Jako administratorzy baz danych musimy mieć obsesję na punkcie narzędzi i metod zwiększania wydajności bazy danych.
W PostgreSQL mamy dostęp do polecenia EXPLAIN ANALYZE, które pozwala nam przeanalizować plan wykonania i wydajność danego zapytania do bazy danych. Komenda zwraca szczegółowe informacje o tym, jak silnik bazy danych przetwarza zapytanie. Obejmuje to sekwencję wykonywanych operacji, szacowane koszty zapytań, czas wykonania i inne.
Następnie możemy wykorzystać te informacje do zidentyfikowania zapytań do bazy danych, a także zidentyfikowania i usunięcia potencjalnych wąskich gardeł wydajności.
W tym samouczku omówiono, jak używać polecenia EXPLAIN ANALYZE w PostgreSQL do przeglądania i optymalizowania wydajności zapytań.
ANALIZA WYJAŚNIENIA PostgreSQL
Polecenie jest dość proste. Najpierw musimy dodać polecenie EXPLAIN ANALYZE na początku zapytania, które chcemy przeanalizować.
Składnia polecenia jest następująca:
WYJAŚNIJ ANALIZĘPo wykonaniu polecenia PostgreSQL zwraca szczegółowe dane wyjściowe dotyczące podanego zapytania.
Zrozumienie danych wyjściowych zapytania EXPLAIN ANALYZE
Jak wspomniano, po uruchomieniu polecenia EXPLAIN ANALYZE, PostgreSQL generuje szczegółowy raport planu zapytań i statystyki wykonania.
Dane wyjściowe składają się z zestawu kolumn zawierających przydatne informacje. Wynikowe kolumny są takie, jak pokazano z ich odpowiednim znaczeniem:
PLAN ZAPYTANIA – W tej kolumnie wyświetlany jest plan wykonania określonego zapytania. Plan wykonania odnosi się do sekwencji operacji, które aparat bazy danych wykonuje w celu pomyślnego wykonania zapytania.
PLAN – Druga kolumna to kolumna PLAN. Zawiera tekstową reprezentację każdej operacji lub kroku w planie wykonania. Ponownie, każda operacja jest wcięta, aby wskazać hierarchię operacji.
CAŁKOWITY KOSZT – Kolumna całkowity koszt przedstawia szacowany całkowity koszt zapytania. Koszt odnosi się do względnej miary używanej przez narzędzie do planowania zapytań bazy danych w celu określenia optymalnego planu wykonania.
RZECZYWISTE RZĘDY – Ta kolumna pokazuje dokładną liczbę wierszy, które są przetwarzane na każdym etapie wykonywania zapytania.
AKTUALNY CZAS – Ta kolumna pokazuje rzeczywisty czas każdej operacji, który obejmuje zarówno czas wykonania operacji, jak i czas spędzony na zasobach.
CZAS PLANOWANIA – W tej kolumnie jest wyświetlany czas potrzebny planowaniu zapytań na wygenerowanie planu wykonania. Obejmuje to całkowity czas optymalizacji zapytania i generowania planu.
CZAS EGZEKUCJI – Ta kolumna pokazuje całkowity czas wykonania zapytania. Obejmuje to również czas poświęcony na planowanie i czas wykonania zapytania.
PostgreSQL WYJAŚNIJ ANALIZUJ Przykład
Przyjrzyjmy się kilku podstawowym przykładom użycia instrukcji EXPLAIN ANALYZE.
Przykład 1: Wybierz Wyciąg
Użyjmy instrukcji EXPLAIN ANALYZE, aby pokazać wykonanie prostej instrukcji select w PostgreSQL.
Po uruchomieniu poprzedniej instrukcji powinniśmy otrzymać następujące dane wyjściowe:
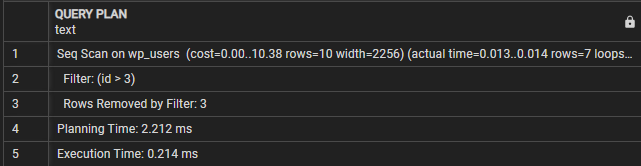
PLAN ZAPYTANIA-------------------------------------------------- ------------------
Seq Scan on wp_users (cost=0.00..10.38 rows=10 width=2256) (rzeczywisty czas=0.009..0.010 rows=7 loops=1)
Filtruj: (identyfikator > 3)
Wiersze usunięte przez filtr: 3
Czas planowania: 0,995 ms
Czas wykonania: 0,021 ms
(5 rzędów)
W tym przypadku możemy zobaczyć, że sekcja Plan zapytań wskazuje, że zapytanie wykonuje sekwencyjne skanowanie tabeli wp_users. Linia filtru oznacza warunek używany do filtrowania wynikowych wierszy.
Następnie widzimy „Rzędy usunięte przez filtr”, które pokazują liczbę wierszy, które zostały wyeliminowane przez warunek filtru.
Wreszcie czas wykonania pokazuje całkowity czas wykonania zapytania. W tym przypadku zapytanie trwa 0,021 ms.
Przykład 2: Analiza łączenia
Weźmy bardziej złożone zapytanie, które obejmuje sprzężenie SQL. W tym celu korzystamy z przykładowej bazy danych Pagila. Możesz pobrać i zainstalować przykładową bazę danych na swoim komputerze w celach demonstracyjnych.
Możemy uruchomić proste łączenie, jak pokazano poniżej:
wyjaśnij przeanalizuj WYBIERZ f.tytuł, c.nazwaZ filmu f
DOŁĄCZ do kategorii_filmów fc ON f.film_id = fc.film_id
DOŁĄCZ do kategorii c ON fc.category_id = c.category_id;
Po uruchomieniu danego zapytania powinniśmy zobaczyć dane wyjściowe w następujący sposób:
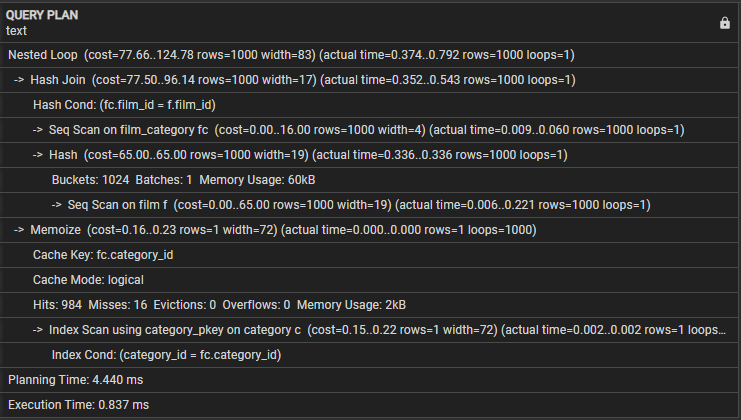
Przyjrzyjmy się następującemu planowi zapytań:
- Zagnieżdżona pętla — wskazuje, że łączenie wykorzystuje strategię łączenia zagnieżdżonej pętli.
- Hash Join – Ta operacja łączy film_category i tabele filmów za pomocą algorytmu łączenia Hash. Ta operacja ma koszt 77,50 i szacuje się, że 1000 wierszy. Jednak rzeczywisty czas potrzebny na tę operację wynosi od 0,254 do 0,439 milisekundy i pobiera 1000 wierszy.
- Hash Cond — wskazuje, że warunek łączenia używa łączenia Hash w celu dopasowania kolumn film_id i kolumn film_category w tabelach filmów.
- Seq Scan on film_category — Ta operacja wykonuje sekwencyjne skanowanie tabeli film_category z kosztem 16,00 i szacunkową liczbą 1000 wierszy. Rzeczywisty czas potrzebny na tę operację wynosi od 0,008 do 0,056 milisekundy i pobiera 1000 wierszy.
- Seq Scan on film – Zapytanie wykonuje sekwencyjne skanowanie na stole filmowym z wynikającymi z tego szacowanymi i rzeczywistymi kosztami oraz wierszami w tej operacji.
- Memoize — Ta operacja buforuje wyniki łączenia między tabelami film_category i film do późniejszego wykorzystania.
- Klucz pamięci podręcznej — wskazuje, że klucz pamięci podręcznej używany do zapamiętywania jest oparty na kolumnie category_id z kategorii film_category.
- Tryb pamięci podręcznej — wskazuje, że zapytanie używa logicznego trybu pamięci podręcznej.
- Trafienia, chybienia, eksmisje, przepełnienia — trzy wiersze zawierają statystyki dotyczące pamięci podręcznej, liczby trafień, chybień, eksmisji i przepełnień podczas wykonywania. Ten blok obejmuje również użycie pamięci podczas wykonywania zapytania.
- Skanowanie indeksu przy użyciu klucza_kategorii — pokazuje operację, która wykonuje skanowanie indeksu w tabeli kategorii przy użyciu indeksu klucza podstawowego.
- Index Cond — pokazuje, że skanowanie indeksu jest oparte na warunku pasującym do kolumny category_id w tabeli kategorii.
- Czas planowania — ten wiersz pokazuje czas potrzebny do zaplanowania zapytania, który wynosi 3,005 milisekundy.
- Czas wykonania — Wreszcie ta linia pokazuje całkowity czas wykonania zapytania, który wynosi 0,745 milisekundy.
Masz to! Szczegółowe informacje o wykonaniu prostego łączenia w PostgreSQL.
Wniosek
Odkryłeś moc i zastosowanie instrukcji EXPLAIN ANALYZE w PostgreSQL. Instrukcja EXPLAIN ANALYZE jest potężnym narzędziem do analizy i optymalizacji zapytań. Użyj tego narzędzia do tworzenia wydajnych i zużywających mniej zasobów zapytań.