Pandy są jednymi z najpopularniejszych narzędzi używanych obecnie przez naukowców zajmujących się danymi do analizy danych tabelarycznych. Aby poradzić sobie z treściami tabelarycznymi, oferuje szybsze i bardziej efektywne API. Za każdym razem, gdy przeglądamy ramki danych podczas analizy, Pandy automatycznie ustawiają różne zachowania wyświetlania na wartości domyślne. Te zachowania wyświetlania obejmują liczbę wyświetlanych wierszy i kolumn, dokładność elementów zmiennoprzecinkowych w każdej ramce danych, rozmiary kolumn itp. W zależności od wymagań czasami może być konieczne zmodyfikowanie tych wartości domyślnych. Pandy mają różne podejścia do zmiany domyślnego zachowania. Wykorzystanie atrybutu „opcje” pand pozwoliło nam zmienić to zachowanie.
Pandy wyświetlają maksymalną liczbę rzędów
Za każdym razem, gdy spróbujesz wydrukować dużą ramkę danych, która zawiera więcej wierszy i kolumn niż wstępnie zdefiniowany próg, dane wyjściowe zostaną przycięte. Aby wyświetlić wszystkie wiersze w DataFrame, nauczysz się modyfikować opcje wyświetlania Pand w tym samouczku. Pandy domyślnie nakładają limit na liczbę wyświetlanych kolumn i wierszy. Chociaż może to być przydatne do czytania treści, często powoduje frustrację, jeśli informacje, które chcesz wyświetlić, nie są wyświetlane. Tutaj będziemy używać metod podanych poniżej wraz z ich składnią, aby wyświetlić wszystkie kolumny ramki danych.
do_ciągu()

zestaw_opcji()

opcja_kontekst()

Nauczymy się wykorzystywać wszystkie te metody z praktyczną implementacją do wyświetlania maksymalnej liczby wierszy w dostarczonej ramce danych.
Przykład nr 1: Wykorzystanie metody Pandy to_string()
Ta demonstracja nauczy nas wyświetlać maksymalną liczbę wierszy w ramce danych na terminalu za pomocą metody pandy „to_string()”.
Do kompilacji i wykonania przykładowych programów wybraliśmy narzędzie „Spyder”. W tym przewodniku użyjemy tego narzędzia do wykonania wszystkich naszych przykładów. Uruchomiliśmy narzędzie „Spyder”, aby rozpocząć pisanie skryptu Pythona. Zaczynając od kodu, najpierw musimy załadować niezbędne biblioteki do naszego pliku Pythona, abyśmy mogli korzystać z jego funkcji. Potrzebna nam tutaj biblioteka modułów to „Pandy”. Więc zaimportowaliśmy go do naszego pliku Pythona i nazwaliśmy go aliasem „pd”.
Ponieważ główną operacją tego artykułu jest wyświetlenie maksymalnej liczby wierszy ramki danych, najpierw potrzebujemy ramki danych. Teraz od Ciebie zależy, czy wolisz wygenerować ramkę danych, czy zaimportować plik CSV. Zaimportowaliśmy przykładowy plik CSV. Do wczytania pliku CSV do programu Pythona wykorzystaliśmy funkcję pandy „pd.read_csv()”. W nawiasach tej funkcji umieściliśmy plik CSV, który chcemy odczytać z wyświetlacza, czyli „industry.csv”. Skonstruowaliśmy zmienną „df” do przechowywania danych wyjściowych wygenerowanych przez odczytanie dostarczonego pliku CSV. Następnie wywołaliśmy metodę „print()”, aby wyświetlić ramkę danych.
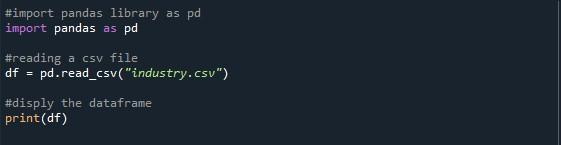
Kiedy uruchamiamy ten program Pythona, naciskając opcję „Uruchom plik”, na konsoli wyświetla się ramka danych. Możesz zauważyć, że w poniższym wyniku są 43 wiersze, ale wyświetlanych jest tylko dziesięć. Dzieje się tak, ponieważ domyślna wartość biblioteki Pandas to tylko 10 wierszy.
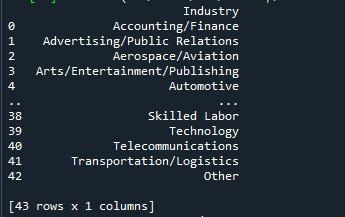
Użyjemy metody pandy „to_string”, aby wyświetlić tutaj wszystkie wiersze. Najprostszym sposobem pokazania maksymalnej liczby wierszy z ramki danych jest ta technika. Jednak ponieważ zamienia pełną ramkę danych w pojedynczy ciąg, nie jest to zalecane w przypadku bardzo dużych zestawów danych (liczących się w milionach). Niemniej jednak działa to skutecznie w przypadku zestawów danych o długości tysięcy.
Postępowaliśmy zgodnie ze składnią podaną powyżej dla funkcji „to_string()”. Po prostu wywołaliśmy metodę „to_string()” z nazwą naszej ramki danych. Następnie umieściliśmy tę metodę w funkcji „print()”, aby wyświetlić ją po wywołaniu.

Migawka wyjściowa pokazuje nam ramkę danych ze wszystkimi wierszami wyświetlanymi na terminalu.
Przykład nr 2: Wykorzystanie metody set_option Pandy
Drugą metodą, którą przećwiczymy w tym przewodniku, są pandy „set_option()”, aby wyświetlić maksymalną liczbę wierszy dostarczonej ramki danych.
W pliku python zaimportowaliśmy bibliotekę pandas, aby uzyskać dostęp do wyżej wymienionej funkcji. Użyliśmy pand „pd.read_csv()” do odczytania dostarczonego pliku CSV. Wywołaliśmy funkcję „pd.read_CSV()” z nazwą pliku CSV, którego chcemy użyć w nawiasach, czyli „Sampledata.csv”. Podczas importowania pliku CSV pamiętaj o bieżącym katalogu roboczym programu Python. Twój plik CSV musi znajdować się w tym samym katalogu; w przeciwnym razie pojawi się komunikat o błędzie „nie znaleziono pliku”. Stworzyliśmy zmienną „samp” do przechowywania dataframe z pliku CSV. Nazywaliśmy metodę „print()”, aby wyświetlić tę ramkę danych.
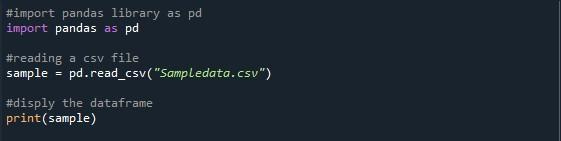
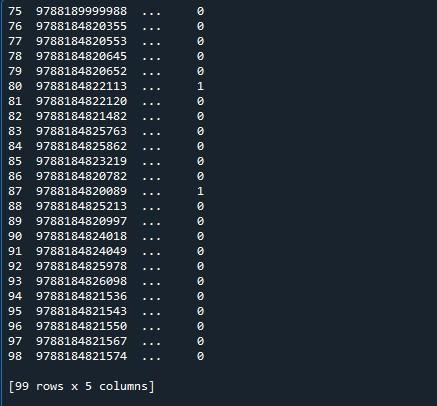
Tutaj mamy nasze wyjście, w którym wyświetlanych jest tylko dziesięć wierszy. Maksymalna wskazana liczba wierszy to 99. Wszystkie pozostałe wiersze między pierwszymi 5 a ostatnimi pięcioma wierszami są obcinane.

Aby wyświetlić maksymalną liczbę wierszy, która wynosi 99 dla tej ramki danych, użyjemy funkcji „set_option()” modułu pandas. Pandy są dostarczane z systemem operacyjnym, który umożliwia zmianę zachowania i wyświetlania. Ta metoda pozwala nam ustawić wyświetlacz tak, aby wyświetlał pełną klatkę danych, a nie obciętą. Pandy udostępniają funkcję „set_ option()” do wyświetlania wszystkich wierszy ramki danych.
Wywołaliśmy „pd.set_option()”. Ta funkcja ma parametry „display.max_rows”. „display.max_rows” określa maksymalną liczbę wierszy, które będą wyświetlane podczas wyświetlania ramki danych. Wartość „max_rows” jest domyślnie ustawiona na 10. Jeśli wybrano „Brak”, oznacza to wszystkie wiersze w ramce danych. Ponieważ chcemy wyświetlić wszystkie wiersze, ustawiamy go na „Brak”. Na koniec użyliśmy funkcji „print()”, aby wyświetlić ramkę danych z maksymalną liczbą wierszy.

Daje to wynik przedstawiony na poniższym zrzucie.
Przykład nr 3: Wykorzystanie metody Pandy option_context()
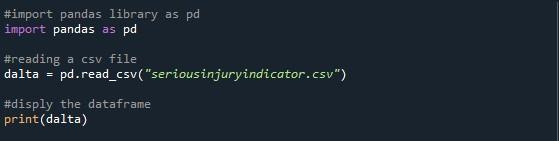
Ostatnią metodą, którą tutaj omawiamy, jest „option_context()”, aby wyświetlić wszystkie wiersze ramki danych. W tym celu zaimportowaliśmy pakiet pandas do pliku Pythona i zaczęliśmy pisać kod. Użyliśmy funkcji „pd.read_csv()” do odczytania określonego przez nas pliku CSV. Stworzyliśmy zmienną „dalta” do przechowywania ramki danych z określonego pliku CSV. Następnie po prostu wydrukowaliśmy ramkę danych za pomocą metody „print()”.
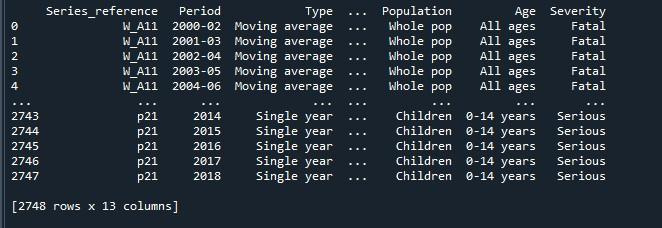
Wynik, który uzyskaliśmy po wykonaniu powyższego kodu, pokazuje nam ramkę danych z obciętymi wierszami.
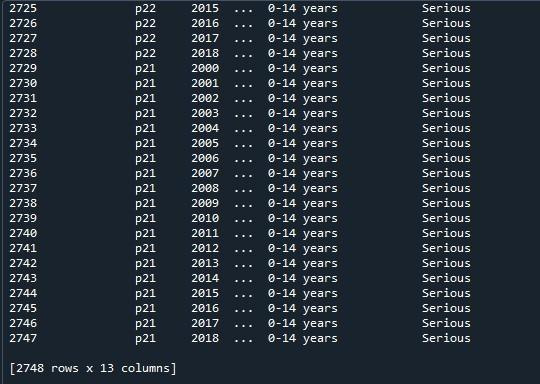
Teraz zastosujemy pandy „pd.option_context()” w tej ramce danych. Ta funkcja jest identyczna z „set_option()”. Jedyna różnica między tymi dwoma podejściami polega na tym, że „set_option()” zmienia ustawienia na stałe, podczas gdy „option _context()” zmienia je tylko w swoim zakresie. Ta metoda przyjmuje również wiersze display.max jako parametr, który ustawiamy na „Brak”, aby renderować wszystkie wiersze ramki danych. Po wywołaniu tej funkcji po prostu wyświetliliśmy ją za pomocą metody „print()”.

Tutaj możemy wyświetlić pełną ramkę danych z maksymalną liczbą wierszy, która wynosi 2747.
Wniosek
Ten artykuł skupia się na opcjach wyświetlania pand. Czasami możemy potrzebować wyświetlić pełną ramkę danych na terminalu. Pandy dają nam wiele możliwości w tym celu. W tym przewodniku zastosowaliśmy trzy z tych strategii. Pierwszy przykład opierał się na użyciu metody „to_string()”. Nasza druga instancja uczy nas implementacji „set_option()”, podczas gdy ostatnia ilustracja wykonuje metodę „option_context()”. Wszystkie te techniki są demonstrowane, aby zapoznać Cię z alternatywnymi sposobami, w jakie pandy zapewniają nam osiągnięcie wymaganego rezultatu.