W tym artykule omówimy, jak przydzielać RÓŻNY pamięć poprzez „ pytorch_cuda_alloc_conf ' metoda.
Jaka jest metoda „pytorch_cuda_alloc_conf” w PyTorch?
W zasadzie „ pytorch_cuda_alloc_conf ” to zmienna środowiskowa w ramach PyTorch. Zmienna ta umożliwia efektywne zarządzanie dostępnymi zasobami obliczeniowymi, co oznacza, że modele działają i dają wyniki w możliwie najkrótszym czasie. Jeśli nie zostanie to zrobione prawidłowo, „ RÓŻNY ” platforma obliczeniowa wyświetli „ brak pamięci ” błąd i wpływa na czas wykonania. Modele, które mają być trenowane na dużych ilościach danych lub mają duże „ rozmiary partii ” może powodować błędy w czasie wykonywania, ponieważ ustawienia domyślne mogą być dla nich niewystarczające.
„ pytorch_cuda_alloc_conf ” zmienna wykorzystuje następujące „ opcje ” do obsługi alokacji zasobów:
- rodzinny : Ta opcja wykorzystuje już dostępne ustawienia w PyTorch w celu przydzielenia pamięci do trwającego modelu.
- max_split_size_mb : Zapewnia, że żaden blok kodu większy niż określony rozmiar nie zostanie podzielony. Jest to potężne narzędzie zapobiegające „ podział ”. Wykorzystamy tę opcję do demonstracji w tym artykule.
- roundup_power2_divisions : Ta opcja zaokrągla rozmiar alokacji do najbliższej „ potęga 2 ” podział w megabajtach (MB).
- roundup_bypass_threshold_mb: Może zaokrąglić wielkość alokacji dla każdego żądania zawierającego kwotę większą niż określony próg.
- próg_zbierania_śmieci : Zapobiega opóźnieniom, wykorzystując dostępną pamięć procesora graficznego w czasie rzeczywistym, aby zapewnić, że protokół odzyskiwania wszystkiego nie zostanie zainicjowany.
Jak przydzielić pamięć za pomocą metody „pytorch_cuda_alloc_conf”?
Każdy model z dużym zbiorem danych wymaga dodatkowej alokacji pamięci, większej niż ustawiona domyślnie. Należy określić niestandardową alokację, biorąc pod uwagę wymagania modelu i dostępne zasoby sprzętowe.
Aby skorzystać z opcji „ pytorch_cuda_alloc_conf ” w Google Colab IDE, aby przydzielić więcej pamięci złożonemu modelowi uczenia maszynowego:
Krok 1: Otwórz Google Colab
Wyszukaj w Google Współpraca w przeglądarce i utwórz „ Nowy notatnik ” aby rozpocząć pracę:
Krok 2: Skonfiguruj niestandardowy model PyTorch
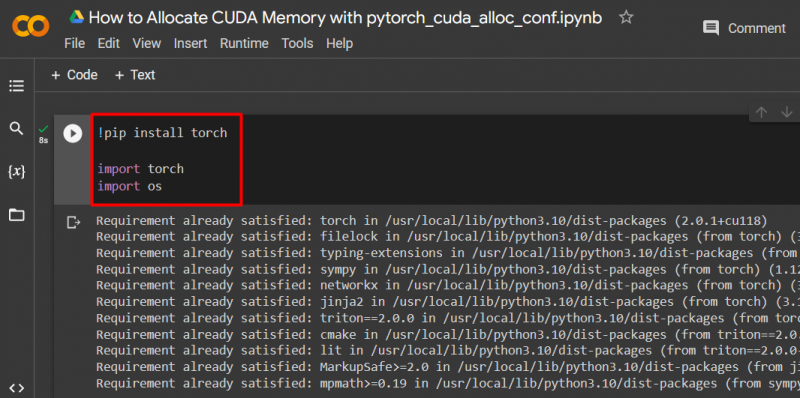
Skonfiguruj model PyTorch za pomocą „ !pypeć ” pakiet instalacyjny, aby zainstalować „ latarka „biblioteka” i „ import ” polecenie importu „ latarka ' I ' Ty ”biblioteki do projektu:
importuj pochodnię
importuj nas
Do tego projektu potrzebne są następujące biblioteki:
- Latarka – Jest to podstawowa biblioteka, na której opiera się PyTorch.
- TY – „ system operacyjny ” służy do obsługi zadań związanych ze zmiennymi środowiskowymi takimi jak „ pytorch_cuda_alloc_conf ”, a także katalog systemowy i uprawnienia do plików:
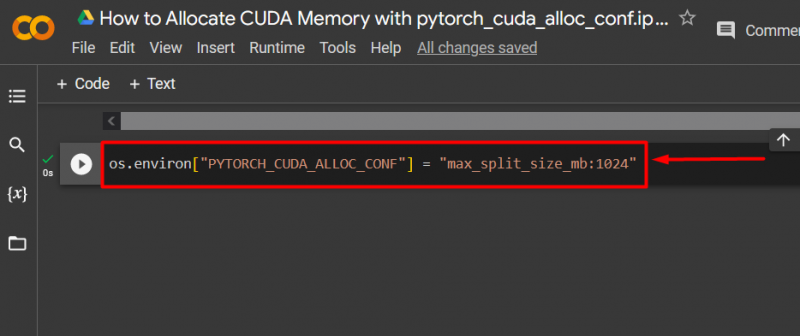
Krok 3: Przydziel pamięć CUDA
Użyj ' pytorch_cuda_alloc_conf ”, aby określić maksymalny rozmiar podziału za pomocą „ max_split_size_mb ”:
Krok 4: Kontynuuj swój projekt PyTorch
Po określeniu „ RÓŻNY ” przydział miejsca za pomocą „ max_split_size_mb ”, kontynuuj normalną pracę nad projektem PyTorch, bez obawy, że „ brak pamięci ' błąd.
Notatka : tutaj możesz uzyskać dostęp do naszego notatnika Google Colab połączyć .
Wskazówka profesjonalna
Jak wspomniano wcześniej, „ pytorch_cuda_alloc_conf ” może przyjąć dowolną z powyższych opcji. Używaj ich zgodnie ze specyficznymi wymaganiami swoich projektów głębokiego uczenia się.
Powodzenie! Właśnie pokazaliśmy, jak używać „ pytorch_cuda_alloc_conf ”, aby określić „ max_split_size_mb ” dla projektu PyTorch.
Wniosek
Użyj ' pytorch_cuda_alloc_conf ” metodę alokacji pamięci CUDA przy użyciu dowolnej z dostępnych opcji zgodnie z wymaganiami modelu. Każda z tych opcji ma na celu złagodzenie konkretnego problemu z przetwarzaniem w projektach PyTorch w celu zapewnienia lepszego czasu działania i płynniejszego działania. W tym artykule przedstawiliśmy składnię użycia „ max_split_size_mb ” opcja zdefiniowania maksymalnego rozmiaru podziału.