i zaprogramowania, jest to jeden z najlepszych (jeśli nie najlepszy) mikroprocesor do nauczania języka asemblerowego. Język asemblera jest językiem niskiego poziomu, którego można używać do programowania komputera. Należy zauważyć, że język asemblera dla jednego mikroprocesora różni się od języka asemblera innego mikroprocesora. W tym rozdziale nauczany jest język asemblera mikroprocesora 6502. Dokładniej, uczy się 65C02, ale nazywa się go po prostu 6502.
Słynny komputer w przeszłości nazywał się commodore_64. 6502 to mikroprocesor z rodziny 6500. Komputer Commodore_64 wykorzystuje mikroprocesor 6510. Mikroprocesor 6510 ma pojemność 6500 µP. Zestaw instrukcji 6502 µP to prawie wszystkie instrukcje 6510 µP. Znajomość tego i następnego rozdziału opiera się na komputerze commodore_64. Wiedza ta służy jako podstawa do wyjaśnienia nowoczesnych architektur komputerów i nowoczesnych systemów operacyjnych w tej części internetowego kursu kariery.
Architektura komputera odnosi się do komponentów płyty głównej komputera i wyjaśnienia, w jaki sposób dane przepływają w każdym elemencie, zwłaszcza w mikroprocesorze, w jaki sposób dane przepływają między komponentami, a także w jaki sposób dane wchodzą w interakcję. Liczba pojedyncza dla danych to datum. Skutecznym sposobem poznania architektury komputera jest przestudiowanie języka asemblera płyty głównej.
Mówi się, że komputer commodore_64 jest komputerem 8-bitowego słowa komputerowego. Oznacza to, że informacje są przechowywane, przesyłane i manipulowane w postaci ośmiobitowych kodów binarnych.
Schemat blokowy płyty głównej Commodore 64
Schemat blokowy płyty głównej Commodore 64 wygląda następująco:
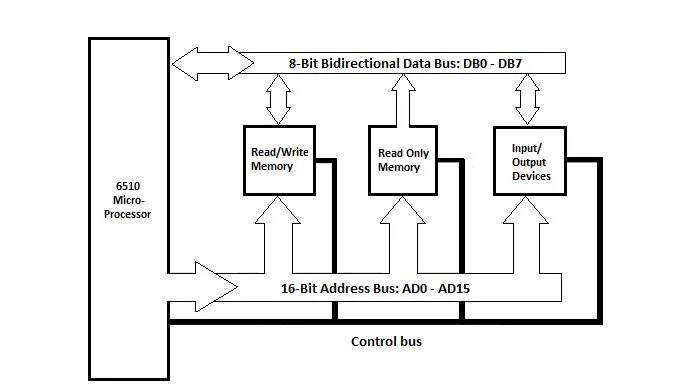
Rys. 4.1 Schemat blokowy jednostki systemowej Commodore_64
Wyobraź sobie mikroprocesor 6510 jako mikroprocesor 6502. Całkowita pamięć to seria bajtów (8 bitów na bajt). Istnieje pamięć o dostępie swobodnym (odczyt/zapis), w której można zapisywać lub usuwać bajty. Po wyłączeniu zasilania komputera wszystkie informacje znajdujące się w pamięci RAM zostają usunięte. Dostępna jest także pamięć tylko do odczytu (ROM). Po wyłączeniu zasilania komputera informacje w pamięci ROM pozostają (nie są usuwane).
Istnieje port wejścia/wyjścia (obwód), który na schemacie określany jest jako urządzenia wejścia/wyjścia. Portu tego nie należy mylić z portami widocznymi po lewej i prawej stronie lub z przodu i z tyłu pionowej powierzchni jednostki systemowej komputera. To dwie różne rzeczy. Połączenia tego wewnętrznego portu z urządzeniami peryferyjnymi, takimi jak dysk twardy (lub dyskietka), klawiatura i monitor, nie są pokazane na schemacie.
Na schemacie znajdują się trzy szyny (grupy bardzo małych przewodów elektrycznych). Każdy przewód może przesyłać bit 1 lub bit 0. Szyna danych do przesyłania jednorazowo ośmiu bitów bajtów (jeden impuls zegarowy) do pamięci RAM i portu wejścia/wyjścia (urządzenia wejścia/wyjścia) jest dwukierunkowa. Szyna danych ma szerokość ośmiu bitów.
Wszystkie komponenty są podłączone do szyny adresowej. Magistrala adresowa jest jednokierunkowa z mikroprocesora. Szyna adresowa ma szesnaście przewodów, a każdy z nich przenosi jeden bit (1 lub 0). W jednym impulsie zegarowym przesyłanych jest szesnaście bitów.
Jest magistrala sterująca. Niektóre przewody szyny sterującej przesyłałyby po jednym bicie z mikroprocesora do innych komponentów. Kilka linii sterujących przenosi bity z portu wejścia/wyjścia (IO) do mikroprocesora.
Pamięć komputera
Pamięć RAM i ROM są traktowane jako jeden zespół pamięci. Zespół ten jest przedstawiony schematycznie w następujący sposób, gdzie liczby szesnastkowe mają przedrostek „$”:
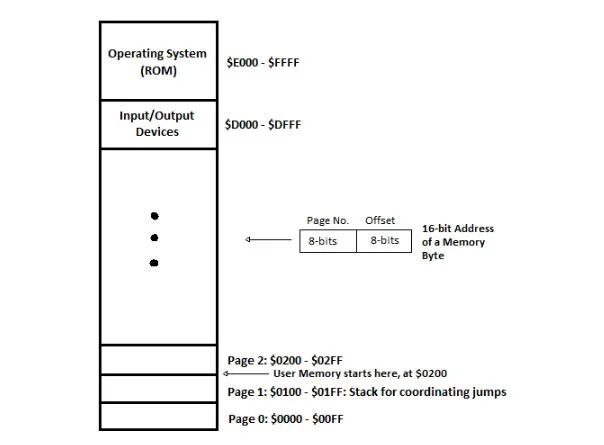
Rys. 4.11 Układ pamięci komputera Commodore 64
Pamięć RAM jest od 0000 16 do DFFF 16 który jest zapisywany od 0000 $ do $DFFF. W języku asemblera 6502 µP liczba szesnastkowa jest poprzedzona „$” i nie jest opatrzona sufiksem (indeksem dolnym) liczbą 16, H lub szesnastkowo. Wszelkie informacje znajdujące się w pamięci RAM znikają po wyłączeniu komputera. ROM zaczyna się od $E000 do $FFFF. Zawiera podprogramy, które nie uruchamiają się po wyłączeniu komputera. Te podprogramy są powszechnie używanymi procedurami, które pomagają w programowaniu. Program użytkownika wywołuje je (patrz następny rozdział).
Przestrzeń (bajty) od $0200 do $D000 przeznaczona jest na programy użytkownika. Przestrzeń od $D000 do $DFFF przeznaczona jest na informacje bezpośrednio związane z urządzeniami peryferyjnymi (urządzeniami wejścia/wyjścia). Jest to część systemu operacyjnego. Tak więc system operacyjny komputera Commodore-64 składa się z dwóch głównych części: części w pamięci ROM, która nigdy nie wyłącza się, i części od D000 $ do $DFFF, która wyłącza się po wyłączeniu zasilania. Te dane IO (wejścia/wyjścia) muszą być ładowane z dysku przy każdym włączeniu komputera. Dziś takie dane nazywane są sterownikami peryferyjnymi. Urządzenia peryferyjne rozpoczynają się od portu urządzenia wejścia/wyjścia, poprzez połączenia na płycie głównej, aż do możliwych do zidentyfikowania portów na pionowych powierzchniach komputera, do których podłączony jest monitor, klawiatura itp., oraz do samych urządzeń peryferyjnych (monitora, klawiatury itp.) .).
Pamięć składa się z 2 16 = 65 536 lokalizacji bajtów. W formie szesnastkowej jest to 10000 16 = 10000 H = 10000 klątwa = Lokalizacje o wartości 10 000 USD. W informatyce liczenie o podstawie drugiej, dziesiątej, szesnastej itd. zaczyna się od 0, a nie od 1. Zatem pierwsza lokalizacja jest w rzeczywistości numerem lokalizacji 0000000000000000 2 = 0 10 = 0000 16 = 0000 dolarów. W języku asemblera 6502 µP identyfikacja lokalizacji adresu jest poprzedzona znakiem $ i nie ma tu przyrostka ani indeksu dolnego. Ostatnia lokalizacja to numer lokalizacji 1111111111111111 2 = 65535 10 = FFFF 16 = $FFFF, a nie 1000000000000000 2 lub 65536 10 lub 10000 16 lub 10 000 dolarów. 1000000000000000 2 , 65536 10 , 10000 16 lub $10000 podaje całkowitą liczbę lokalizacji bajtów.
Tutaj, 2 16 = 65536 = 64 x 1024 = 64 x 2 10 = 64 kilobajtów (kilobajtów). Sufiks 64 w nazwie Commodore-64 oznacza 64KB całkowitej pamięci (RAM i ROM). Bajt ma 8 bitów i 8 bitów zajmie jednobajtowe miejsce w pamięci.
64 KB pamięci jest podzielone na strony. Na każdej stronie znajduje się numer 0100 16 = 256 10 lokalizacje bajtów. Pierwsze 256 10 = pierwszy 0100 16 lokalizacje to strona 0. Druga to strona 1, trzecia to strona 2 i tak dalej.
Aby zaadresować 65 536 lokalizacji, potrzeba 16 bitów na każdą lokalizację (adres). Zatem szyna adresowa z mikroprocesora do pamięci składa się z 16 linii; jedna linia na jeden bit. Bit ma wartość 1 lub 0.
Rejestry 6502 µP
Rejestr jest jak komórki bajtowe określające lokalizację w pamięci bajtów. Model 6502 µP ma sześć rejestrów: pięć rejestrów 8-bitowych i jeden rejestr 16-bitowy. Rejestr 16-bitowy nazywany jest Licznikiem Programów, w skrócie PC. Przechowuje adres pamięci dla następnej instrukcji. Program w języku asemblera składa się z instrukcji umieszczanych w pamięci. Aby zaadresować określoną lokalizację bajtu w pamięci, potrzebnych jest szesnaście (16) różnych bitów. Przy określonym impulsie zegarowym bity te są wysyłane do 16-bitowych linii adresowych szyny adresowej w celu odczytania instrukcji. Wszystkie rejestry dla 6502 µP są przedstawione w następujący sposób:
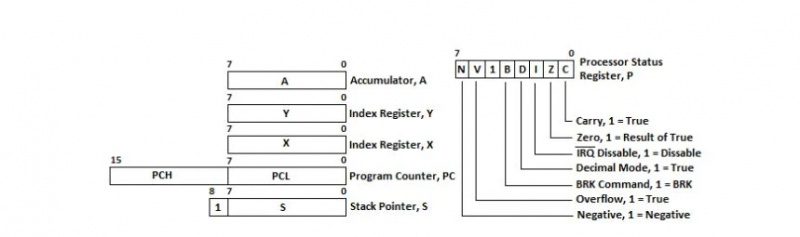
Rys. 4.12 Rejestry 6502 µP
Licznik programów lub komputer PC można zobaczyć na schemacie jako rejestr 16-bitowy. Dolne znaczące osiem bitów jest oznaczonych jako PCL, co oznacza niski poziom licznika programów. Wyższe znaczące osiem bitów jest oznaczonych jako PCH dla wysokiego licznika programu. Instrukcja w pamięci Commodore-64 może składać się z jednego, dwóch lub trzech bajtów. 16 bitów w komputerze wskazuje następną instrukcję do wykonania w pamięci. Wśród obwodów mikroprocesora dwa z nich nazywane są jednostką arytmetyczną i dekoderem instrukcji. Jeśli bieżąca instrukcja przetwarzana w µP (mikroprocesorze) ma długość jednego bajtu, te dwa obwody zwiększają komputer PC dla następnej instrukcji o 1 jednostkę. Jeśli bieżąca instrukcja przetwarzana w µP ma długość dwóch bajtów, co oznacza, że zajmuje dwa kolejne bajty w pamięci, te dwa obwody zwiększają PC dla następnej instrukcji o 2 jednostki. Jeśli bieżąca instrukcja przetwarzana w µP ma długość trzech bajtów, co oznacza, że zajmuje trzy kolejne bajty w pamięci, te dwa obwody zwiększają PC dla następnej instrukcji o 3 jednostki.
Akumulator „A” jest ośmiobitowym rejestrem ogólnego przeznaczenia, w którym przechowuje się wyniki większości operacji arytmetycznych i logicznych.
Rejestry „X” i „Y” służą do zliczania kroków programu. Liczenie w programowaniu rozpoczyna się od 0. Nazywa się je więc rejestrami indeksowymi. Mają jeszcze kilka innych celów.
Chociaż rejestr wskaźnika stosu, „S” ma 9 bitów, co jest uważane za rejestr ośmiobitowy. Jego zawartość wskazuje na lokalizację bajtu na stronie 1 pamięci o dostępie swobodnym (RAM). Strona 1 zaczyna się od bajtu $0100 (256 10 ) do bajtu $01FF (511 10 ). Kiedy program jest uruchomiony, przechodzi od jednej instrukcji do następnej kolejnej instrukcji w pamięci. Jednak nie zawsze tak jest. Są chwile, kiedy przeskakuje z jednego obszaru pamięci do innego obszaru pamięci, aby kontynuować wykonywanie tam instrukcji, po kolei. Strona 1 w pamięci RAM jest używana jako stos. Stos to duży obszar pamięci RAM, który zawiera kolejne adresy kontynuacji kodu, z którego następuje skok. Kody z instrukcjami skoków nie znajdują się na stosie; są gdzie indziej, w pamięci. Jednakże po wykonaniu instrukcji skoku adresy kontynuacji (nie segmenty kodu) znajdują się na stosie. Zostały tam zepchnięte na skutek instrukcji skoku lub rozgałęzienia.
Ośmiobitowy rejestr stanu procesora P jest specjalnym rodzajem rejestru. Poszczególne bity nie są ze sobą powiązane ani połączone. Każdy bit nazywany jest flagą i jest ceniony niezależnie od pozostałych. Znaczenie flag podano poniżej, w zależności od potrzeb.
Pierwszy i ostatni indeks bitu dla każdego rejestru są wskazane nad każdym rejestrem na poprzednim schemacie. Liczenie indeksu (pozycji) bitu w rejestrze rozpoczyna się od 0 po prawej stronie.
Strony pamięci w formacie binarnym, szesnastkowym i dziesiętnym
Poniższa tabela przedstawia początek stron pamięci w formacie binarnym, szesnastkowym i dziesiętnym:

Na każdej stronie jest 1 0000 0000 2 liczba bajtów równa 100 H liczba bajtów równa 256 10 liczba bajtów. Na poprzednim schemacie pamięci strony są pokazane w górę od strony 0, a nie w dół, jak pokazano w tabeli.
Kolumny binarne, szesnastkowe i dziesiętne tej tabeli podają adresy lokalizacji bajtów pamięci w różnych podstawach. Zauważ, że w przypadku strony zerowej podczas kodowania konieczne jest wpisanie tylko bitów dolnego bajtu. Bity wyższego bajtu można pominąć, ponieważ zawsze są zerami (dla strony zerowej). Dla pozostałych stron należy używać bitów wyższego bajtu.
Pozostała część tego rozdziału wyjaśnia język asemblera 6502 µP, korzystając ze wszystkich poprzednich informacji. Aby szybko zrozumieć język, czytelnik musi dodawać i odejmować w podstawie szesnastej zamiast podstawy dziesiątej. Właściwie powinna to być podstawa dwa, ale obliczanie w oparciu o podstawę dwa jest kłopotliwe. Pamiętaj, że podczas dodawania dwóch liczb o podstawie drugiej, przeniesienie nadal wynosi 1, tak jak w przypadku podstawy dziesiątej. Ale przy odejmowaniu dwóch liczb o podstawie dwa, pożyczka wynosi dwa, a nie dziesięć, jak w przypadku podstawy dziesiątej. Dodając dwie liczby o podstawie szesnastej, przeniesienie nadal wynosi 1, tak jak w przypadku podstawy dziesiątej. Ale przy odejmowaniu dwóch liczb o podstawie szesnastej pożyczka wynosi szesnaście, a nie dziesięć, jak w przypadku podstawy dziesiątej.
4.2 Instrukcje przesyłania danych
Rozważ poniższą tabelę instrukcji przesyłania danych w języku asemblera dla 6502 µP:
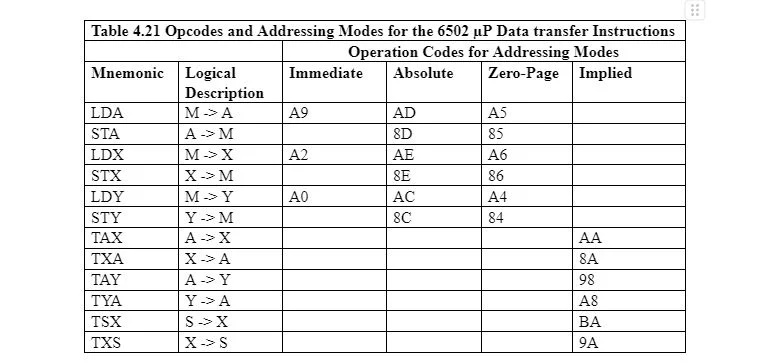
Kiedy bajt (8-bitowy) jest kopiowany z lokalizacji bajtów pamięci do rejestru akumulatora, rejestru X lub rejestru Y, następuje ładowanie. Kiedy bajt jest kopiowany z któregokolwiek z tych rejestrów do lokalizacji bajtowej w pamięci, jest to przesyłanie. Kiedy bajt jest kopiowany z jednego rejestru do drugiego, nadal jest on przesyłany. W drugiej kolumnie tabeli strzałka pokazuje kierunek kopiowania bajtu. Pozostałe cztery kolumny pokazują różne tryby adresowania.
Wpis w kolumnie trybu adresowania jest rzeczywistym kodem bajtowym odpowiedniej części mnemonicznej instrukcji w formacie szesnastkowym. Na przykład AE jest rzeczywistym kodem bajtowym dla LDX, który ma załadować bajt z pamięci do rejestru X w trybie adresowania bezwzględnego, takim jak AE 16 = 10101110 2 . Zatem bity dla LDX w lokalizacji bajtów pamięci to 10101110.
Należy zauważyć, że w przypadku mnemonicznej części instrukcji LDX istnieją trzy możliwe bajty: A2, AE i A6, a każdy z nich jest przeznaczony dla określonego trybu adresowania. Jeżeli bajt ładowany do rejestru X nie ma być kopiowany z lokalizacji bajtów pamięci, wartość należy wpisać w instrukcji (zaraz po) mnemoniku LDX w formacie szesnastkowym lub dziesiętnym. W tym rozdziale takie wartości są wpisywane w systemie szesnastkowym. Jest to adresowanie natychmiastowe, więc faktyczny bajt w pamięci reprezentujący LDX to A2 16 = 10100010 2 a nie AE 16 co jest równe 10101110 2 .
W tabeli wszystkie bajty pod nagłówkami trybu adresowania nazywane są kodami operacji, w skrócie opcodes. Dla jednego mnemonika może istnieć więcej niż jeden kod operacji, w zależności od trybu adresowania.
Notatka: Słowo „load” w jednostce systemowej komputera może mieć dwa znaczenia: może odnosić się do ładowania pliku z dysku do pamięci komputera lub może odnosić się do przesyłania bajtu z lokalizacji bajtów pamięci do rejestru mikroprocesora .
Istnieje więcej trybów adresowania niż cztery w tabeli dla 6502 µP.
O ile nie zaznaczono inaczej, cały kod programowania użytkownika w tym rozdziale zaczyna się od adresu 0200 16 który jest początkiem obszaru użytkownika w pamięci.
Pamięć M i akumulator A
Pamięć do akumulatora
Natychmiastowe adresowanie
Poniższa instrukcja przechowuje liczbę FF 16 = 255 10 do akumulatora:
LDA#$FF
Znak „$” służy nie tylko do identyfikacji adresu pamięci. Ogólnie rzecz biorąc, służy do wskazania, że następna liczba po niej jest liczbą szesnastkową. W tym przypadku $FF nie jest adresem żadnej lokalizacji bajtów pamięci. Jest to liczba 255 10 w formacie szesnastkowym. Baza 16 lub jakikolwiek inny równoważny indeks dolny nie może być zapisany w instrukcji języka asemblera. „#” wskazuje, że cokolwiek następuje dalej, jest to wartość, którą należy umieścić w rejestrze akumulatora. Wartość można również zapisać w systemie dziesiętnym, ale w tym rozdziale nie zostanie to zrobione. „#” oznacza natychmiastowe adresowanie.
Mnemonik ma pewne podobieństwo do odpowiadającego mu wyrażenia w języku angielskim. „LDA #$FF” oznacza załadowanie numeru 255 10 do akumulatora A. Ponieważ jest to adresowanie bezpośrednie z poprzedniej tabeli, LDA to A9, a nie AD lub A5. A9 w formacie binarnym to 101010001. Zatem, jeśli A9 dla LDA znajduje się w pamięci pod adresem 0200 $, $FF ma adres 0301 $ = 0300 + 1. #$FF jest dokładnie operandem mnemonika LDA.
Adresowanie absolutne
Jeśli wartość $FF znajduje się w lokalizacji $0333 w pamięci, poprzednia instrukcja wygląda następująco:
LDA 0333 dolarów
Zwróć uwagę na brak #. W tym przypadku brak # oznacza, że następujący po nim adres pamięci, a nie interesująca go wartość (nie wartość, którą należy umieścić w akumulatorze). Zatem kod operacji dla LDA to tym razem AD, a nie A9 lub A5. Operandem LDA jest tutaj adres $0333, a nie wartość $FF. $FF znajduje się w lokalizacji $0333, która jest dość daleko. Instrukcja „LDA $0333” zajmuje trzy kolejne miejsca w pamięci, a nie dwie, jak miało to miejsce na poprzedniej ilustracji. „AD” dla LDA znajduje się w lokalizacji 0200 USD. Dolny bajt numeru 0333, czyli 33, znajduje się w lokalizacji $0301. Wyższy bajt wartości 0333 $, czyli 03, znajduje się w lokalizacji $ 0302. To jest mała endianowość używana w języku asemblera 6502. Języki asemblera różnych mikroprocesorów są różne.
To jest przykład adresowania absolutnego. $0333 to adres lokalizacji, która ma $FF. Instrukcja składa się z trzech kolejnych bajtów i nie zawiera $FF ani jego rzeczywistej lokalizacji w bajcie.
Adresowanie zerowej strony
Załóżmy, że wartość $FF znajduje się w lokalizacji pamięci $0050 na stronie zerowej. Położenia bajtów strony zerowej zaczynają się od 0000 $ i kończą na 00FF. Jest ich 256 10 łącznie lokalizacje. Każda strona pamięci Commodore-64 to 256 10 długi. Zauważ, że wyższy bajt ma wartość zero dla wszystkich możliwych lokalizacji w obszarze zerowej strony pamięci. Tryb adresowania strony zerowej jest taki sam, jak tryb adresowania bezwzględnego, z tą różnicą, że do instrukcji nie jest wpisywany wyższy bajt liczby 00. Zatem, aby załadować $FF z lokalizacji $0050 do akumulatora, instrukcja trybu adresowania strony zerowej wygląda następująco:
LDA 50 dolarów
Ponieważ LDA to A5, a nie A9 lub AD, A5 16 = 10100101 2 . Pamiętaj, że każdy bajt w pamięci składa się z 8 komórek, a każda komórka mieści kawałek. Instrukcja składa się tutaj z dwóch kolejnych bajtów. A5 dla LDA znajduje się w lokalizacji pamięci 0200 $, a adres 50 $, bez starszego bajtu 00, znajduje się w lokalizacji 0301 $. Brak liczby 00, który zająłby bajt w całkowitej pamięci 64 KB, oszczędza przestrzeń pamięci.
Akumulator do pamięci
Adresowanie absolutne
Następująca instrukcja kopiuje wartość bajtu, jakakolwiek by ona nie była, z akumulatora do komórki pamięci o wartości 1444 USD:
SĄ 1444 USD
Mówi się, że jest to transfer z akumulatora do pamięci. Nie ładuje się. Ładowanie jest odwrotne. Bajt kodu operacji dla STA to 8D 16 = 10001101 2 . Instrukcja ta składa się z trzech kolejnych bajtów w pamięci. 8D 16 znajduje się w lokalizacji $0200. 44 16 z adresu $1444 znajduje się w lokalizacji $0201. I 14 16 znajduje się w lokalizacji $0202 – Little Endianness. Rzeczywisty kopiowany bajt nie jest częścią instrukcji. Dla STA stosuje się tutaj 8D, a nie 85 dla adresowania strony zerowej (w tabeli).
Adresowanie strony zerowej
Poniższa instrukcja kopiuje wartość bajtu, jakakolwiek by ona nie była, z akumulatora do komórki pamięci o wartości 0050 $ na stronie zerowej:
STA $0050
Bajt kodu operacji dla STA wynosi tutaj 85 16 = 10000101 2 . Instrukcja ta składa się z dwóch kolejnych bajtów w pamięci. 85 16 znajduje się w lokalizacji $0200. 50 16 z adresu $0050 znajduje się w lokalizacji $0201. Kwestia endianowości nie pojawia się tutaj, ponieważ adres ma tylko jeden bajt, który jest bajtem młodszym. Rzeczywisty kopiowany bajt nie jest częścią instrukcji. W przypadku STA używane jest tutaj 85, a nie 8D dla adresowania strony zerowej.
Nie ma sensu stosować adresowania bezpośredniego do przesłania bajtu z akumulatora do miejsca w pamięci. Dzieje się tak dlatego, że rzeczywista wartość, np. $FF, musi być podana w instrukcji przy adresowaniu bezpośrednim. Zatem natychmiastowe adresowanie nie jest możliwe w przypadku przesłania wartości bajtu z rejestru w µP do dowolnego miejsca w pamięci.
Mnemoniki LDX, STX, LDY i STY
LDX i STX są podobne odpowiednio do LDA i STA. Ale tutaj używany jest rejestr X, a nie rejestr A (akumulator). LDY i STY są podobne odpowiednio do LDA i STA. Ale tutaj używany jest rejestr Y, a nie rejestr A. W Tabeli 4.21 znajdziesz każdy kod operacji w formacie szesnastkowym, który odpowiada konkretnemu mnemonikowi i konkretnemu trybowi adresowania.
Transfery między rejestrami
Poprzednie dwa zestawy instrukcji w tabeli 4.21 dotyczą kopiowania pamięci/rejestru mikroprocesora (transferu) i kopiowania rejestru/rejestru (transferu). Instrukcje TAX, TXA, TAY, TYA, TSX i TXS wykonują kopiowanie (przenoszenie) z rejestru w mikroprocesorze do innego rejestru tego samego mikroprocesora.
Aby skopiować bajt z A do X, instrukcja jest następująca:
PODATEK
Aby skopiować bajt z X do A, instrukcja jest następująca:
Teksas
Aby skopiować bajt z A do Y, instrukcja jest następująca:
RĘKA
Aby skopiować bajt z Y do A, instrukcja jest następująca:
TY
W przypadku komputera Commodore 64 stos jest stroną 1 zaraz po stronie 0 w pamięci. Jak każda inna strona, składa się z 25610 10 lokalizacje bajtów, od $ 0100 do $ 01FF. Zwykle program jest wykonywany od jednej instrukcji do następnej kolejnej instrukcji w pamięci. Od czasu do czasu następuje przeskok do innego segmentu kodu pamięci (zestawu instrukcji). Obszar stosu w pamięci (RAM) zawiera adresy kolejnych instrukcji, od których skoki (lub rozgałęzienia) zostały przerwane w celu kontynuacji programu.
Wskaźnik stosu „S” jest rejestrem 9-bitowym w 6502 µP. Pierwszy bit (najbardziej na lewo) to zawsze 1. Wszystkie adresy lokalizacji bajtów na stronie pierwszej zaczynają się od 1, po której następuje 8 różnych bitów dla 256 10 lokalizacje. Wskaźnik stosu zawiera adres lokalizacji na stronie 1, która zawiera adres następnej instrukcji, którą program musi zwrócić i kontynuować po wykonaniu bieżącego (do którego przeskoczono) segmentu kodu. Ponieważ pierwszy bit wszystkich adresów stosu (pierwsza strona) zaczyna się od 1, rejestr wskaźnika stosu musi przechowywać jedynie pozostałe osiem bitów. W końcu jego pierwszy bit, będący bitem znajdującym się najbardziej na lewo (dziewiąty bit, licząc od prawej), ma zawsze wartość 1.
Aby skopiować bajt z S do X, instrukcja jest następująca:
TSX
Aby skopiować bajt z X do S, instrukcja jest następująca:
tekst
Instrukcje między rejestrami nie przyjmują żadnego argumentu. Składają się wyłącznie z mnemoników. Każdy mnemonik ma swój kod operacji w formacie szesnastkowym. Dzieje się to w trybie adresowania domniemanego, ponieważ nie ma operandu (brak adresu pamięci, brak wartości).
Notatka: Nie ma możliwości przeniesienia X do Y lub Y do X (kopiowania).
4.3 Operacje arytmetyczne
Obwód, jednostka arytmetyczno-logiczna w 6502 µP, może dodać jednocześnie tylko dwie liczby ośmiobitowe. Nie odejmuje, nie mnoży i nie dzieli. Poniższa tabela przedstawia kody operacji i tryby adresowania dla operacji arytmetycznych:
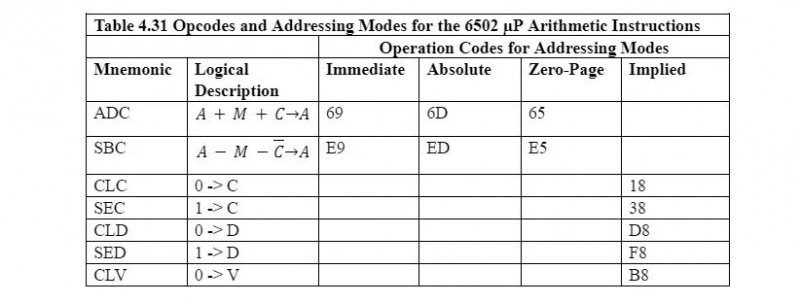
Notatka: Wszystkie mnemoniki operacji arytmetycznych i innych typów operacji (tj. wszystkie mnemoniki 6502) zajmują jeden bajt kodu operacji (op). Jeśli istnieje więcej niż jeden tryb adresowania dla mnemonika, będą różne kody operacji dla tego samego mnemonika: jeden na tryb adresowania. C, D i V w tabeli są flagami rejestru stanu. Ich znaczenie zostanie podane później, w miarę zaistnienia potrzeby.
Dodawanie liczb bez znaku
W przypadku 6502 µP liczby ze znakiem są liczbami uzupełnionymi do dwójki. Liczby bez znaku to zwykłe liczby dodatnie, które zaczynają się od zera. Zatem dla bajtu składającego się z ośmiu bitów najmniejsza liczba bez znaku to 00000000 2 = 0 10 = 00 16 a największa liczba bez znaku to 11111111 2 = 255 10 = FF 16 . W przypadku dwóch liczb bez znaku dodanie wynosi:
A+M+C →A
Oznacza to, że 8-bitowa zawartość akumulatora jest dodawana przez jednostkę arytmetyczno-logiczną do bajtu (8 bitów) pamięci. Po dodaniu A i M, przeniesienie do dziewiątego bitu trafia do komórki flagi przeniesienia w rejestrze stanu. Każdy poprzedni bit przeniesienia z poprzedniego dodania, który nadal znajduje się w komórce flagi przeniesienia w rejestrze stanu, jest również dodawany do sumy A i M, tworząc A+M+C → A. Wynik jest ponownie umieszczany w akumulatorze.
Jeżeli dodanie odsetek wynosi:
A + M
I nie ma potrzeby dodawania żadnego poprzedniego przeniesienia, należy wyczyścić flagę przeniesienia, która wynosi 0, tak aby dodanie było:
A+M+0 →A To samo co A+M →A
Notatka: Jeśli M zostanie dodane do A i nastąpi przeniesienie 1, ponieważ wynik jest większy niż 255 10 = 11111111 2 = FF 16 , to jest nowy carry. To nowe przeniesienie 1 jest automatycznie wysyłane do komórki flagi przeniesienia na wypadek, gdyby było potrzebne do zsumowania kolejnej pary ośmiu bitów (kolejne A + M).
Kod dodający dwa osiem bitów bez znaku
00111111 2 +00010101 2 jest taki sam jak 3F 16 + 15 16 co jest tym samym co 63 10 +21 10 . Wynik to 010101002 2 czyli to samo co 54 16 i 84 10 . Wynik nie przekracza maksymalnej liczby ośmiu bitów, która wynosi 255 10 = 11111111 2 = FF 16 . Zatem nie ma wynikowego przeniesienia 1. Inaczej mówiąc, wynikowe przeniesienie wynosi 0. Przed dodaniem nie ma poprzedniego przeniesienia 1. Innymi słowy, poprzednie przeniesienie wynosi 0. Kod wykonujący to dodawanie może być:
WŻCH
LDA#$3F
ADC #15 dolarów
Notatka: Podczas wpisywania języka asemblera na końcu każdej instrukcji naciskany jest klawisz „Enter” na klawiaturze. W tym kodzie znajdują się trzy instrukcje. Pierwsza instrukcja (CLC) czyści flagę przeniesienia w przypadku, gdy poprzednie dodanie ma wartość 1. CLC można wykonać tylko w trybie adresowania implikowanego. Mnemonik dla implikowanego trybu adresowania nie wymaga żadnego argumentu. Czyści to komórkę przeniesienia rejestru stanu P. Czyszczenie oznacza przekazanie bitu 0 do komórki flagi przeniesienia. Następne dwie instrukcje w kodzie korzystają z trybu adresowania bezpośredniego. W przypadku adresowania bezpośredniego istnieje tylko jeden operand mnemonika, którym jest liczba (a nie adres pamięci ani rejestru). Dlatego numer musi być poprzedzony znakiem „#”. „$” oznacza, że następująca po nim liczba jest szesnastkowa.
Druga instrukcja ładuje liczbę 3F 16 do akumulatora. W przypadku trzeciej instrukcji obwód jednostki arytmetyczno-logicznej µP pobiera poprzednie (wyczyszczone) przeniesienie 0 (wymuszone do wartości 0) komórki flagi przeniesienia, rejestru stanu i dodaje je do 15 16 jak również do wartości, która jest już w 3F 16 akumulatorze i umieszcza cały wynik z powrotem w akumulatorze. W tym przypadku wynikowe przeniesienie wynosi 0. Jednostka ALU (Arithmetic Logic Unit) wysyła (wstawia) 0 do komórki flagi przeniesienia rejestru stanu. Rejestr stanu procesora i rejestr stanu oznaczają to samo. Jeśli nastąpiło przeniesienie 1, jednostka ALU wysyła 1 do flagi przeniesienia rejestru stanu.
Trzy linie poprzedniego kodu muszą znajdować się w pamięci, zanim zostaną wykonane. Kod operacji 1816 dla CLC (adresowanie implikowane) znajduje się w lokalizacji bajtowej $0200. Kod operacji A9 16 dla LDA (adresowanie natychmiastowe) znajduje się w lokalizacji bajtowej $0201. Liczba 3F 10 znajduje się w lokalizacji bajtowej $0202. Kod operacji 69 16 dla LDA (adresowanie natychmiastowe) znajduje się w lokalizacji bajtowej $0203. Numer 15 10 znajduje się w lokalizacji bajtowej $0204.
Notatka: LDA jest instrukcją przesyłania (ładowania), a nie instrukcją arytmetyczną (mnemoniką).
Kod dodający dwa szesnaście bitów bez znaku
Wszystkie rejestry w 6502 µP są zasadniczo rejestrami ośmiobitowymi, z wyjątkiem PC (licznika programów), który jest 16-bitowy. Nawet rejestr stanu ma szerokość 8 bitów, chociaż jego osiem bitów nie działa razem. W tej sekcji rozważane jest dodanie dwóch 16 bitów bez znaku, z przeniesieniem z pierwszej pary ośmiu bitów do drugiej pary ośmiu bitów. Interesujące przeniesienie to przeniesienie z ósmej pozycji bitu do dziewiątej pozycji bitu.
Niech liczby będą wynosić 0010101010111111 2 = 2ABF16 16 = 10943 10 i 0010101010010101 2 = 2A95 16 = 10901 10 . Suma wynosi 0101010101010100 2 = 5554 16 = 21844 10 .
Dodanie tych dwóch liczb bez znaku w podstawie drugiej wygląda następująco:

Poniższa tabela przedstawia to samo dodanie z przeniesieniem 1 z ósmego bitu na dziewiątą pozycję, zaczynając od prawej:
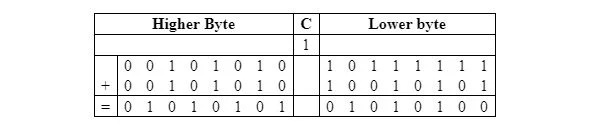
Podczas kodowania najpierw dodawane są dwa dolne bajty. Następnie jednostka ALU (jednostka arytmetyczno-logiczna) wysyła przeniesienie wartości 1 z pozycji ósmego bitu na pozycję dziewiątego bitu do komórki flagi przeniesienia w rejestrze stanu. Wynik 0 1 0 1 0 1 0 0 bez przeniesienia trafia do akumulatora. Następnie wraz z przeniesieniem dodawana jest druga para bajtów. Mnemonik ADC oznacza automatyczne dodawanie z poprzednim przeniesieniem. W takim przypadku poprzednie przeniesienie, czyli 1, nie może zostać zmienione przed drugim dodaniem. W przypadku pierwszego dodania, ponieważ żadne poprzednie przeniesienie nie jest częścią tego pełnego dodania, należy je wyczyścić (ustawić 0).
Aby całkowicie dodać dwie pary bajtów, pierwszym dodatkiem jest:
A + M + 0 -> A
Drugi dodatek to:
A + M + 1 -> A
Zatem flaga przeniesienia musi zostać wyczyszczona (przy wartości 0) tuż przed pierwszym dodaniem. Następujący program, którego wyjaśnienie czytelnik musi przeczytać poniżej, wykorzystuje do tego sumowania tryb adresowania bezwzględnego:
WŻCH
LDA 0213 dolarów
ADC 0215 dolarów
; brak rozliczeń, ponieważ wymagana jest wartość flagi przeniesienia
STA $0217
LDA 0214 dolarów
ADC 0216 dolarów
STA $0218
Zauważ, że w języku asemblera 6502 średnik zaczyna się od komentarza. Oznacza to, że podczas wykonywania programu średnik i wszystko po jego prawej stronie jest ignorowane. Program napisany wcześniej, znajdujący się w pliku tekstowym, zapisywany jest pod wybraną przez programistę nazwą i rozszerzeniem „.asm”. Poprzedni program nie jest dokładnie tym samym programem, który trafia do pamięci w celu wykonania. Odpowiedni program w pamięci nazywany jest programem przetłumaczonym, w którym mnemoniki są zastępowane kodami operacji (bajtami). Wszelkie komentarze pozostają w pliku tekstowym języka asemblera i są usuwane, zanim przetłumaczony program dotrze do pamięci. W rzeczywistości na dysku zapisywane są obecnie dwa pliki: plik „.asm” i plik „.exe”. Plik „.asm” to plik pokazany na poprzedniej ilustracji. Plik „.exe” to plik „.asm” z usuniętymi wszystkimi komentarzami i wszystkimi mnemonikami zastąpionymi ich opkodami. Po otwarciu w edytorze tekstu plik „.exe” jest nierozpoznawalny. O ile nie zaznaczono inaczej, na potrzeby tego rozdziału plik „.exe” jest kopiowany do pamięci, zaczynając od lokalizacji $0200. To jest drugie znaczenie ładowania.
Dwie dodawane liczby 16-bitowe zajmują cztery bajty w pamięci w celu adresowania bezwzględnego: po dwa bajty na liczbę (pamięć jest sekwencją bajtów). W przypadku adresowania bezwzględnego operand kodu operacji znajduje się w pamięci. Wynik sumowania ma szerokość dwóch bajtów i również należy go umieścić w pamięci. Daje to w sumie 6 10 = 6 16 bajtów dla wejść i wyjść. Dane wejściowe nie pochodzą z klawiatury, a dane wyjściowe nie pochodzą z monitora ani drukarki. W tej sytuacji dane wejściowe znajdują się w pamięci (RAM), a dane wyjściowe (wynik sumowania) wracają do pamięci (RAM).
Zanim program zostanie wykonany, przetłumaczona wersja musi najpierw znaleźć się w pamięci. Patrząc na poprzedni kod programu widać, że instrukcje bez komentarza tworzą 19 10 = 13 16 bajty. Zatem program pobiera z lokalizacji bajtów 0200 $ w pamięci do lokalizacji bajtów 0200 $ + 13 $ – 1 $ = 0212 bajtów (zaczynając od lokalizacji 0200 $, a nie 0201 $, co oznacza – 1 $). Dodanie 6 bajtów dla liczb wejściowych i wyjściowych powoduje, że cały program kończy się na 0212 $ + 6 $ = 0218 $. Całkowita długość programu wynosi 19 16 = 25 10 .
Dolny bajt tego samego augenda powinien znajdować się pod adresem $0213, a wyższy bajt tego samego augenda powinien znajdować się pod adresem $0214 – small endianness. Podobnie dolny bajt dodatku powinien znajdować się pod adresem $0215, a wyższy bajt tego samego dodatku powinien znajdować się pod adresem $0216 – small endianness. Dolny bajt wyniku (suma) powinien znajdować się pod adresem $0217, natomiast wyższy bajt tego samego wyniku powinien znajdować się pod adresem $0218 – small endianness.
Kod operacji 18 16 dla CLC (adresowanie implikowane) znajduje się w lokalizacji bajtowej $0200. Kod operacji dla „LDA $0213”, tj. AD 16 dla LDA (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0201. Dolny bajt augendu, czyli 10111111, znajduje się w lokalizacji bajtu pamięci $0213. Pamiętaj, że każdy kod operacji zajmuje jeden bajt. Adres „$0213” adresu „LDA $0213” znajduje się w lokalizacjach bajtów $0202 i $0203. Instrukcja „LDA $0213” ładuje do akumulatora niższy bajt augendu.
Kod operacji dla „ADC $0215”, tj. 6D 16 dla ADC (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0204. Dolny bajt dodatku, czyli 10010101, znajduje się w lokalizacji bajtowej $0215. Adres „$0215” modułu „ADC $0215” znajduje się w lokalizacjach bajtów $0205 i $0206. Instrukcja „ADC $0215” dodaje dolny bajt dodatku do młodszego bajtu augendu, który znajduje się już w akumulatorze. Wynik jest ponownie umieszczany w akumulatorze. Każde przeniesienie po ósmym bicie jest wysyłane do flagi przeniesienia rejestru stanu. Komórka flagi przeniesienia nie może zostać wyczyszczona przed drugim dodaniem wyższych bajtów. To przeniesienie jest automatycznie dodawane do sumy wyższych bajtów. W rzeczywistości przeniesienie wynoszące 0 jest dodawane automatycznie na początku do sumy dolnych bajtów (co jest równoznaczne z brakiem dodawania przeniesienia) z powodu CLC.
Komentarz zajmuje kolejne 48 10 = 30 16 bajty. Jednak pozostaje to tylko w pliku tekstowym „.asm”. Nie dociera do pamięci. Jest on usuwany poprzez tłumaczenie wykonywane przez asembler (program).
Dla następnej instrukcji, czyli „STA $0217”, kod operacji STA to 8D 16 (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0207. Adres „$0217” adresu „STA $0217” znajduje się w komórkach pamięci $0208 i $0209. Instrukcja „STA $0217” kopiuje ośmiobitową zawartość akumulatora do komórki pamięci $0217.
Wyższy bajt dodatku, czyli 00101010, znajduje się w lokalizacji pamięci $0214, a wyższy bajt dodatku, czyli 00101010, znajduje się w lokalizacji bajtowej $02 16 . Kod operacji dla „LDA $0214”, który dla LDA (adresowanie absolutne) wynosi AD16, znajduje się w lokalizacji bajtowej $020A. Adres „$0214” domeny „LDA $0214” znajduje się w lokalizacjach $020B i $020C. Instrukcja „LDA $0214” ładuje wyższy bajt augendu do akumulatora, kasując wszystko, co jest w akumulatorze.
Kod operacji dla „ADC $0216”, czyli 6D 16 dla ADC (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $020D. Adres „$0216” modułu „ADC 0216” znajduje się w lokalizacjach bajtów $020E i $020F. Instrukcja „ADC $0216” dodaje wyższy bajt dodatku do wyższego bajtu augendu, który znajduje się już w akumulatorze. Wynik jest ponownie umieszczany w akumulatorze. Jeśli istnieje przeniesienie wynoszące 1, dla tego drugiego dodania jest ono automatycznie umieszczane w komórce przeniesienia rejestru stanu. Chociaż przeniesienie poza szesnasty bit (po lewej) nie jest wymagane w przypadku tego problemu, dobrze jest sprawdzić, czy nastąpiło przeniesienie 1, sprawdzając, czy flaga przeniesienia zmieniła się na 1.
Dla następnej i ostatniej instrukcji, czyli „STA $0218”, kod operacji STA, który wynosi 8D16 (adresowanie absolutne), znajduje się w lokalizacji bajtowej $0210. Adres „$0218” adresu „STA $0218” znajduje się w komórkach pamięci $0211 i $0212. Instrukcja „STA $0218” kopiuje ośmiobitową zawartość akumulatora do komórki pamięci $0218. Wynikiem dodania dwóch szesnastobitowych liczb jest 0101010101010100, z niższym bajtem 01010100 w komórce pamięci o wartości 0217 $ i wyższym bajtem 01010101 w komórce pamięci o wartości 0218 $ – mała końcówka.
Odejmowanie
W przypadku 6502 µP liczby ze znakiem są liczbami uzupełnionymi do dwójki. Liczba uzupełniona do dwójki może składać się z ośmiu bitów, szesnastu bitów lub dowolnej wielokrotności ośmiu bitów. W przypadku uzupełnienia do dwójki pierwszy bit od lewej strony jest bitem znaku. W przypadku liczby dodatniej ten pierwszy bit ma wartość 0, co oznacza znak. Pozostałe bity tworzą liczbę w normalny sposób. Aby uzyskać uzupełnienie do dwójki liczby ujemnej, odwróć wszystkie bity odpowiedniej liczby dodatniej, a następnie dodaj 1 do wyniku z prawej strony.
Aby odjąć jedną liczbę dodatnią od innej liczby dodatniej, odejmowanie jest konwertowane na liczbę ujemną z uzupełnieniem do dwóch. Następnie w zwykły sposób dodaje się odjemną i nową liczbę ujemną. Zatem odejmowanie ośmiu bitów ma postać:
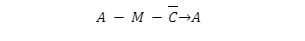
Przyjmuje się, że przeniesienie wynosi 1. Wynikiem w akumulatorze jest różnica w uzupełnieniu do dwójki. Zatem, aby odjąć dwie liczby, należy ustawić flagę przeniesienia (na 1).
Podczas odejmowania dwóch liczb szesnastobitowych odejmowanie wykonuje się dwukrotnie, podobnie jak w przypadku dodawania dwóch liczb szesnastobitowych. Ponieważ odejmowanie jest formą dodawania w 6502 µP, przy odejmowaniu dwóch liczb szesnastobitowych flaga przeniesienia jest ustawiana tylko raz dla pierwszego odejmowania. W przypadku drugiego odejmowania dowolne ustawienie flagi przeniesienia odbywa się automatycznie.
Programowanie odejmowania dla liczb ośmiobitowych lub szesnastobitowych odbywa się w podobny sposób jak programowanie dodawania. Jednak flagę przeniesienia należy ustawić już na samym początku. Aby to zrobić, mnemonik jest następujący: 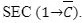
Odejmowanie z szesnastobitowymi liczbami dodatnimi
Rozważ odejmowanie za pomocą następujących liczb:

To odejmowanie nie obejmuje uzupełnienia do dwóch. Ponieważ odejmowanie w 6502 µP odbywa się w uzupełnieniu do dwóch, odejmowanie w podstawie dwa odbywa się w następujący sposób:
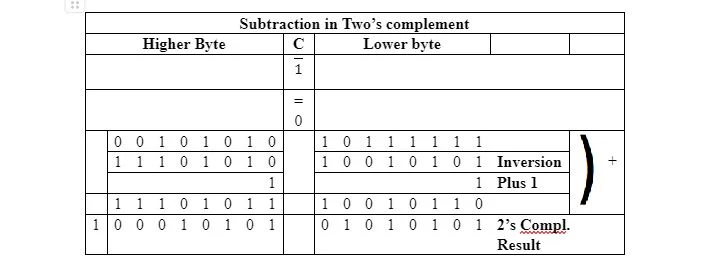
Wynik uzupełnienia dwóch jest taki sam, jak wynik uzyskany ze zwykłego odejmowania. Należy jednak pamiętać, że 1, która przechodzi do pozycji siedemnastego bitu od prawej strony, jest ignorowana. Minuend i odejmowanie są podzielone na dwa osiem bitów każdy. Uzupełnienie do dwójki 10010110 dolnego bajtu odjemnika jest określane niezależnie od jego wyższego bajtu i jakiegokolwiek przeniesienia. Uzupełnienie dwójkowe 11101011 wyższego bajtu odjemnika jest określane niezależnie od jego młodszego bajtu i jakiegokolwiek przeniesienia.
16-bitowa odjemna jest już w uzupełnieniu do dwóch, zaczynając od 0 od lewej. Zatem nie wymaga żadnej regulacji w bitach. W przypadku 6502 µP dolny bajt odejmowania jest dodawany bez żadnych modyfikacji do dolnego bajtu uzupełnienia do dwójki odejmowania. Dolny bajt odejmowanej nie jest konwertowany w uzupełnieniu do dwóch, ponieważ szesnaście bitów całej odejmowanej musi już znajdować się w uzupełnieniu do dwóch (z 0 jako pierwszym bitem po lewej stronie). W tym pierwszym dodaniu dodano obowiązkowe przeniesienie 1 ze względu na instrukcję 1=0 SEC.
W bieżącym efektywnym odejmowaniu następuje przeniesienie 1 (dodawania) z ósmego bitu do dziewiątego bitu (od prawej). Ponieważ jest to w rzeczywistości odejmowanie, dowolny bit, który powinien znajdować się we fladze przeniesienia w rejestrze stanu, jest uzupełniany (odwrócony). Zatem przeniesienie 1 staje się 0 we fladze C. W drugiej operacji wyższy bajt odjemnika jest dodawany do wyższego bajtu uzupełnienia dwójki odejmowania. Automatycznie uzupełniany bit flagi przeniesienia rejestru stanu (w tym przypadku wynosi 0) jest również dodawany (do wyższych bajtów). Każda wartość 1 wykraczająca poza szesnasty bit od prawej strony jest ignorowana.
Następną rzeczą jest po prostu zakodowanie całego tego schematu w następujący sposób:
SEK
LDA 0213 dolarów
SBC 0215 dolarów
; brak czyszczenia, ponieważ wymagana jest odwrócona wartość flagi przeniesienia
STA $0217
LDA 0214 dolarów
SBC 0216 dolarów
STA $0218
Pamiętaj, że w języku asemblera 6502 średnik rozpoczyna komentarz, który nie jest uwzględniany w pamięci przetłumaczonej wersji programu. Dwie 16-bitowe liczby do odejmowania zajmują cztery bajty pamięci przy adresowaniu bezwzględnym; dwa na liczbę (pamięć to ciąg bajtów). Dane wejściowe nie pochodzą z klawiatury. Wynik sumowania wynosi dwa bajty i również musi zostać umieszczony w pamięci w innym miejscu. To wyjście nie trafia do monitora ani drukarki; trafia do pamięci. Daje to w sumie 6 10 = 6 16 bajty wejść i wyjść umieszczane w pamięci (RAM).
Zanim program zostanie wykonany, musi najpierw znaleźć się w pamięci. Patrząc na kod programu widać, że instrukcje bez komentarza tworzą 19 10 = 13 16 bajty. Ponieważ wszystkie programy w tym rozdziale rozpoczynają się od lokalizacji w pamięci wynoszącej 0200 USD, program przechodzi od lokalizacji bajtów wynoszącej 0200 USD w pamięci do lokalizacji bajtów wynoszącej 0200 USD + 13 USD – 1 USD = 0212 USD (zaczynając od lokalizacji 0200 USD, a nie 0201 USD). Ten zakres nie obejmuje obszaru bajtów wejściowych i wyjściowych. Dwie liczby wejściowe zajmują 4 bajty, a jedna liczba wyjściowa zajmuje 2 bajty. Dodanie 6 bajtów liczb wejściowych i wyjściowych powoduje, że zakres programu kończy się na 0212 $ + 6 $ = 0218 $. Całkowita długość programu wynosi 19 16 = 25 10 .
Dolny bajt tej odejmowanej wartości powinien znajdować się pod adresem $0213, a wyższy bajt tej samej odejmowanej wartości powinien znajdować się pod adresem $0214 – mała końcówka. Podobnie, dolny bajt odjemnika powinien znajdować się w adresie $0215, a wyższy bajt tego samego odjemnika powinien znajdować się pod adresem $0216 – small endianness. Dolny bajt wyniku (różnica) powinien znajdować się pod adresem $0217, natomiast wyższy bajt tego samego wyniku powinien znajdować się pod adresem $0218 – small endianness.
Kod operacji 38 16 dla SEC (adresowanie implikowane) znajduje się w adresie $0200. Zakłada się, że wszystkie programy w tym rozdziale rozpoczynają się w lokalizacji pamięci 0200 $, co anuluje każdy program, który by się tam znajdował; chyba że określono inaczej. Kod operacji dla „LDA $0213”, tj. AD 16 , dla LDA (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0201. Dolny bajt odjemnika, który wynosi 10111111, znajduje się w lokalizacji bajtu pamięci $0213. Pamiętaj, że każdy kod operacji zajmuje jeden bajt. Adres „$0213” adresu „LDA $0213” znajduje się w lokalizacjach bajtów $0202 i $0203. Instrukcja „LDA $0213” ładuje do akumulatora niższy bajt odjemnika.
Kod operacji dla „SBC $0215”, tj. ED 16 , dla SBC (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0204. Dolny bajt odejmowania, który wynosi 01101010, znajduje się w lokalizacji bajtowej $0215. Adres „$0215” modułu „ADC $0215” znajduje się w lokalizacjach bajtów $0205 i $0206. Instrukcja „SBC $0215” odejmuje dolny bajt odejmowania od dolnego bajtu odejmowania, który znajduje się już w akumulatorze. To jest odejmowanie z uzupełnieniem do dwóch. Wynik jest ponownie umieszczany w akumulatorze. Uzupełnienie (inwersja) dowolnego przeniesienia po ósmym bicie jest wysyłane do flagi przeniesienia rejestru stanu. Ta flaga przeniesienia nie może zostać wyczyszczona przed drugim odjęciem wyższych bajtów. To przeniesienie jest automatycznie dodawane do odejmowania wyższych bajtów.
Komentarz zajmuje kolejne 57 10 = 3916 16 bajty. Jednak pozostaje to tylko w pliku tekstowym „.asm”. Nie dociera do pamięci. Jest on usuwany poprzez tłumaczenie wykonywane przez asembler (program).
Dla następnej instrukcji, czyli „STA $0217”, kod operacji STA, tj. 8D 16 (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0207. Adres „$0217” adresu „STA $0217” znajduje się w komórkach pamięci $0208 i $0209. Instrukcja „STA $0217” kopiuje ośmiobitową zawartość akumulatora do komórki pamięci $0217.
Wyższy bajt odejmowania, czyli 00101010, znajduje się w lokalizacji pamięci 0214 $, a wyższy bajt odejmowania, czyli 00010101, znajduje się w lokalizacji bajtu 0216 $. Kod operacji dla „LDA $0214”, tj. AD 16 dla LDA (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $020A. Adres „$0214” domeny „LDA $0214” znajduje się w lokalizacjach $020B i $020C. Instrukcja „LDA $0214” ładuje wyższy bajt odjemnika do akumulatora, kasując wszystko, co jest w akumulatorze.
Kod operacji dla „SBC $0216”, tj. ED 16 dla SBC (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $020D. Adres „$0216” bloku „SBC $0216” znajduje się w lokalizacjach bajtów $020E i $020F. Instrukcja „SBC $0216” odejmuje wyższy bajt odejmowania od wyższego bajtu odejmowania (dopełnienia do dwóch), który znajduje się już w akumulatorze. Wynik jest ponownie umieszczany w akumulatorze. Jeżeli dla tego drugiego odejmowania występuje przeniesienie wynoszące 1, jego uzupełnienie jest automatycznie umieszczane w komórce przeniesienia rejestru stanu. Chociaż przeniesienie poza szesnasty bit (po lewej) nie jest wymagane w przypadku tego problemu, dobrze jest sprawdzić, czy nastąpi przeniesienie uzupełnienia, sprawdzając flagę przeniesienia.
Dla następnej i ostatniej instrukcji, czyli „STA $0218”, kod operacji STA, tj. 8D 16 (adresowanie bezwzględne) znajduje się w lokalizacji bajtowej $0210. Adres „$0218” adresu „STA $0218” znajduje się w komórkach pamięci $0211 i $0212. Instrukcja „STA $0218” kopiuje ośmiobitową zawartość akumulatora do komórki pamięci $0218. Wynikiem odejmowania dwóch szesnastobitowych liczb jest 0001010101010101 z niższym bajtem 01010101 w komórce pamięci 0217 $ i wyższym bajtem 00010101 w komórce pamięci 0218 $ – mała końcówka.
Model 6502 µP ma obwody służące wyłącznie do dodawania i pośrednio do odejmowania dopełnienia do dwóch. Nie ma obwodów do mnożenia i dzielenia. Aby wykonać mnożenie i dzielenie, należy napisać program w języku asemblera ze szczegółami, w tym przesunięciem częściowych iloczynów i częściowych dzielnych.
4.4 Operacje logiczne
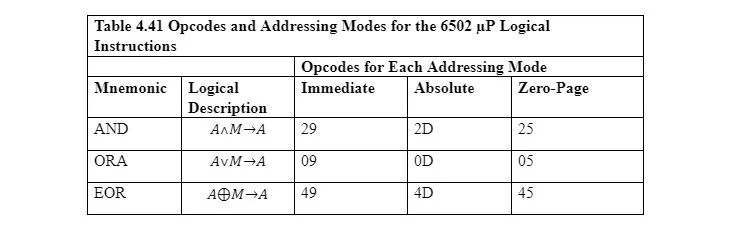
W 6502 µP mnemonikiem OR jest ORA, a mnemonikiem wyłącznego OR jest EOR. Zauważ, że operacje logiczne nie mają implikowanego adresowania. Domniemane adresowanie nie wymaga żadnego argumentu. Każdy z operatorów logicznych musi przyjmować dwa operandy. Pierwszy znajduje się w akumulatorze, drugi w pamięci lub w instrukcji. Wynik (8 bitów) jest ponownie umieszczany w akumulatorze. Pierwsza w akumulatorze jest albo umieszczana tam instrukcją natychmiastową, albo kopiowana z pamięci z adresowaniem absolutnym. W tej sekcji dla ilustracji użyto jedynie adresowania strony zerowej. Wszystkie te operatory logiczne są operatorami bitowymi.
I
Poniższa tabela ilustruje bitowe AND w formacie binarnym, szesnastkowym i dziesiętnym:
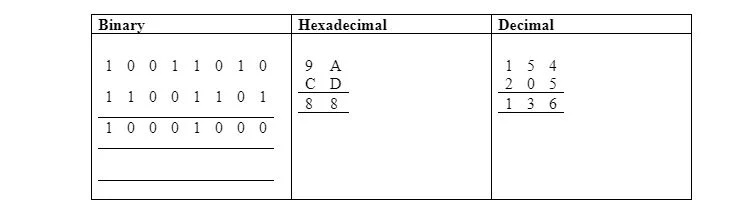
Wszystkie programy opisane w tym rozdziale powinny zaczynać się od bajtu pamięci o wartości 0200 $. Jednakże programy w tej sekcji znajdują się na stronie zerowej, a ich celem jest zilustrowanie użycia strony zerowej bez wyższego bajtu 00000000 2 . Poprzednie ANDowanie można zakodować w następujący sposób:
LDA #9A; nie z pamięci – adresowanie natychmiastowe
ORAZ #$CD ; nie z pamięci – adresowanie natychmiastowe
STA $30; przechowuje 88 USD przy wartości zerowej 0030 USD
LUB
Poniższa tabela ilustruje bitowe LUB w formacie binarnym, szesnastkowym i dziesiętnym:
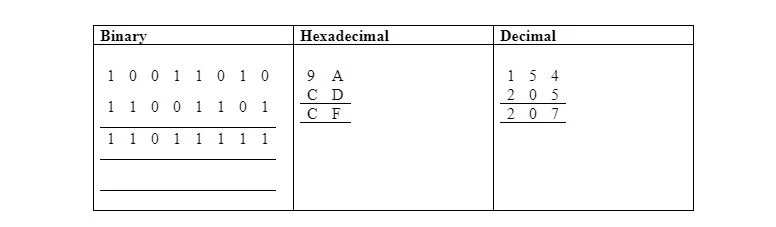
LDA #9A; nie z pamięci – adresowanie natychmiastowe
ORA #$CD ; nie z pamięci – adresowanie natychmiastowe
STA $30; przechowuje $CF w oparciu o zero $0030
BEZPŁATNY
Poniższa tabela ilustruje bitowy XOR w formacie binarnym, szesnastkowym i dziesiętnym:

LDA #9A; nie z pamięci – adresowanie natychmiastowe
EOR #$CD ; nie z pamięci – adresowanie natychmiastowe
STA $30; przechowuje 57 USD przy wartości zerowej 0030 USD
4.5 Operacje przesuwania i obracania
Mnemoniki i kody operatorów przesuwania i obracania to:
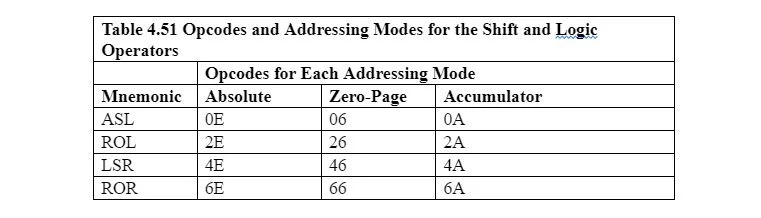
ASL: Przesuń w lewo jeden bit akumulatora lub lokalizacji pamięci, wstawiając 0 w pustej komórce znajdującej się najbardziej na prawo.
LSR: Przesuń w prawo o jeden bit akumulatora lub lokalizacji pamięci, wstawiając 0 w pustej komórce znajdującej się skrajnie po lewej stronie.
ROL: Obróć jeden bit w lewo od akumulatora lub lokalizacji pamięci, wkładając bit, który został usunięty po lewej stronie, do pustej komórki znajdującej się najbardziej na prawo.
ROR: Obróć jeden bit w prawo od miejsca przechowywania akumulatora lub pamięci, wkładając bit, który został usunięty z prawej strony, do pustej komórki znajdującej się skrajnie po lewej stronie.
Aby wykonać przesunięcie lub obrót za pomocą akumulatora, instrukcja wygląda mniej więcej tak:
LSR A
Wykorzystuje to inny tryb adresowania, zwany trybem adresowania akumulatorowego.
Aby wykonać przesunięcie lub obrót w lokalizacji pamięci bajtowej, instrukcja wygląda mniej więcej tak:
ROR 2BCD
Gdzie 2BCD to lokalizacja pamięci.
Należy pamiętać, że nie ma bezpośredniego ani domniemanego trybu adresowania w przypadku przesuwania lub obracania. Nie ma trybu adresowania natychmiastowego, gdyż nie ma sensu przesuwać lub obracać liczby, która pozostaje tylko w instrukcji. Nie ma żadnego sugerowanego trybu adresowania, ponieważ projektanci 6502 µP chcą, aby przesuwana lub obracana była tylko zawartość akumulatora (rejestr A) lub lokalizacja bajtu pamięci.
4.6 Tryb adresowania względnego
Mikroprocesor zawsze zwiększa (o 1, 2 lub 3 jednostki) licznik programu (PC), aby wskazać następną instrukcję, która ma zostać wykonana. 6502 µP posiada instrukcję, której mnemonik to BVS, co oznacza rozgałęzienie na zestawie przepełnienia. Komputer składa się z dwóch bajtów. Ta instrukcja powoduje, że komputer PC ma inny adres pamięci dla wykonania następnej instrukcji, która nie wynika z normalnego przyrostu. Czyni to poprzez dodanie lub odejmowanie wartości zwanej przesunięciem od zawartości komputera. W ten sposób komputer PC wskazuje następnie inną (rozgałęzioną) lokalizację pamięci, z której komputer może kontynuować wykonywanie. Przesunięcie jest liczbą całkowitą od -128 10 do +127 10 (uzupełnienie do dwóch). Zatem przesunięcie może sprawić, że skok będzie kontynuowany w pamięci. Czy jest pozytywny, czy opóźniony w pamięci, czy też negatywny.
Instrukcja BVS przyjmuje tylko jeden operand, który jest offsetem. BVS używa adresowania względnego. Rozważ następującą instrukcję:
BVS 7F
W bazie drugiej, 7F H to 01111111 2 = 127 10 . Załóżmy, że zawartość następnej instrukcji na komputerze PC wynosi 0300 USD. Instrukcja BVS powoduje dodanie 7F (liczba dodatnia już w uzupełnieniu do dwóch) do 0300 USD, co daje 037F. Zatem zamiast następnej instrukcji, która ma zostać wykonana w lokalizacji pamięci 0300 USD, znajduje się ona w lokalizacji pamięci 037F (około pół strony różnicy).
Istnieją inne instrukcje rozgałęzień, ale BVS jest bardzo dobrą instrukcją do zilustrowania adresowania względnego. Adresowanie względne dotyczy instrukcji rozgałęzień.
4.7 Oddzielne adresowanie indeksowane i pośrednie
Te tryby adresowania umożliwiają procesorowi 6502 µP obsługę ogromnych ilości danych w krótkich okresach czasu przy zmniejszonej liczbie instrukcji. Na całą pamięć Comodore-64 przypada 64 KB lokalizacji. Zatem, aby uzyskać dostęp do dowolnej lokalizacji bajtowej składającej się z 16 bitów, potrzebne są dwa bajty. Jedynym wyjątkiem od konieczności użycia dwóch bajtów jest strona zerowa, gdzie wyższy bajt 00 $ jest pominięty, aby zaoszczędzić miejsce zajmowane przez instrukcję w pamięci. W trybie adresowania niezerowego, zarówno wyższe, jak i niższe bajty 16-bitowego adresu pamięci są przeważnie w jakiś sposób wskazywane.
Podstawowe adresowanie indeksowane
Adresowanie indeksu bezwzględnego
Pamiętaj, że rejestr X lub Y nazywany jest rejestrem indeksowym. Rozważ następującą instrukcję:
LDA $C453,X
Załóżmy, że wartość 6 H jest w rejestrze X. Należy zwrócić uwagę, że w instrukcji nie wpisano cyfry 6. Ta instrukcja dodaje wartość 6H do C453 H który jest częścią instrukcji wpisanej w pliku tekstowym, który należy jeszcze złożyć – C453 H + 6 H = C459 H . LDA oznacza załadowanie bajtu do akumulatora. Bajt do załadowania do akumulatora pochodzi z adresu $C459. $C459, czyli suma $C453 wpisana wraz z instrukcją i liczbą 6 H znaleziony w rejestrze X staje się adresem efektywnym, z którego pochodzi bajt ładowany do akumulatora. Jeśli 6 H znajdował się w rejestrze Y, w instrukcji w miejsce X wpisuje się Y.
W instrukcji wpisanej $C453 jest znane jako adres podstawowy i 6 H w rejestrze X lub Y jest nazywana częścią zliczającą lub indeksującą adresu efektywnego. Adres bazowy może odnosić się do dowolnego adresu bajtowego w pamięci, a następny 256 10 adresy są dostępne pod warunkiem, że rozpoczęty indeks (lub licznik) w rejestrze X lub Y wynosi 0. Należy pamiętać, że jeden bajt może dawać ciągły zakres do 256 10 cyfry (tj. 00000000 2 pod numer 11111111 2 ).
Zatem adresowanie bezwzględne dodaje to, co już zostało umieszczone (umieszczone przez inną instrukcję) w rejestrze X lub Y, do 16 adresów wpisanych wraz z instrukcją w celu uzyskania adresu efektywnego. W instrukcji tekstowej oba rejestry indeksowe są rozróżniane za pomocą X lub Y, które są wpisywane po przecinku. Wpisano X lub Y; nie oba.
Przecież program jest wpisywany w edytorze tekstu i zapisywany z rozszerzeniem „.asm”, asembler, który jest innym programem, musi przetłumaczyć wpisany program na to, co jest (załadowane) w pamięci. Poprzednia instrukcja, czyli „LDA $C453,X”, zajmuje w pamięci trzy bajty, a nie pięć.
Pamiętaj, że mnemonik taki jak LDA może mieć więcej niż jeden kod operacji (różne bajty). Kod operacji dla instrukcji korzystającej z rejestru X różni się od kodu operacji wykorzystującego rejestr Y. Asembler wie, jakiego opkodu użyć na podstawie wpisanej instrukcji. Jednobajtowy kod operacji dla „LDA $C453,X” różni się od jednobajtowego kodu operacji dla „LDA $C453,Y”. W rzeczywistości kod operacji dla LDA w „LDA $C453,X” to BD, a kod operacji dla LDA w „LDA $C453,9” to BD.
Jeśli kod operacji dla LDA znajduje się w lokalizacji bajtowej $0200. Następnie 16-bitowy adres $C453 zajmuje następny bajt w pamięci, czyli $0201 i $0202. Konkretny bajt kodu operacji wskazuje, czy chodzi o rejestr X, czy o rejestr Y. I tak złożona instrukcja językowa „LDA $C453,X” lub „LDA $C453,Y” zajmuje w pamięci trzy kolejne bajty, a nie cztery czy pięć.
Adresowanie indeksowane o zerowej stronie
Adresowanie indeksu strony zerowej jest podobne do adresowania indeksu bezwzględnego, które zostało opisane wcześniej, ale bajt docelowy musi znajdować się tylko na stronie zerowej (od 0000 $ do 00FF). Teraz, gdy mamy do czynienia ze stroną zerową, wyższy bajt, który zawsze ma wartość 00 H ponieważ zwykle unika się lokalizacji pamięci. Dlatego zwykle wspomina się, że strona zerowa zaczyna się od 00 $ do FF. I tak poprzednia instrukcja „LDA $C453,X” wygląda następująco:
LDA 53,X
$C4, wyższy bajt odnoszący się do strony powyżej strony zerowej, nie może zostać użyty w tej instrukcji, ponieważ umieszcza oczekiwany bajt docelowy, który ma zostać załadowany do skumulowanego bajtu na zewnątrz i powyżej strony zerowej.
Gdy wartość wpisaną w instrukcji zostanie dodana do wartości w rejestrze indeksowym, suma nie powinna dać wyniku powyżej strony zerowej (FF H ). Zatem nie ma mowy o instrukcji takiej jak „LDA $FF, X” i wartości takiej jak FF H w rejestrze indeksowym, ponieważ FF H +FF H = 200 H która jest lokalizacją pierwszego bajtu (0200 $) strony 2 (trzeciej strony) w pamięci, znajduje się w dużej odległości od strony 0. Zatem przy adresowaniu indeksowanym o zerowej stronie adres efektywny musi znajdować się na stronie zerowej.
Adresowanie pośrednie
Skok adresowania bezwzględnego
Przed omówieniem bezwzględnego adresowania pośredniego dobrze jest najpierw przyjrzeć się adresowaniu bezwzględnemu JMP. Załóżmy, że adres o wartości interesującej (bajt docelowy) wynosi 8765 USD. Jest to 16 bitów składających się z dwóch bajtów: wyższy bajt wynosi 87 H i dolny bajt, który wynosi 65 H . Zatem dwa bajty wartości 8765 dolarów są umieszczane w komputerze PC (licznik programu) dla następnej instrukcji. To, co jest wpisane w programie (pliku) w języku asemblera, to:
JMP 8765 dolarów
Wykonujący się program w pamięci przeskakuje z dowolnego adresu, do którego uzyskał dostęp, do 8765 $. Mnemonik JMP ma trzy kody operacji: 4C, 6C i 7C. Kod operacji dla tego adresowania bezwzględnego to 4C. Kod operacji dla absolutnego adresowania pośredniego JMP to 6C (patrz poniższe ilustracje).
Absolutne adresowanie pośrednie
Jest to używane tylko z instrukcją skoku (JMP). Załóżmy, że adres zawierający interesujący bajt (bajt docelowy) to 8765 $. Jest to 16 bitów składających się z dwóch bajtów: wyższy bajt wynosi 87 H i dolny bajt, który wynosi 65 H . W przypadku absolutnego adresowania pośredniego te dwa bajty są w rzeczywistości zlokalizowane w dwóch kolejnych lokalizacjach bajtów gdzie indziej w pamięci.
Załóżmy, że znajdują się one w komórkach pamięci $0210 i $0211. Następnie dolny bajt adresu będącego przedmiotem zainteresowania wynosi 65 H znajduje się w adresie $0210, a wyższy bajt to 87 H znajduje się pod adresem $0211. Oznacza to, że niższy bajt pamięci trafia do niższego kolejnego adresu, a wyższy interesujący bajt pamięci trafia do wyższego kolejnego adresu – small endianness.
Adres 16-bitowy może odnosić się do dwóch kolejnych adresów w pamięci. W tym świetle adres $0210 odnosi się do adresów $0210 i $0211. Para adresów $0210 i $0211 zawiera ostateczny adres (16 bitów po dwa bajty) bajtu docelowego, z dolnym bajtem 65 H w $0210 i wyższym bajcie 87 H w cenie 0211 USD. Zatem wpisana instrukcja skoku to:
JMP (0210 USD)
Mnemonik JMP ma trzy kody operacji: 4C, 6C i 7C. Kod operacji dla absolutnego adresowania pośredniego to 6C. W pliku tekstowym wpisano „JMP ($0210)”. Ze względu na nawiasy asembler (tłumacz) używa kodu operacji 6C dla JMP, a nie 4C lub 7C.
W przypadku absolutnego adresowania pośredniego istnieją w rzeczywistości trzy obszary pamięci. Pierwszy region może składać się z lokalizacji bajtów $0200, $0201 i $0202. Zawiera trzy bajty dla instrukcji „JMP ($0210)”. Drugi region, który niekoniecznie znajduje się obok pierwszego, składa się z dwóch kolejnych lokalizacji bajtów: 0210 $ i 0211 $. Jest to niższy bajt ($0210), który jest wpisywany w instrukcji programu w języku asemblera. Jeśli adres zainteresowania to 8765 USD, dolny bajt 65 H znajduje się w lokalizacji bajtowej $0210, a wyższy bajt to 87 H znajduje się w lokalizacji bajtowej $0211. Trzeci region składa się z lokalizacji jednobajtowej. Jest to adres $8765 docelowego bajtu (ostateczny bajt będący przedmiotem zainteresowania). Para kolejnych adresów, $0210 i $0211, zawiera wskaźnik $8765, który jest adresem będącym przedmiotem zainteresowania. Po interpretacji obliczeń kwota 8765 dolarów trafia do komputera PC (licznik programu) w celu uzyskania dostępu do bajtu docelowego.
Adresowanie pośrednie strony zerowej
Adresowanie to jest takie samo jak absolutne adresowanie pośrednie, ale wskaźnik musi znajdować się na stronie zerowej. Adres młodszego bajtu obszaru wskaźnika jest taki, jak podano w instrukcji w następujący sposób:
JMP (50 dolarów)
Wyższy bajt wskaźnika znajduje się w lokalizacji bajtowej $51. Adres efektywny (wskazany) nie musi znajdować się na stronie zerowej.
Zatem przy adresowaniu indeksowym wartość w rejestrze indeksowym jest dodawana do adresu bazowego podanego w instrukcji, aby uzyskać adres efektywny. Adresowanie pośrednie wykorzystuje wskaźnik.
4.8 Indeksowane adresowanie pośrednie
Absolutne indeksowane adresowanie pośrednie
Ten tryb adresowania jest używany wyłącznie z instrukcją JMP.
W przypadku absolutnego adresowania pośredniego istnieje wskazana wartość (bajt) z jej własnymi dwoma kolejnymi adresami bajtowymi. Te dwa kolejne adresy tworzą wskaźnik, który ma znajdować się w obszarze wskaźników dwóch kolejnych bajtów w pamięci. W instrukcji w nawiasach wpisywany jest niższy bajt obszaru wskaźnika. Wskaźnik jest adresem wskazanej wartości. W poprzedniej sytuacji adresem wskazanej wartości jest $8765. Wartość 0210 $ (po której następuje 0211 $) to adres, którego zawartość wynosi 8765 $, czyli wskaźnik. W przypadku absolutnego trybu adresowania pośredniego w programie (plik tekstowy) wpisywany jest ($0210), łącznie z nawiasami.
Z drugiej strony, w trybie adresowania pośredniego bezwzględnie indeksowanego, dolny bajt adresu obszaru wskaźnika jest tworzony poprzez dodanie wartości w rejestrze X do wpisanego adresu. Na przykład, jeśli wskaźnik znajduje się w lokalizacji adresu $0210, wpisana instrukcja może wyglądać mniej więcej tak:
JMP (020A,X)
Gdzie rejestr X ma wartość 6 H . 020A H + 6 H = 0210 H . Rejestr Y nie jest używany w tym trybie adresowania.
Adresowanie pośrednie indeksowane z zerową stroną
Ten tryb adresowania wykorzystuje rejestr X, a nie rejestr Y. W tym trybie adresowania nadal znajduje się wskazana wartość i wskaźnik w dwubajtowym obszarze wskaźników adresu. Wskaźnik musi zawierać dwa kolejne bajty na stronie zerowej. Adres wpisywany w instrukcji jest adresem jednobajtowym. Ta wartość jest dodawana do wartości w rejestrze X, a wszelkie przeniesienie jest odrzucane. Wynik wskazuje obszar wskaźnika na stronie 0. Na przykład, jeśli adres zainteresowania (zaznaczony) wynosi 8765 $ i znajduje się w lokalizacjach bajtów 50 $ i 51 $ strony 0, a wartość w rejestrze X wynosi 30 $, wpisana instrukcja wygląda mniej więcej tak:
LDA (20,X USD)
Ponieważ 20 dolarów + 30 dolarów = 50 dolarów.
Pośrednie adresowanie indeksowane
Ten tryb adresowania wykorzystuje rejestr Y, a nie rejestr X. W tym trybie adresowania nadal istnieje wartość punktowa i obszar wskaźnika, ale zawartość obszaru wskaźnika działa inaczej. Na stronie zerowej obszaru wskaźnika muszą znajdować się dwa kolejne bajty. W instrukcji wpisywany jest dolny adres obszaru wskaźnikowego. Ta liczba (para bajtów) zawarta w obszarze wskaźników jest dodawana do wartości w rejestrze Y, aby uzyskać rzeczywisty wskaźnik. Na przykład, niech adres zainteresowania (wskazany) będzie wynosił 8765 $, wartość 6H będzie w rejestrze Y, a liczba (dwa bajty) będzie pod adresem 50 H i 51 H . Te dwa bajty razem wynoszą 875F, ponieważ 875F + 6 USD = 8765 USD. Wpisana instrukcja wygląda mniej więcej tak:
LDA (50 dolarów), Y
4.9 Instrukcje zwiększania, zmniejszania i testowania BIT-ów
Poniższa tabela przedstawia operacje na instrukcjach zwiększania i zmniejszania:
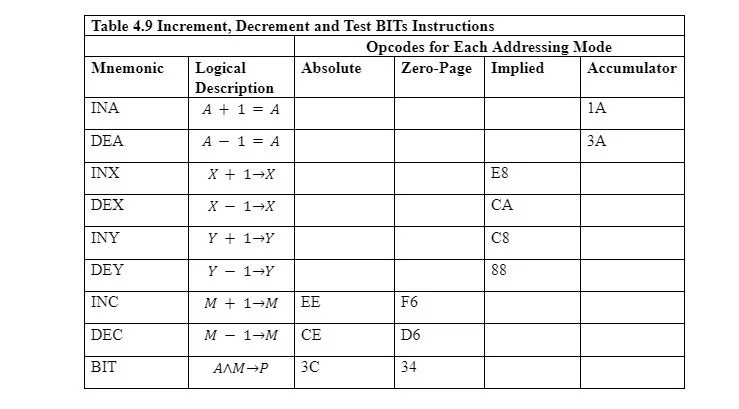
INA i DEA odpowiednio zwiększają i zmniejszają wartość akumulatora. Nazywa się to adresowaniem akumulatorowym. INX, DEX, INY i DEY dotyczą odpowiednio rejestrów X i Y. Nie przyjmują żadnego operandu. Używają więc ukrytego trybu adresowania. Zwiększanie oznacza dodanie 1 do rejestru lub bajtu pamięci. Zmniejszanie oznacza odejmowanie 1 od rejestru lub bajtu pamięci.
INC i DEC odpowiednio zwiększają i zmniejszają bajt pamięci (a nie rejestr). Stosowanie adresowania strony zerowej zamiast adresowania bezwzględnego ma na celu zaoszczędzenie pamięci dla instrukcji. Adresowanie strony zerowej jest o jeden bajt mniejsze niż adresowanie bezwzględne instrukcji w pamięci. Jednakże tryb adresowania strony zerowej wpływa tylko na stronę zerową.
Instrukcja BIT sprawdza bity bajtu w pamięci za pomocą 8 bitów w akumulatorze, ale nie zmienia żadnego z nich. Ustawione są tylko niektóre flagi rejestru stanu procesora „P”. Bity określonej lokalizacji pamięci są logicznie poddawane operacji AND z bitami akumulatora. Następnie ustawiane są następujące bity stanu:
- N, który jest bitem 7 i ostatnim bitem (po lewej stronie) rejestru stanu, otrzymuje bit 7 lokalizacji pamięci przed operacją AND.
- V, który jest bitem 6 rejestru stanu, otrzymuje bit 6 lokalizacji pamięci przed operacją AND.
- Flaga Z rejestru stanu jest ustawiona (1), jeśli wynik AND wynosi zero (00000000 2 ). W przeciwnym razie jest kasowany (ustawiony na 0).
4.10 Porównaj instrukcje
Mnemoniki instrukcji porównania dla 6502 µP to CMP, CPX i CPY. Po każdym porównaniu wpływa to na flagi N, Z i C rejestru stanu procesora „P”. Flaga N jest ustawiana (1), gdy wynik jest liczbą ujemną. Flaga Z jest ustawiana (1), gdy wynikiem jest zero (000000002). Flaga C jest ustawiana (ustawiona na 1), gdy następuje przeniesienie z ósmego do dziewiątego bitu. Poniższa tabela zawiera szczegółową ilustrację
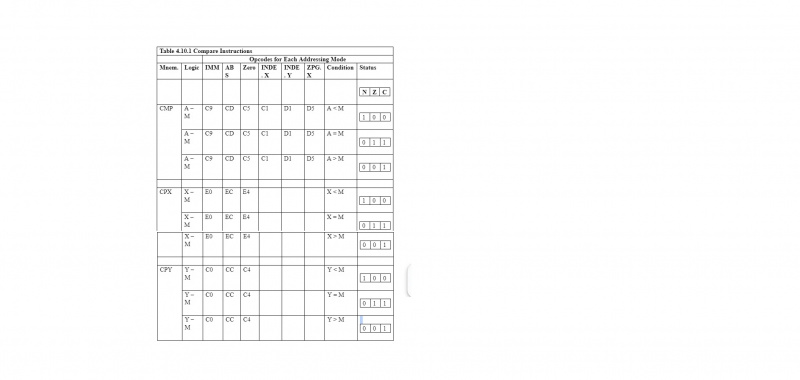
Oznacza „większy niż”. Dzięki temu tabela porównawcza powinna być oczywista.
4.11 Instrukcje skoku i rozgałęzienia
Poniższa tabela podsumowuje instrukcje dotyczące skoków i rozgałęzień:
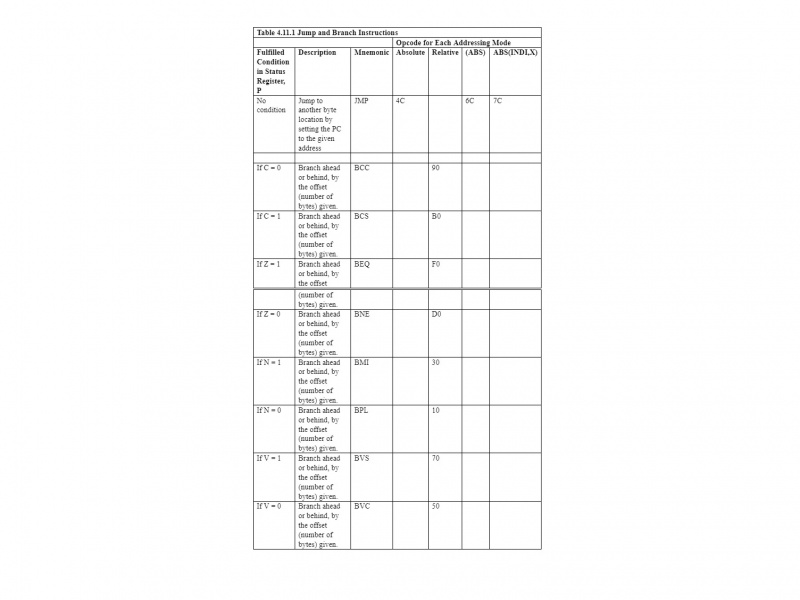
Instrukcja JMP wykorzystuje adresowanie bezwzględne i pośrednie. Pozostałe instrukcje w tabeli to instrukcje rozgałęzione. Używają tylko adresowania względnego w przypadku 6502 µP. Dzięki temu tabela staje się oczywista, jeśli czyta się ją od lewej do prawej i od góry do dołu.
Należy pamiętać, że rozgałęzienia można zastosować tylko do adresów w zakresie od -128 do +127 bajtów od podanego adresu. To jest adresowanie względne. Zarówno w przypadku instrukcji JMP, jak i instrukcji gałęzi, ma to bezpośredni wpływ na licznik programów (PC). 6502 µP nie pozwala rozgałęzieniom na adres absolutny, chociaż skok może wykonać adresowanie absolutne. Instrukcja JMP nie jest instrukcją rozgałęzienia.
Notatka: Adresowanie względne jest używane tylko z instrukcjami rozgałęzień.
4.12 Obszar stosu
Podprogram działa jak jeden z poprzednich krótkich programów, służący do dodawania lub odejmowania dwóch liczb. Obszar stosu w pamięci zaczyna się od 0100 $ do 01FF włącznie. Obszar ten nazywany jest po prostu stosem. Kiedy mikroprocesor wykonuje skok do instrukcji podprogramu (JSR – patrz poniższe omówienie), musi wiedzieć, gdzie wrócić po zakończeniu. Układ 6502 µP przechowuje tę informację (adres zwrotny) w małej pamięci od 0100 $ do 01FF (obszar stosu) i wykorzystuje zawartość rejestru wskaźnika stosu, czyli „S” w mikroprocesorze, jako wskaźnik (9 bitów) do ostatniego zwróconego adresu który jest przechowywany na stronie 1 (0100 $ do 01FF) pamięci. Stos rośnie od $ 01FF i umożliwia zagnieżdżanie podprogramów aż do 128 poziomów.
Innym zastosowaniem wskaźnika stosu jest obsługa przerwań. Model 6502 µP ma piny oznaczone jako IRQ i NMI. Możliwe jest, że do tych styków zostaną przyłożone niewielkie sygnały elektryczne, które spowodują, że procesor 6502 µP przestanie wykonywać jeden program i zacznie wykonywać inny. W takim przypadku pierwszy program zostaje przerwany. Podobnie jak podprogramy, segmenty kodu przerwania mogą być zagnieżdżane. Przetwarzanie przerwań zostało omówione w następnym rozdziale.
Notatka : Wskaźnik stosu ma 8 bitów dla adresu dolnego bajtu w adresowaniu lokalizacji od 0100 $ do 01FF. Wyższy bajt 00000001 2 zakłada się.
Poniższa tabela zawiera instrukcje wiążące wskaźnik stosu „S” z rejestrami A, X, Y i P z obszarem stosu w pamięci:
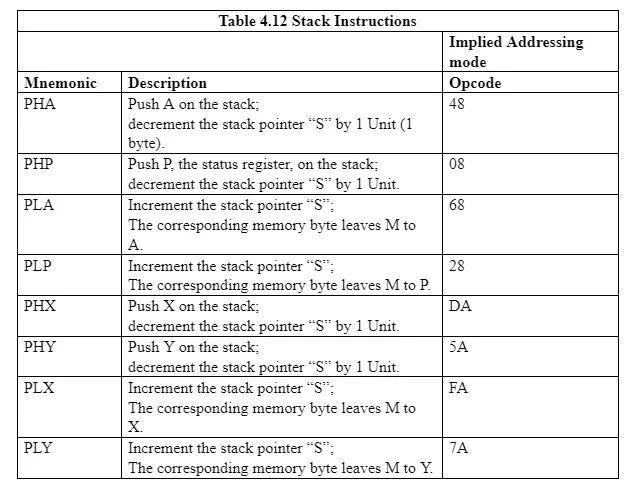
4.13 Wywołanie i powrót podprogramu
Podprogram to zestaw instrukcji, które osiągają określony cel. Poprzedni program dodawania lub odejmowania jest bardzo krótkim podprogramem. Podprogramy są czasami nazywane po prostu procedurami. Instrukcja wywołania podprogramu wygląda następująco:
JSR: Skok do podprogramu
Instrukcja powrotu z podprogramu to:
RTS: Powrót z podprogramu
Mikroprocesor ma tendencję do ciągłego wykonywania instrukcji znajdujących się w pamięci, jedna po drugiej. Załóżmy, że mikroprocesor aktualnie wykonuje segment kodu i napotyka instrukcję skoku (JMP), aby przejść i wykonać segment kodu, który jest zakodowany i który mógł już zostać wykonany. Wykonuje ten segment kodu z tyłu i kontynuuje wykonywanie wszystkich segmentów kodu (instrukcji) po segmencie kodu z tyłu, aż do ponownego wykonania bieżącego segmentu kodu i kontynuowania poniżej. JMP nie wypycha kolejnej instrukcji na stos.
W przeciwieństwie do JMP, JSR wypycha adres następnej instrukcji po sobie z komputera PC (licznik programu) na stos. Pozycja stosu tego adresu jest umieszczana we wskaźniku stosu „S”. Kiedy w podprogramie napotkana zostanie (wykonana) instrukcja RTS, adres wypychany na stos ściąga stos, a program wznawia działanie od tego ściągniętego adresu, który jest adresem następnej instrukcji tuż przed wywołaniem podprogramu. Ostatni adres usunięty ze stosu jest wysyłany do licznika programu. Poniższa tabela zawiera szczegóły techniczne instrukcji JSR i RTS:

Zobacz poniższą ilustrację dotyczącą zastosowań JSR i RTS:
4.14 Przykład pętli odliczania
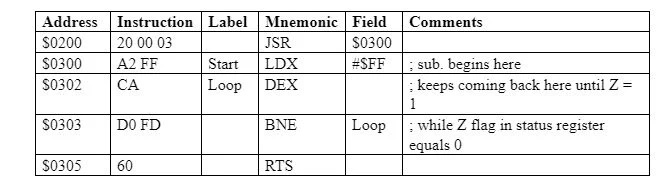
Poniższy podprogram odlicza od $FF do 00 $ (w sumie 256 10 liczy się):
uruchom LDX #$FF ; załaduj X za pomocą $FF = 255
pętla DEX ; X = X – 1
pętla BNE; jeśli X nie jest zerem, przejdź do pętli
RTS; powrót
Każda linia ma komentarz. Komentarze nigdy nie trafiają do pamięci w celu wykonania. Asembler (tłumacz), który konwertuje program do postaci znajdującej się w pamięci w celu wykonania (uruchomienia), zawsze usuwa komentarze. Komentarz zaczyna się od „;” . „Początek” i „pętla” w tym programie nazywane są etykietami. Etykieta wskazuje (nazwę) adres instrukcji. Jeśli instrukcja jest instrukcją jednobajtową (adresowanie domniemane), etykieta jest adresem tej instrukcji. Jeśli instrukcja jest instrukcją wielobajtową, etykieta identyfikuje pierwszy bajt instrukcji wielobajtowej. Pierwsza instrukcja tego programu składa się z dwóch bajtów. Zakładając, że zaczyna się od adresu $0300, adres $0300 można zastąpić w programie słowem „start”. Druga instrukcja (DEX) jest instrukcją jednobajtową i powinna znajdować się pod adresem $0302. Oznacza to, że adres $0302 można zastąpić „pętlą” w dalszej części programu, co faktycznie ma miejsce w „pętli BNE”.
„Pętla BNE” oznacza odgałęzienie do podanego adresu, gdy flaga Z rejestru statusowego wynosi 0. Gdy wartość w rejestrze A lub X lub Y wynosi 00000000 2 , ze względu na ostatnią operację flaga Z wynosi 1 (ustawiona). Zatem, chociaż jest to 0 (a nie 1), druga i trzecia instrukcja programu są powtarzane w tej kolejności. W każdej powtarzanej sekwencji wartość (liczba całkowita) w rejestrze X jest zmniejszana o 1. DEX oznacza X = X – 1. Gdy wartość w rejestrze X wynosi $00 = 00000000 2 , Z staje się 1. W tym momencie nie ma już powtórzeń tych dwóch instrukcji. Ostatnia instrukcja RTS w programie, będąca instrukcją jednobajtową (adresowanie domniemane), powraca z podprogramu. Efektem tej instrukcji jest umieszczenie adresu licznika programu na stosie dla kodu, który ma zostać wykonany przed wywołaniem podprogramu i powrót do licznika programu (PC). Adres ten jest adresem instrukcji, która ma zostać wykonana przed wywołaniem podprogramu.
Notatka: Podczas pisania programu w języku asemblera dla 6502 µP tylko etykieta musi zaczynać się na początku linii; każdy inny kod linii musi zostać przesunięty przynajmniej o jedną spację w prawo.
Wywołanie podprogramu
Pomijając przestrzeń pamięci zajmowaną przez poprzednie etykiety, program zajmuje 6 bajtów kolejnych lokalizacji w pamięci (RAM) od 0300 $ do 0305 $. W tym przypadku program jest następujący:
LDX #$FF ; załaduj X za pomocą $FF = 255
DEX ; X = X – 1
BNE $0302; jeśli X nie jest zerem, przejdź do pętli
RTS ; powrót
Począwszy od adresu $0200 w pamięci może nastąpić wywołanie podprogramu. Instrukcja wywołania to:
początek JSR; początek to adres $0300, tj. JSR $0300
Podprogram i jego wywołanie poprawnie zapisane w pliku edytora tekstu to:
uruchom LDX #$FF; załaduj X za pomocą $FF = 255
pętla DEX ; X = X – 1
pętla BNE; jeśli X nie jest zerem, przejdź do pętli
RTS; powrót
Start JSR: skok do procedury rozpoczynającej się od 0300 $
Teraz w jednym długim programie może znajdować się wiele podprogramów. Wszystkie nie mogą mieć nazwy „start”. Powinny mieć różne nazwy. W rzeczywistości żaden z nich nie może mieć nazwy „start”. „Start” jest tu użyte ze względów dydaktycznych.
4.15 Tłumaczenie programu
Tłumaczenie programu lub jego asemblacja oznacza to samo. Rozważmy następujący program:
uruchom LDX #$FF: załaduj X za pomocą $FF = 255
pętla DEX : X = X – 1
Pętla BNE: jeśli X nie jest zerem, to przejdź do pętli
RTS: powrót
Start JSR: skok do procedury rozpoczynającej się od 0300 $
To jest program, który został wcześniej napisany. Składa się z podprogramu, startu i wywołania podprogramu. Program odlicza od 255 10 do 0 10 . Program rozpoczyna się od adresu początkowego użytkownika wynoszącego 0200 $ (RAM). Program wpisuje się w edytorze tekstu i zapisuje na dysku. Ma nazwę taką jak „sample.asm”, gdzie „sample” jest nazwą wybraną przez programistę, ale rozszerzenie „.asm” dla języka asemblera musi być powiązane z nazwą pliku.
Złożony program jest tworzony przez inny program, zwany asemblerem. Asembler dostarczany jest przez producenta 6502 µP lub przez stronę trzecią. Asembler odtwarza program w taki sposób, że znajduje się on w pamięci (RAM) w trakcie jego wykonywania (uruchamiania).
Załóżmy, że instrukcja JSR zaczyna się od adresu 0200 $, a podprogram zaczyna się od adresu 0300 $. Asembler usuwa wszystkie komentarze i białe spacje. Komentarze i białe spacje marnują pamięć, której zawsze jest mało. Przykładem białych znaków może być pusta linia pomiędzy poprzednim segmentem kodu podprogramu a wywołaniem podprogramu. Złożony plik jest nadal zapisywany na dysku i nosi nazwę „sample.exe”. „Próbka” to nazwa wybrana przez programistę, ale powinno tam znajdować się rozszerzenie „.exe” wskazujące, że jest to plik wykonywalny.
Zmontowany program można udokumentować w następujący sposób:
Mówi się, że stworzenie takiego dokumentu jest składaniem ręcznym. Należy pamiętać, że komentarze w tym dokumencie nie pojawiają się w pamięci (do wykonania). Kolumna adresowa w tabeli wskazuje początkowe adresy instrukcji w pamięci. Należy zauważyć, że „JSR start”, czyli „JSR $0300”, który powinien być zakodowany jako „20 03 00”, jest w rzeczywistości kodowany jako „20 00 03”, przy czym niższy bajt adresu pamięci zajmuje niższy bajt w pamięci, a adres wyższego bajtu pamięci zabierający wyższy bajt w pamięci – mała endianność. Kod operacji dla JSR to 20 16 .
Należy zauważyć, że przesunięcie względem instrukcji rozgałęzienia, takiej jak BNE, jest liczbą uzupełnioną do dwójki z zakresu 128 10 do + 127 10 . Zatem „pętla BNE” oznacza „BNE -1 10 ”, co w rzeczywistości oznacza „D0 FF” w postaci kodu FF 16 wynosi -1 w uzupełnieniu do dwóch, które jest zapisywane jako = 11111111 w podstawie dwa. Program asemblera zastępuje etykiety i pola rzeczywistymi liczbami szesnastkowymi (liczby szesnastkowe to liczby binarne pogrupowane w czterech bitach). Uwzględnione są rzeczywiste adresy, od których zaczyna się każda instrukcja.
Notatka: Instrukcja „JSR start” zostaje zastąpiona krótszymi instrukcjami, które wysyłają aktualną zawartość (starszy i młodszy bajt) licznika programu na stos ze wskaźnikiem stosu, który jest dwukrotnie zmniejszany (raz dla starszego bajtu i raz dla młodszego bajtu) i następnie ponownie ładuje komputer z adresem $0300. Wskaźnik stosu wskazuje teraz na $00FD, zakładając, że został zainicjowany na $01FF.
Ponadto instrukcja RTS została zastąpiona szeregiem krótszych instrukcji, które dwukrotnie zwiększają wskaźnik stosu „S” (raz dla młodszego bajtu i raz dla starszego bajtu) i pobierają odpowiednie dwa bajty adresu ze wskaźnika stosu do komputera PC w celu następna instrukcja.
Notatka: Tekst etykiety nie powinien mieć więcej niż 8 znaków.
„Pętla BNE” wykorzystuje adresowanie względne. Oznacza to dodanie -3 10 do następnego licznika programu o zawartości $0305. Bajty „pętli BNE” to „D0 FD”, gdzie FD jest uzupełnieniem dwójki -3 10 .
Uwaga: W tym rozdziale nie przedstawiono wszystkich instrukcji dotyczących 6502 µP. Wszystkie instrukcje i ich szczegóły można znaleźć w dokumencie zatytułowanym „Rodzina 8-bitowych mikroprocesorów SY6500”. Dla tego dokumentu istnieje plik PDF o nazwie „6502.pdf”, który jest swobodnie dostępny w Internecie. 6502 µP opisane w tym dokumencie to 65C02.
4.16 Przerwania
Sygnały dowolnego urządzenia podłączonego do zewnętrznych (pionowych powierzchni) portów Commodore 64 muszą przejść przez obwody (IC) CIA 1 lub CIA 2, zanim dotrą do mikroprocesora 6502. Sygnały z magistrali danych 6502 µP muszą przejść przez układ CIA 1 lub CIA 2, zanim dotrą do jakiegokolwiek urządzenia zewnętrznego. CIA oznacza złożony adapter interfejsu. Na rys. 4.1 „Schemat blokowy płyty głównej Commodore_64” blokowe urządzenia wejścia/wyjścia reprezentują CIA 1 i CIA 2. Gdy program jest uruchomiony, można go przerwać, aby wykonać inny fragment kodu przed kontynuowaniem. Występują przerwy w sprzęcie i w oprogramowaniu. W przypadku zakłóceń sprzętowych, w 6502 µP znajdują się dwa piny sygnału wejściowego. Nazwy tych pinów to Przerwanie I NMI . To nie są linie danych µP. Linie danych dla µP to D7, D6, D5, D4, D3, D2, D1 i D0; z D0 dla najmniej znaczącego bitu i D7 dla najbardziej znaczącego bitu.
Przerwanie oznacza „aktywne” żądanie przerwania, niskie. Ta linia wejściowa do µP jest zwykle wysoka, około 5 woltów. Kiedy spadnie do około 0 V, jest to żądanie przerwania, które sygnalizuje µP. Gdy tylko żądanie zostanie spełnione, linia wraca na wysoki poziom. Przyznanie żądania przerwania oznacza, że µP przechodzi do kodu (podprogramu), który obsługuje przerwanie.
NMI oznacza „aktywne” przerwanie niemaskowalne. Chociaż kod dla Przerwanie jest wykonywana NMI może zejść nisko. W tym przypadku, NMI jest obsługiwany (wykonywany jest jego własny kod). Następnie kod dla Przerwanie trwa. Po kodzie dla Przerwanie kończy się, główny kod programu jest kontynuowany. To jest, NMI przerywa Przerwanie treser. Sygnał dla NMI może być nadal przekazane µP nawet wtedy, gdy µP jest bezczynne i nie obsługuje niczego lub nie uruchamia głównego programu.
Notatka: W rzeczywistości jest to przejście od wysokiego do niskiego poziomu NMI , to jest NMI sygnał – o tym później. Przerwanie zwykle pochodzi z CIA 1 i NMI zwykle pochodzi z CIA 2. NMI , co oznacza przerwanie niemaskowalne, można uznać za przerwanie nie do zatrzymania.
Obsługa przerwań
Czy żądanie pochodzi z Przerwanie Lub NMI , bieżąca instrukcja musi zostać zakończona. Model 6502 ma tylko rejestry A, X i Y. Kiedy podprogram działa, może używać tych trzech rejestrów łącznie. Procedura obsługi przerwań jest nadal podprogramem, chociaż nie jest postrzegana jako taka. Po zakończeniu bieżącej instrukcji zawartość rejestrów A, X i Y dla 65C02 µP jest zapisywana na stosie. Adres następnej instrukcji Licznika Programów jest również wysyłany na stos. Następnie µP przechodzi do kodu przerwania. Następnie zawartość rejestrów A, X i Y jest następnie przywracana ze stosu w odwrotnej kolejności, do której zostały wysłane.
Przykładowe kodowanie przerwania
Dla uproszczenia załóżmy, że procedura dla µP Przerwanie przerwanie polega po prostu na dodaniu liczb $01 i $02 i zapisaniu wyniku $03 pod adresem pamięci $0400. Kod to:
ISR PHA
PHX
FI
;
LDA #01 USD
ADC nr 02
KOSZTUJĄ 0400 dolarów
;
ZAGIĘCIE
PLX
PLA
RTI
ISR jest etykietą identyfikującą adres pamięci, w którym znajduje się instrukcja PHA. ISR oznacza procedurę obsługi przerwań. PHA, PHX i PHY wysyłają zawartość rejestrów A, X i Y na stos z nadzieją, że będą one potrzebne dowolnemu kodowi (programowi) działającemu tuż przed przerwaniem. Następne trzy instrukcje stanowią rdzeń procedury obsługi przerwań. Instrukcje PLY, PLX i PLA muszą być w tej kolejności i zwracają zawartość rejestrów Y, X i A. Ostatnia instrukcja, czyli RTI, (bez argumentu) zwraca kontynuację wykonywania dowolnego kodu (programu), który był wykonywany przed przerwaniem. RTI pobiera adres następnej wykonywanej instrukcji kodu ze stosu z powrotem do licznika programu. RTI oznacza powrót z przerwania. W ten sposób kończy się obsługa przerwań (podprogram).
Przerwanie oprogramowania
Głównym sposobem uzyskania przerwania programowego dla 6502 µP jest użycie instrukcji adresu implikowanego BRK. Załóżmy, że program główny jest uruchomiony i napotkał instrukcję BRK. Od tego momentu adres następnej instrukcji w komputerze powinien zostać wysłany na stos po zakończeniu bieżącej instrukcji. Podprogram obsługujący instrukcję oprogramowania powinien nazywać się „next”. Ten podprogram przerwania powinien wypchnąć zawartość rejestrów A, X i Y na stos. Po wykonaniu rdzenia podprogramu zawartość rejestrów A, X i Y powinna zostać ściągnięta ze stosu do ich rejestrów przez podprogram kończący. Ostatnią instrukcją w procedurze jest RTI. Zawartość komputera PC jest również automatycznie pobierana ze stosu na komputer PC dzięki funkcji RTI.
Porównanie i porównanie podprogramów i procedur obsługi przerwań
Poniższa tabela porównuje i zestawia podprogramy i procedury obsługi przerwań:

4.17 Podsumowanie głównych trybów adresowania 6502
Każda instrukcja dla 6502 składa się z jednego bajtu, po którym następuje zero lub więcej operandów.
Tryb adresowania natychmiastowego
W trybie adresowania bezpośredniego po operandze znajduje się wartość, a nie adres pamięci. Wartość musi być poprzedzona #. Jeśli wartość jest w formacie szesnastkowym, po „#” musi nastąpić „$”. Instrukcje bezpośredniego adresowania dla 65C02 to: ADC, AND, BIT, CMP, CPX, CPY, EOR, LDA, LDX, LDY, ORA, SBC. Czytelnik powinien zapoznać się z dokumentacją 65C02 µP, aby dowiedzieć się, jak korzystać z podanych tutaj instrukcji, które nie są wyjaśnione w tym rozdziale. Przykładowa instrukcja to:
LDA #77 dolarów
Tryb adresowania bezwzględnego
W trybie adresowania absolutnego jest jeden operand. Ten operand jest adresem wartości w pamięci (zwykle w formacie szesnastkowym lub etykiecie). Jest ich 64 tys 10 = 65536 10 adresy pamięci dla 6502 µP. Zazwyczaj wartość jednobajtowa znajduje się pod jednym z tych adresów. Instrukcje adresowania bezwzględnego dla 65C02 to: ADC, AND, ASL, BIT, CMP, CPX, CPY, DEC, EOR, INC, JMP, JSR, LDA, LDX, LDY, LSR, ORA, ROL, ROR, SBC, STA , STX, STY, STZ, TRB, TSB. Czytelnik powinien zapoznać się z dokumentacją 65C02 µP, aby dowiedzieć się, jak korzystać z instrukcji tutaj wymienionych, a także pozostałych trybów adresowania, które nie są wyjaśnione w tym rozdziale. Przykładowa instrukcja to:
SĄ 1234 USD
Domniemany tryb adresowania
W trybie adresowania domniemanego nie ma operandu. Instrukcja sugeruje dowolny rejestr µP. Domniemane instrukcje adresowania dla 65C02 to: BRK, CLC, CLD, CLI, CLV, DEX, DEY, INX, INY, NOP, PHA, PHP, PHX, PHY, PLA, PLP, PLX, PLY, RTI, RTS, SEC , SED, SEI, TAX, TAY, TSX, TXA, TXS, TYA. Przykładowa instrukcja to:
DEX: Zmniejszenie rejestru X o jedną jednostkę.
Tryb adresowania względnego
Tryb adresowania względnego dotyczy tylko instrukcji rozgałęzień. W trybie adresowania względnego istnieje tylko jeden operand. Jest to wartość od -128 10 do +127 10 . Wartość ta nazywana jest przesunięciem. Na podstawie znaku wartość ta jest dodawana lub odejmowana od następnej instrukcji Licznika Programu, w wyniku czego otrzymuje się adres zamierzonej następnej instrukcji. Instrukcje trybu adresu względnego to: BCC, BCS, BEQ, BMI, BNE, BPL, BRA, BVC, BVS. Przykładowe instrukcje to:
BNE $7F : (oddział jeśli Z = 0 w rejestrze statusowym, P)
Który dodaje 127 do bieżącego licznika programu (adresu do wykonania) i rozpoczyna wykonywanie instrukcji pod tym adresem. Podobnie:
BEQ $F9 : (gałąź jeśli Z = : w rejestrze statusowym, P)
Co dodaje -7 do bieżącego licznika programu i rozpoczyna wykonywanie pod nowym adresem licznika programu. Operand jest liczbą uzupełniającą do dwójki.
Absolutne adresowanie indeksowane
W przypadku adresowania indeksowego absolutnego zawartość rejestru X lub Y jest dodawana do podanego adresu bezwzględnego (w dowolnym miejscu od 0000 $ do $FFFF, tj. od 0 10 do 65536 10 ), aby mieć prawdziwy adres. Ten podany adres bezwzględny nazywany jest adresem bazowym. Jeśli używany jest rejestr X, instrukcja montażu wygląda mniej więcej tak:
LDA $C453,X
Jeśli używany jest rejestr Y, wygląda to mniej więcej tak:
LDA $C453,Y
Wartość rejestru X lub Y nazywana jest wartością licznika lub indeksu i może wynosić od 00 $ (0 10 ) do $FF (250 10 ). Nie nazywa się to offsetem.
Instrukcje adresowania indeksu bezwzględnego to: ADC, AND, ASL (tylko X), BIT (z akumulatorem i pamięcią, tylko X), CMP, DEC (tylko pamięć i X), EOR, INC (tylko pamięć i X), LDA , LDX, LDY, LSR (tylko X), ORA, ROL (tylko X), ROR (tylko X), SBC, STA, STZ (tylko X).
Absolutne adresowanie pośrednie
Używa się tego tylko z instrukcją skoku. Dzięki temu podany adres bezwzględny ma adres wskaźnika. Adres wskaźnika składa się z dwóch bajtów. Dwubajtowy wskaźnik wskazuje (jest adresem) docelowej wartości bajtu w pamięci. Zatem instrukcja języka asemblera wygląda następująco:
JMP (3456 USD)
W nawiasach, $13 znajduje się pod adresem 3456 $, podczas gdy $EB znajduje się pod adresem 3457 $ (= 3456 $ + 1). Następnie adresem docelowym jest $13EB, a $13EB jest wskaźnikiem. W instrukcji w nawiasach podano bezwzględną wartość 3456 $, gdzie 34 to dolny bajt, a 56 to wyższy bajt.
4.18 Tworzenie łańcucha za pomocą języka asemblera 6502 µP
Jak pokazano w kolejnym rozdziale, po utworzeniu pliku w pamięci, można go zapisać na dysku. Plikowi należy nadać nazwę. Nazwa jest przykładem ciągu znaków. Istnieje wiele innych przykładów ciągów w programowaniu.
Istnieją dwa główne sposoby tworzenia ciągu kodów ASCII. W obu przypadkach wszystkie kody ASCII (znaki) zajmują kolejne bajty w pamięci. W pewnym sensie ta sekwencja bajtów jest poprzedzona bajtem będącym liczbą całkowitą, która jest długością (liczbą znaków) w sekwencji (stringu). W przeciwnym razie po sekwencji znaków (natychmiast po niej) następuje bajt Null, który wynosi 00 16 , czyli 00 dolarów. W ten inny sposób nie jest wskazywana długość ciągu znaków (liczba znaków). Znak Null nie jest używany w pierwszy sposób.
Weźmy na przykład pod uwagę powiedzenie „Kocham cię!” ciąg znaków bez cudzysłowów. Długość tutaj wynosi 11; spacja liczy się jako jeden bajt (znak) ASCII. Załóżmy, że ciąg znaków musi zostać umieszczony w pamięci, a pierwszy znak znajduje się pod adresem $0300.
Poniższa tabela przedstawia ustawienie pamięci ciągów, gdy pierwszym bajtem jest 11 10 = 0B 16 :
Poniższa tabela pokazuje ustawienie pamięci ciągu, gdy pierwszy bajt to „I”, a ostatni bajt to Null (00 $):
Aby rozpocząć tworzenie łańcucha, można zastosować następującą instrukcję:
KOSZTUJĄ 0300 USD
Załóżmy, że pierwszy bajt znajduje się w akumulatorze, który ma zostać wysłany na adres lokalizacji $0300. Ta instrukcja jest prawdziwa w obu przypadkach (oba typy ciągów).
Po umieszczeniu wszystkich znaków w komórkach pamięci, jeden po drugim, ciąg można odczytać za pomocą pętli. W pierwszym przypadku po długości odczytywana jest liczba znaków. W drugim przypadku znaki są odczytywane od „I” aż do napotkania znaku Null o wartości „Null”.
4.19 Tworzenie tablicy za pomocą języka asemblera 6502 µP
Tablica jednobajtowych liczb całkowitych składa się z kolejnych lokalizacji bajtów pamięci zawierających liczby całkowite. Następnie znajduje się wskaźnik wskazujący lokalizację pierwszej liczby całkowitej. Zatem tablica liczb całkowitych składa się z dwóch części: wskaźnika i serii lokalizacji.
W przypadku tablicy ciągów każdy ciąg może znajdować się w innym miejscu pamięci. Następnie istnieją kolejne lokalizacje pamięci ze wskaźnikami, gdzie każdy wskaźnik wskazuje pierwszą lokalizację każdego ciągu. Wskaźnik w tym przypadku składa się z dwóch bajtów. Jeśli ciąg zaczyna się od jego długości, odpowiedni wskaźnik wskazuje położenie tej długości. Jeśli ciąg nie zaczyna się od swojej długości, ale kończy się znakiem null, odpowiedni wskaźnik wskazuje lokalizację pierwszego znaku ciągu. Istnieje również wskaźnik wskazujący adres młodszego bajtu pierwszego wskaźnika kolejnych wskaźników. Zatem tablica ciągów składa się z trzech części: ciągów znajdujących się w różnych miejscach pamięci, odpowiadających im kolejnych wskaźników oraz wskaźnika do pierwszego wskaźnika kolejnych wskaźników.
4.20 Problemy
Czytelnikowi zaleca się rozwiązanie wszystkich problemów zawartych w danym rozdziale przed przejściem do następnego rozdziału.
- Napisz program w języku asemblera, który zaczyna się od $0200 dla 6502 µP i dodaje liczby bez znaku z 2A94 H (dodaj) do 2ABF H (dodaj). Niech wejścia i wyjścia będą w pamięci. Przygotuj także ręcznie zmontowany dokument programu.
- Napisz program w języku asemblera, który zaczyna się od $0200 dla 6502 µP i odejmuje liczby bez znaku z 1569 H (odejmij) od 2ABF H (odjemna). Niech wejścia i wyjścia będą w pamięci. Przygotuj także ręcznie zmontowany dokument programu.
- Napisz program w języku asemblera dla układu 6502 µP, który będzie zliczał od 00 do 09 dolarów za pomocą pętli. Program powinien zaczynać się od kwoty 0200 USD. Przygotuj także ręcznie zmontowany dokument programu.
- Napisz program w języku asemblera, który zaczyna się od $0200 dla 6502 µP. Program posiada dwa podprogramy. Pierwszy podprogram dodaje liczby bez znaku 0203 H (dodaj) i 0102H (dodaj). Drugi podprogram dodaje sumę z pierwszego podprogramu, czyli 0305H, do 0006 H (dodaj). Wynik końcowy zapisywany jest w pamięci. Wywołaj pierwszy podprogram, który jest FSTSUB i drugi podprogram, który jest SECSUB. Niech wejścia i wyjścia będą w pamięci. Przygotuj także ręcznie zmontowany dokument programowy dla całego programu.
- Biorąc pod uwagę, że Przerwanie handler dodaje 02 USD do 01 USD w akumulatorze jako obsługa rdzenia podczas NMI jest wydawane i podstawowa obsługa NMI dodaje 05 $ do 04 $ w akumulatorze, napisz język asemblera dla obu procedur obsługi, łącznie z ich wywołaniami. Wezwanie do Przerwanie handler powinien znajdować się pod adresem $0200. The Przerwanie handler powinien zaczynać się od adresu $0300. The NMI handler powinien zaczynać się od adresu $0400. Wynik Przerwanie handler należy umieścić pod adresem $0500, a wynik operacji NMI handler należy umieścić pod adresem $0501.
- Krótko wyjaśnij, w jaki sposób instrukcja BRK jest używana do generowania przerwania programowego w komputerze 65C02.
- Utwórz tabelę porównującą i kontrastującą normalny podprogram z procedurą obsługi przerwania.
- Krótko wyjaśnij główne tryby adresowania 65C02 µP na podstawie przykładów instrukcji w języku asemblera.
- a) Napisz program w języku maszynowym 6502, w którym będzie umieszczane słowo „Kocham cię!” ciąg kodów ASCII w pamięci, zaczynając od adresu $0300 wraz z długością ciągu. Program powinien zaczynać się od adresu $0200. Uzyskaj każdy znak z akumulatora jeden po drugim, zakładając, że są tam wysyłane przez jakiś podprogram. Należy także złożyć program ręcznie. (Jeśli potrzebujesz znać kody ASCII dla „Kocham cię!”. Oto one: „I”:49 16 , spacja: 20 16 , „l”: 6C 16 , „o”:6F 16 , „w”: 76 16 , „e”:65, „y”:79 16 , „w”: 75 16 i „!”:21 16 (Uwaga: każdy kod zajmuje 1 bajt).
b) Napisz program w języku maszynowym 6502, w którym będzie umieszczane słowo „Kocham cię!” ciąg kodów ASCII w pamięci, zaczynający się od adresu $0300 bez długości ciągu, ale kończący się na 00 16 . Program powinien zaczynać się od adresu $0200. Uzyskaj każdy znak z akumulatora, zakładając, że są tam wysyłane jeden po drugim przez jakiś podprogram. Należy także złożyć program ręcznie.