„Pandy” to świetny język do przeprowadzania analizy danych ze względu na wspaniały ekosystem pakietów opartych na danych Pythona. Ułatwia to analizę i importowanie obu czynników. Odchylenie standardowe to „typowe” odchylenie wyprowadzone ze średniej. Jest często używany, ponieważ zwraca oryginalne jednostki miary ramki danych. Pandy użyły std() do obliczenia odchylenia standardowego. Odchylenie standardowe można obliczyć z podanych wartości, które mogą znajdować się w ramce danych w postaci wiersza lub kolumny. Będziemy wdrażać wszystkie możliwe sposoby wykorzystania odchylenia standardowego pand. Do implementacji kodu użyjemy narzędzia „spyder”, ponieważ jest napisane w środowisku przyjaznym dla Pythona.”
Składnia
„df.std ( ) ”
Poniższa składnia służy do obliczania odchylenia standardowego w ramce danych. „df” w ramce danych to skrót od „ramki danych”. Co robi odchylenie standardowe? Mierzy, jak rozszerzone są wymagane dane. Im bardziej rozszerzone wysokie wartości, tym wyższe powinno wystąpić odchylenie standardowe.
Zwrócić
Odchylenie standardowe pandy zwraca ramkę danych, jeśli poziom jest określony na podstawie wymagania.
Zauważ, że funkcja „std()” automatycznie zignoruje wartości „NaN” w „df” podczas obliczania odchylenia standardowego pand. „NaN” można wytłumaczyć jako „nie liczba”, co oznacza, że nie ma przypisanej żadnej wartości.
Poniżej przedstawiono metody, które zostaną wykonane na przykładach odchylenia standardowego pand:
-
- Obliczanie odchylenia standardowego Pandy w jednej kolumnie.
- Obliczanie odchylenia standardowego Pandy w wielu kolumnach.
- Obliczanie odchylenia standardowego Pandy we wszystkich kolumnach liczbowych.
- odchylenie standardowe pandy przy użyciu osi = 1.
- odchylenie standardowe pandy przy użyciu osi = 0.
Tworzenie Dataframe do obliczania odchylenia standardowego w Pandas
Najpierw otwórz oprogramowanie „spyder”. Teraz zaimportuj bibliotekę pandy jako pd. Stworzymy ramkę danych składającą się z tablicy wyników zawierającej terminy „x”, „y” i „z” z ich punktami jako „22”, „10”, „11”, „16”, „12”, „45 ”, „36” i „40”. Mamy ich wartości asyst „8”, „9”, „13”, „7”, „22”, „24”, „4” i „6”, a także wartości zbiórek „17”, „ 14”, „3”, 5”, „9”, „8”, „7” i „4”.
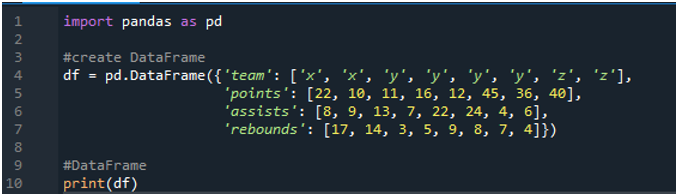
Wyświetlacze pokazują utworzoną ramkę danych zgodnie z wartościami przypisanymi w kodzie:

Przykład # 01: Obliczanie odchylenia standardowego Pandy w jednej kolumnie
W tym przykładzie obliczymy odchylenie standardowe pojedynczej kolumny w ramce danych pandas. Ramka danych zawiera wartości zespołu jako „u”, „v” i „b” z punktami jako „44”, „33”, „22”, „44”, „45”, „88”, „96 ” i „78”. Wartości asyst to „7”, „8”, „9”, „10”, „11”, „14”, „18” i „17” oraz zbiórki jako „11”, „ 9”, „8”, „7”, „6”, „5”, „4” i „3”. Kolumna „punkty” jest wybierana z ramki danych w celu obliczenia odchylenia standardowego pojedynczej kolumny.
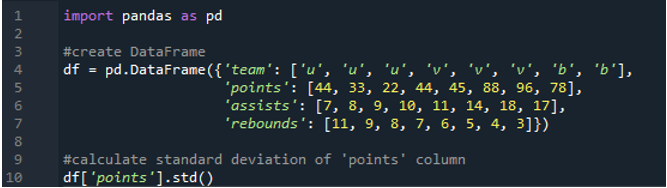
Wynik pokazuje odchylenie standardowe obliczone z kolumny „punkty”:

Przykład # 02: Obliczanie odchylenia standardowego Pandy w wielu kolumnach
W tym przykładzie wykonamy obliczenia odchylenia standardowego pandy w wielu kolumnach. W tej ramce danych dane ponownie dotyczą tablicy wyników sportowych z wartościami zespołu jako „n”, „w” i „t” z wynikiem „33”, „22”, „66”, „55”, „44”, „88”, „99” i „77”. Asysty to „9”, „7”, „8”, „11”, „16”, „14”, „12” i „13” oraz zbiórki „5”, „8”, „1”, „ 2”, „3”, „4”, „6” i „7”. Tutaj obliczymy odchylenie standardowe dwóch kolumn „punkty” i „odbicia” za pomocą funkcji std() zastosowanej do ramki danych.
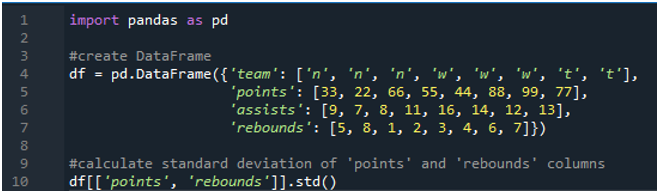
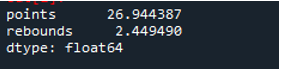
Jak widać, dane wyjściowe pokazują, że odchylenie standardowe wyniosło odpowiednio 26,944387 w kolumnie punktów i 2,449490 w kolumnie odbicia.
Przykład nr 03: Obliczanie odchylenia standardowego Pandy dla wszystkich kolumn liczbowych
Teraz nauczyliśmy się obliczać odchylenie standardowe pojedynczego i wielu wierszy. Co jeśli nie chcemy określać wszystkich nazw kolumn w ramce danych i obliczać całej ramki danych? Jest to możliwe dzięki prostej implementacji funkcji odchylenia standardowego pandy do obliczenia całej ramki danych w wynikach. Ramka danych składa się tutaj z „l”, „m” i „o” z wartościami punktacji „33”, „36”, „79”, „78”, „58”, „55”, a dwie drużyny uzyskują takie same wyniki czyli „25”. Asysty to „1”, „2”, „3”, „4”, „6”, „9”, „5” i „7”, a zbiórki to „14”, „10”, „2” , „5”, „8”, „3”, „6” i „9”. Możemy obliczyć wszystkie standardowe odchylenia kolumn przez pandy w ramce danych za pomocą funkcji pandy „std()”.
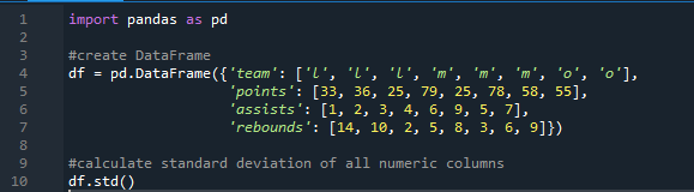
Wyświetlacz ma obliczone odchylenie standardowe całego „df” pokazane poniżej; możemy również zauważyć, że pandy nie obliczyły odchylenia standardowego pierwszej kolumny, czyli „zespołu”, ponieważ nie jest to kolumna liczbowa.
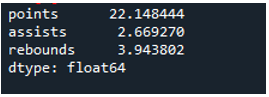
Przykład # 04: Odchylenie standardowe Pandy przy użyciu osi = 0
W tym przykładzie ramki danych zawierają drużyny sportowe jako „g”, „h” i „k” z dalszymi danymi. Tutaj obliczymy odchylenie standardowe, używając osi jako „0”, parametru używanego w odchyleniu standardowym pand. Ten argument oblicza odchylenie standardowe dla kolumny danych w ramce danych.
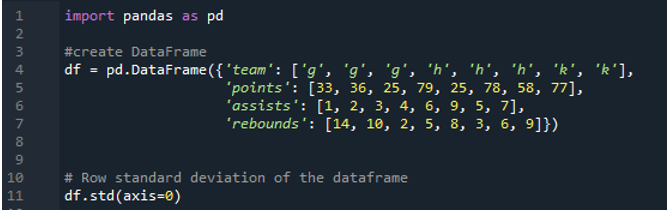
Poniższe dane wyjściowe wyświetlają wyniki w kolumnach obliczonego odchylenia standardowego. Kolumna punktów ma obliczone odchylenie standardowe jako „24.0313062”, kolumna asyst ma obliczone odchylenie standardowe jako „2.669270”, a obliczone odchylenie standardowe kolumny odbicia jest pokazane jako „3.943802”.
Przykład # 05: Odchylenie standardowe Pandy przy użyciu osi = 1
Tutaj użyjemy parametru osi przypisanego jako „1”, aby obliczyć odchylenie standardowe w pandach. Jaką różnicę może zrobić oś „1”? Argument osi „1” oblicza rzędowe odchylenie standardowe wartości liczbowych w ramce danych. Ramka danych zawiera trzy zespoły jako „s”, „d” i „e”, z dodatkiem kolumn danych utworzonych jako punkty zespołu, asysty zespołu i zbiórki zespołu. Wszystkie kierunki mają przypisane różne wartości w ramce danych. Ten parametr osi jest takim zmieniaczem gry, że do czasu musimy pracować na danych tam, gdzie chcemy, aby były w kolumnie plus punkt wyliczony z wykonanego odchylenia standardowego.
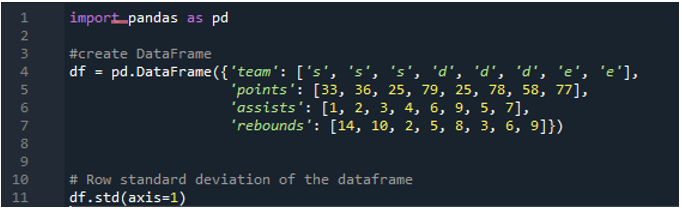
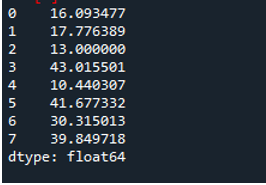
Poniższe dane wyjściowe wyświetlają odchylenie standardowe obliczone w wierszu ramki danych:
Wniosek
Odchylenie standardowe pandy jest bardzo techniczną funkcją, która jest bardzo korzystna, ponieważ znajduje odchylenie standardowe paktu entuzjazmu ramek danych pand. W tym artykule wstępnym przyjrzeliśmy się metodom obliczania odchylenia standardowego u pand. Wykonaliśmy obliczenia odchylenia standardowego na jednej kolumnie i wielu kolumnach, a także obliczyliśmy razem odchylenie standardowe całej ramki danych. Wszystkie strategie działają dobrze, o ile są stosowane konsekwentnie iz pożądanymi rezultatami.