Co to jest EndpointSlice w Kubernetes?
EndpointSlice w Kubernetes to narzędzie do śledzenia punktów końcowych sieci. Umożliwia monitorowanie punktów końcowych sieci w klastrze Kubernetes. Mówiąc prościej, jest to obiekt, który pobiera adresy IP z każdego przypisanego do niego poda. Usługa Kubernetes odwołuje się do tego obiektu, aby uzyskać zapis wewnętrznych adresów IP poda na potrzeby komunikacji. Co więcej, te punkty końcowe są używane przez strąki, aby uzyskać dostęp do usługi.
W obszarze Kubernetes te punkty końcowe działają jako warstwa abstrakcji, która pomaga usłudze Kubernetes upewnić się, że istnieje dystrybucja ruchu do podów w klastrze. Jednak gdy wzrasta obciążenie ruchu, pojawia się problem ze skalowaniem ruchu. Dzieje się tak, ponieważ pojedynczy punkt końcowy zawiera wszystkie punkty końcowe sieci dla każdej usługi. A kiedy te źródła urosną do niedopuszczalnych rozmiarów, negatywnie wpłynie to na wydajność Kubernetes. Innymi słowy, gdy liczba punktów końcowych sieci ogromnie rośnie, negatywnie wpływa to na zdolność Kubernetes do skalowania wdrożenia. Zrozummy to za pomocą następującego obrazu graficznego:
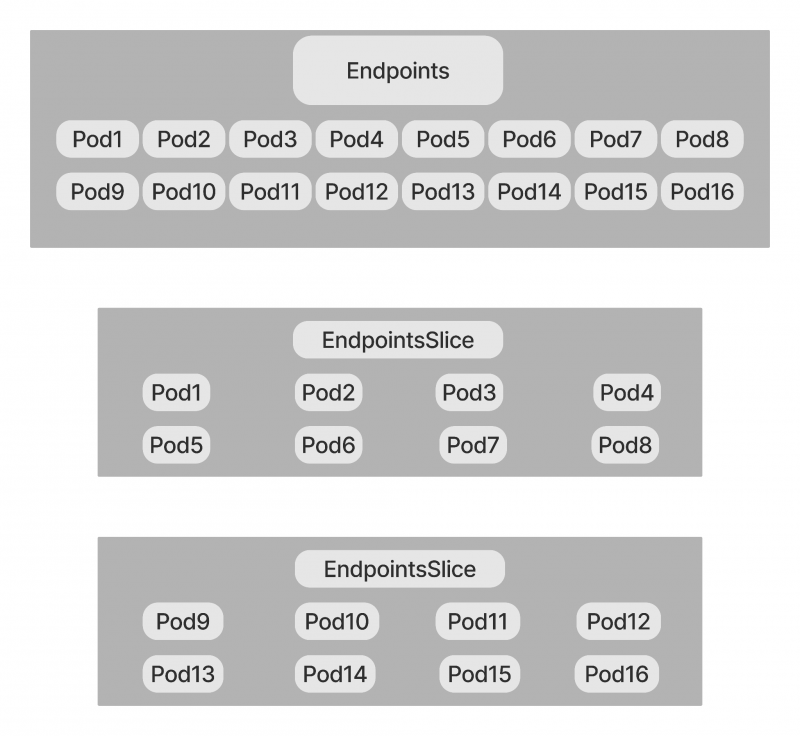
Tutaj widać, że punkt końcowy zawiera wszystkie pody w klastrze, a elementy EndpointSlice są rozszerzalną i skalowalną alternatywą dla istniejącego punktu końcowego. Istnieje tylko jeden zasób punktu końcowego dla całej usługi, ale istnieje więcej niż jeden element EndpointSlice dla tej samej usługi. EndpointSlices pomagają skalować zasoby sieciowe w ten sposób. Aby zrozumieć, jak istotna jest ta kwestia skalowalności, weźmy przykład.
Na przykład usługa Kubernetes ma około 9 000 podów, które w jakiś sposób trafiają do 2 MB zasobów punktu końcowego. Pojedynczy punkt końcowy ma wszystkie te zasoby punktów końcowych usług. Jeśli jakikolwiek punkt końcowy sieci ulegnie zmianie w punkcie końcowym, cały zasób punktu końcowego musi zostać rozdzielony między każdy węzeł w klastrze. Jeśli chodzi o radzenie sobie z klastrem mającym 3000 węzłów, staje się to ogromnym problemem, ponieważ do każdego węzła trzeba wysłać ogromną liczbę aktualizacji. W związku z tym, gdy skalujesz więcej w jednym punkcie końcowym, tym trudniejsze staje się skalowanie sieci.
Jednak EndpointSlices rozwiązują ten problem, umożliwiając Kubernetes skalowanie w takim stopniu, w jakim jest to potrzebne. Zamiast używać pojedynczego punktu końcowego, który zawiera ogromną listę adresów IP i powiązanych z nimi numerów portów, użyj wielu elementów EndpointSlice. Te elementy EndpointSlice to małe fragmenty ogromnego pojedynczego punktu końcowego. Te plasterki są znacznie mniejsze, ale zmniejszają obciążenie spowodowane przez ogromny punkt końcowy. W jednym EndpointSlice można przechowywać do 100 zasobników. Te elementy EndpointSlice ułatwiają dystrybucję usługi do określonego zasobnika. Jeśli jakikolwiek punkt końcowy sieci ulegnie zmianie, wystarczy wysłać aktualizacje do elementu EndpointSlice, który zawiera maksymalnie 100 zasobników. Wszystkie inne pody w sieci pozostają nietknięte.
Teraz dowiedzmy się, jak możemy utworzyć Kubernetes EndpointSlice.
W jaki sposób tworzone są elementy EndpointSlice w Kubernetes?
Kubernetes EndpointSlices to najlepsza alternatywa dla pojedynczego punktu końcowego w klastrze Kubernetes. Nie tylko pomaga w łatwym i wydajnym śledzeniu wszystkich punktów końcowych sieci, ale także zapewnia lepszą wydajność w porównaniu z pojedynczym punktem końcowym. Pokazuje również mniejszy ruch w sieci, oferując jednocześnie skalowalną niezawodność. Co więcej, użycie wielu EndpointSlices pozwala na mniej pracy na płaszczyźnie kontroli i węzłach w klastrze Kubernetes.
W poniższych przykładach możesz zapoznać się z krokami, które pozwolą Ci dowiedzieć się, jak utworzyć EndpointSlices w klastrze Kubernetes.
Krok 1: Uruchom klaster Minikube
Pierwszym i najważniejszym krokiem jest upewnienie się, że klaster minikube jest aktywny. Nieaktywny klaster minikube nie pozwoli na wykonanie jakiejkolwiek pracy w środowisku Kubernetes, dlatego upewnij się, że jest w trybie aktywnym. Aby upewnić się, że klaster minikube działa i działa, użyj następującego polecenia:
> uruchomić minikube 
Jeśli twój klaster minikube nie został uruchomiony wcześniej lub jest w trybie uśpienia, to polecenie wybudza go i uruchamia. Teraz masz aktywny klaster minikube. Możesz już utworzyć EndpointSlice w swoim środowisku Kubernetes.
Krok 2: Utwórz wdrożenie z plikiem YAML
Plik YAML jest najczęściej używany w Kubernetes do tworzenia wdrożeń. Możesz użyć istniejącego pliku YAML wdrożenia lub utworzyć nowy za pomocą następującego polecenia:
> punkt końcowy nano.yamlSpowoduje to utworzenie nowego pliku YAML o nazwie „endpoint.yaml”, w którym można zapisać definicję wdrożenia na potrzeby konfiguracji. Zapoznaj się z definicją wdrożenia na poniższym zrzucie ekranu:
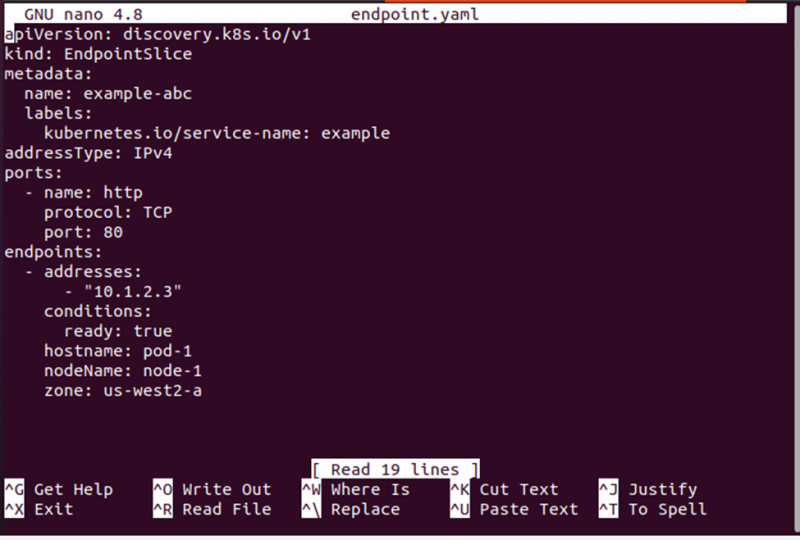
Krok 3: Utwórz EndpointSlice przy użyciu pliku YAML
Teraz, gdy mamy plik YAML, który zawiera definicję wdrożenia, używamy go do tworzenia EndpointSlices w naszym klastrze Kubernetes. Musimy wdrożyć plik konfiguracyjny, abyśmy mogli mieć EndpointSlices w klastrze Kubernetes. Używamy następującego polecenia, aby wdrożyć plik konfiguracyjny:
> kubectl utwórz -f punkt końcowy.yamlW środowisku Kubernetes zasoby są tworzone za pomocą polecenia „kubectl create”. Dlatego używamy polecenia „kubectl create”, aby utworzyć EndpointSlices z pliku konfiguracyjnego YAML.

Wniosek
Eksplorowaliśmy EndpointSlices w środowisku Kubernetes. EndpointSlice w Kubernetes to obiekt, który służy do śledzenia wszystkich punktów końcowych sieci w klastrze Kubernetes. Jest to najlepsza alternatywa dla ogromnego i pojedynczego punktu końcowego w klastrze Kubernetes, ponieważ zapewnia lepszą skalowalność i opcje rozszerzalności. Te elementy EndpointSlice umożliwiają klastrowi Kubernetes uzyskanie lepszej wydajności dzięki zmniejszeniu nakładów pracy na węzły i płaszczyznę sterowania. Na przykładzie nauczyliśmy się tworzyć EndpointSlice w klastrze Kubernetes.