W tym artykule omówimy, jak używać interfejsu API multi-get Elasticsearch do pobierania wielu dokumentów JSON na podstawie ich identyfikatorów. Ponadto Elasticsearch pozwala na użycie pojedynczego zapytania get do pobrania dokumentów z indeksów przy użyciu tylko identyfikatorów dokumentów.
Odkryjmy.
Składnia żądania
Poniżej znajduje się składnia multi-get API Elasticsearch:
POBIERZ /_mget
POBIERZ /
Multi-get API obsługuje wiele indeksów, co pozwala na pobieranie dokumentów, nawet jeśli nie znajdują się one w tym samym indeksie.
Żądanie obsługuje następujące parametry ścieżki:
-
– Nazwa indeksu, z którego mają być pobierane dokumenty, zgodnie z ich identyfikatorami.
Możesz także określić inne parametry zapytania, jak pokazano:
- Pierwszeństwo – Definiuje preferowany węzeł lub fragment.
- Czas rzeczywisty – Jeśli ustawione na true, operacja jest wykonywana w czasie rzeczywistym.
- Odświeżać – Wymusza na operacji odświeżenie fragmentów docelowych przed pobraniem określonych dokumentów.
- Wytyczanie – Wartość używana do kierowania operacji do określonego fragmentu.
- Store_fields – Pobiera pola dokumentu przechowywane w indeksie, a nie w dokumencie.
- _źródło – Wartość logiczna określająca, czy żądanie powinno zwracać pole _source, czy nie.
Zapytanie wymaga treści, która zawiera następujące wartości:
- Dokumenty – Określa dokumenty, które chcesz pobrać. Ponadto ta sekcja obsługuje następujące atrybuty:
- _ID – Unikalny identyfikator dokumentu docelowego.
- _indeks – Indeks zawierający dokument docelowy.
- Wytyczanie – Klucz do podstawowego fragmentu dokumentu.
- _źródło – Jeśli prawda, obejmuje wszystkie pola źródłowe; w przeciwnym razie je wyklucza.
- _stored_fields – Przechowywane_pola, które chcesz uwzględnić.
- Identyfikatory – Identyfikatory dokumentów, które chcesz pobrać.
Przykład 1: Pobierz wiele dokumentów z tego samego indeksu
Poniższy przykład pokazuje, jak używać interfejsu API multi-get Elasticsearch do pobierania dokumentów z określonymi identyfikatorami z indeksu Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: raportowanie' -H 'Typ treści: aplikacja/json' -d'{
'dokumenty': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Podane żądanie powinno pobrać dokumenty o określonych identyfikatorach z indeksu Netflix. Wynikowy wynik jest następujący:
{'dokumenty': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_wersja 1,
'_seq_no': 0,
'_primary_term': 1,
'znaleziono': prawda,
'_źródło': {
'czas trwania': '90 min',
'listed_in': 'Dokumenty',
„kraj”: „Stany Zjednoczone”,
'date_added': '25 września 2021',
'show_id': 's1',
'reżyser': 'Kirsten Johnson',
'rok_wydania': 2020,
'ocena': 'PG-13',
'description': 'Gdy jej ojciec zbliża się do końca życia, filmowiec Kirsten Johnson inscenizuje swoją śmierć w pomysłowy i komiczny sposób, aby pomóc im stawić czoła nieuniknionemu.',
'typ': 'Film',
'tytuł': 'Dick Johnson nie żyje'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_wersja 1,
'_seq_no': 12,
'_primary_term': 1,
'znaleziono': prawda,
'_źródło': {
„kraj”: „Niemcy, Czechy”,
'show_id': 's13',
'reżyser': 'Christian Schwochow',
'rok_wydania': 2021,
'ocena': 'TV-MA',
'description': 'Po tym, jak większość jej rodziny zostaje zamordowana w zamachu terrorystycznym, młoda kobieta zostaje nieświadomie zwabiona do przyłączenia się do tej samej grupy, która ją zabiła.',
'typ': 'Film',
'tytuł': 'Jestem Karl',
'czas trwania': '127 min',
'listed_in': 'Dramaty, filmy międzynarodowe',
'obsada': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 września 2021'
}
}
]
}
Możemy również uprościć żądanie, umieszczając identyfikatory dokumentów w prostej tablicy, jak pokazano poniżej:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: raportowanie' -H 'Typ treści: aplikacja/json' -d'{
'identyfikatory': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Poprzednie żądanie powinno wykonać podobną akcję.
Przykład 2: Pobierz dokumenty z wielu indeksów
W poniższym przykładzie żądanie pobiera wiele dokumentów z różnych indeksów, jak pokazano:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: raportowanie' -H 'Typ treści: aplikacja/json' -d'{
'dokumenty': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Wynikowy wynik jest następujący:

Przykład 3: Wyklucz określone pola
Możemy wykluczyć określone pola z danego żądania za pomocą parametrów source_include i source_exclude.
Przykład jest jak pokazano:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: raportowanie' -H 'Typ treści: aplikacja/json' -d'{
'dokumenty': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
„_źródło”: fałsz
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_źródło': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'opis', 'typ', 'data_dodania' ]
}
}
]
}'
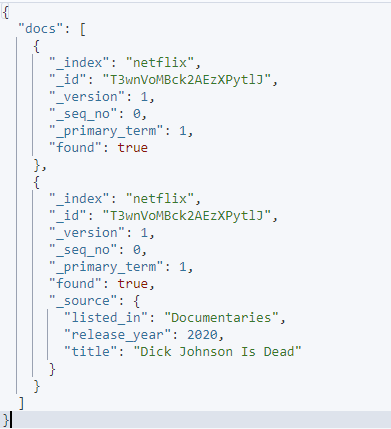
Podane żądanie używa źródła include i exclude do określania, które pola chcesz pobrać w danym dokumencie.
Wynikowy wynik jest następujący:
Wniosek
W tym poście omówiliśmy podstawy pracy z interfejsem API multi-get Elasticsearch, który umożliwia pobieranie wielu dokumentów z różnych źródeł na podstawie ich identyfikatorów. Zachęcamy do zapoznania się z innymi dokumentami, aby uzyskać więcej informacji.
Udanego kodowania!