W tym przewodniku wyjaśniono roboty indeksujące listy w AWS.
Czym są List-Crawlery w AWS?
Crawler to składnik kleju AWS, który służy do indeksowania lokalizacji danych i wyprowadzania tych informacji z powrotem do katalogu. Informacje zbierane przez przeszukiwacz mogą obejmować typy danych, strukturę schematu lub innymi słowy gromadzone metadane. Crawler może być również używany z katalogiem danych, który jest używany, gdy dane są przenoszone w ekosystemie Glue podczas korzystania z zadań ETL itp.
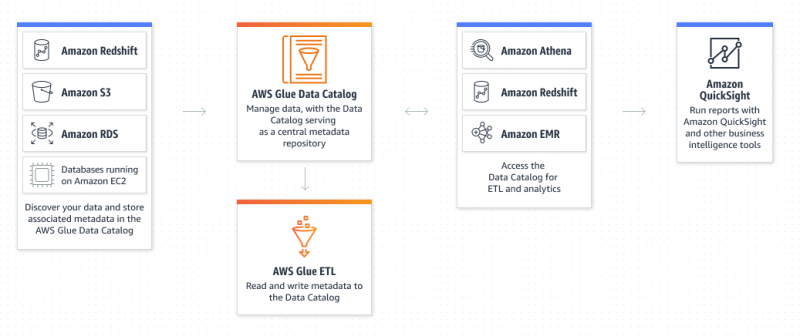
Co to jest usługa Amazon Glue?
AWS Glue to usługa Amazon Extract Transform and Load, która pozwala użytkownikowi organizować, lokalizować, przenosić i przekształcać wszystkie dane. AWS Glue jest bezserwerowy, ponieważ użytkownik nie musi udostępniać i konfigurować serwerów ani zarządzać cyklami życia. Katalog danych i roboty indeksujące to komponenty AWS Glue, które działają jako trwałe repozytorium metadanych:

Jak stworzyć robota na AWS?
Aby utworzyć robota w AWS, odwiedź usługę AWS Glue z konsoli zarządzania AWS:
Udaj się do „ Pełzacze ” klikając na jej nazwę z lewego panelu:
Kliknij na ' Utwórz robota ' przycisk:
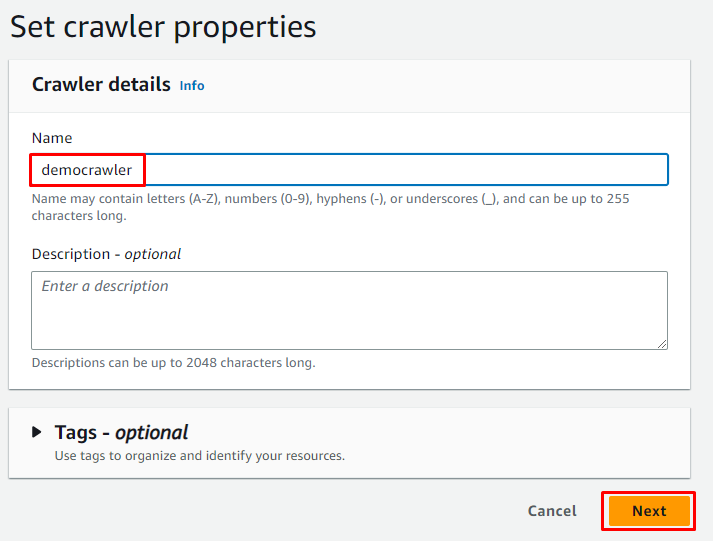
Wpisz nazwę robota i kliknij „ Następny ' przycisk:
Wybierz opcję mapowania dla tabel kleju i kliknij przycisk „ Dodaj źródło ”, aby pobrać dane z:

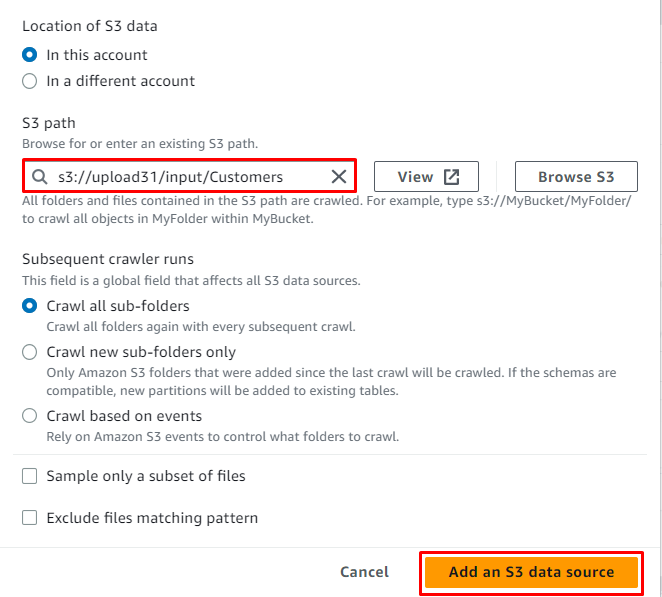
Wybierz usługę S3 i kliknij przycisk „ Przeglądaj S3 ”, aby uzyskać lokalizację źródła:

Po prostu wybierz folder S3 i kliknij przycisk „ Wybierać ' przycisk:

Po dodaniu lokalizacji do źródła wystarczy kliknąć przycisk „ Dodaj źródło danych S3 ' przycisk:
Kliknij na ' Następny ' przycisk:

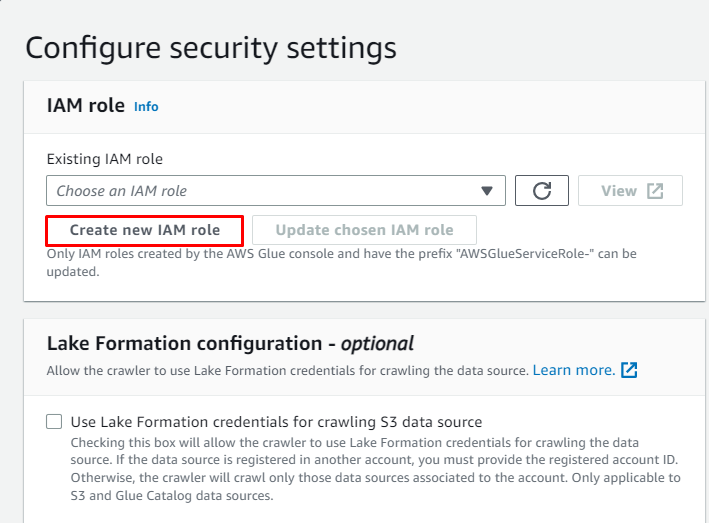
Kliknij na ' Utwórz nową rolę IAM przycisk „ z „ Skonfiguruj ustawienia zabezpieczeń ' Sekcja:
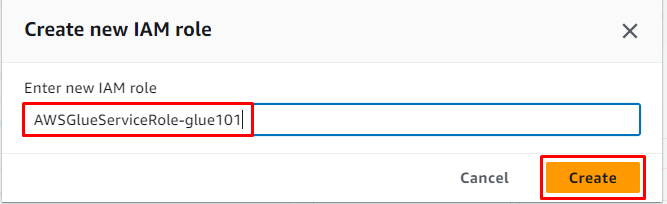
Wprowadź nazwę roli i kliknij przycisk „ Tworzyć ' przycisk:
Następnie po prostu kliknij „ Następny ' przycisk:

Wybierz docelową bazę danych i wpisz nazwę, która będzie używana dla tabeli:
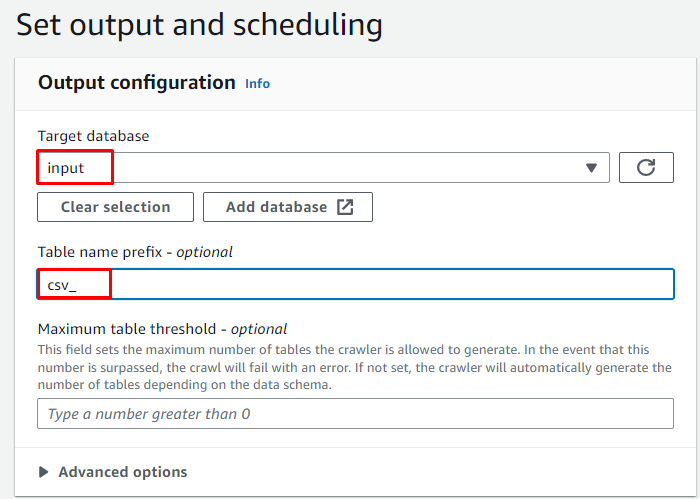
Zaplanuj działanie robota na „ Na żądanie ” i kliknij przycisk „ Następny ' przycisk:
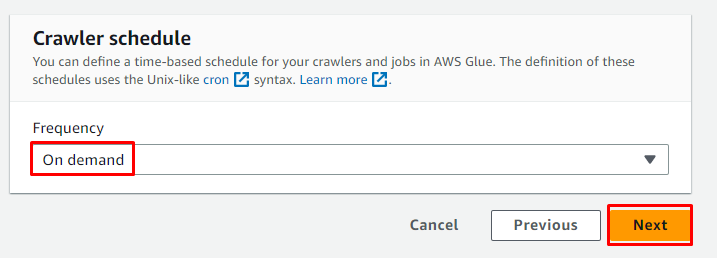
Przejrzyj konfigurację i kliknij „ Utwórz robota ' przycisk:
Robot indeksujący został pomyślnie utworzony i można go użyć do pobrania danych ze źródła, klikając przycisk „ Uruchomić ' przycisk:

To wszystko o robotach indeksujących listy w AWS.
Wniosek
ListCrawler to komponent usługi AWS Glue, który może służyć do indeksowania informacji ze źródeł i powrotu do katalogu. Katalogi danych i roboty indeksujące mogą służyć do gromadzenia danych w celu uzyskania informacji o danych, które są znane jako metadane. Użytkownik może również utworzyć crawler z AWS Glue, aby pobierać dane z usługi S3 lub innych źródeł i umieszczać utworzone tabele w bazie danych. W tym przewodniku wyjaśniono ListCrawlery w AWS i sposób ich tworzenia.