HAProxy działa w celu zmniejszenia przeciążenia dowolnego serwera i osiąga to poprzez dystrybucję ruchu w celu zapewnienia, że serwer nie będzie przeciążony, a jednocześnie dostępne będą inne serwery. Platforma taka jak Instagram charakteryzuje się ogromnym ruchem ze względu na żądania wysyłane na sekundę, stąd potrzeba użycia HAProxy do zdefiniowania frontendu, backendu i słuchaczy dla serwerów, aby uniknąć przeciążenia.
Dlaczego warto używać HAProxy
Zanim zapoznasz się z instalacją i konfiguracją HAProxy, powinieneś zrozumieć, dlaczego go potrzebujemy, ze względu na oferowane przez niego funkcje. Poniżej przedstawiono główne cechy HAProxy:
- Równoważenie obciążenia - Dzięki HAProxy możesz wygodnie rozdzielać ruch na różne serwery, aby uniknąć przeciążenia pojedynczego serwera. W ten sposób Twoja aplikacja nie będzie napotykać żadnych problemów z przestojami, a Ty uzyskasz szybszą responsywność, niezawodność i dostępność.
- Rejestrowanie i monitorowanie – Otrzymasz szczegółowe logi monitorowania swoich serwerów, które pomogą Ci w rozwiązywaniu problemów. Poza tym HAProxy ma stronę ze statystykami, na której możesz uzyskać analizy wydajności swojego modułu równoważenia obciążenia w czasie rzeczywistym.
- Badania zdrowia - Nawet Twoje serwery wymagają sprawdzenia stanu, aby określić ich stan. HAProxy często przeprowadza kontrole stanu, aby poznać stan serwera i zwiększyć jego niezawodność. Jeśli zostanie wykryty serwer w złej kondycji, przekierowuje ruch do innego serwera.
- Odwrotne proxy – Jednym ze sposobów zwiększenia bezpieczeństwa jest ukrycie wewnętrznej struktury. Na szczęście HAProxy pozwala odbierać ruch od klientów i kierować go do odpowiednich serwerów. W ten sposób Twoja wewnętrzna struktura jest ukryta przed okiem hakera.
- Listy ACL (listy kontroli dostępu) – Dzięki HAProxy możesz zdefiniować sposób kierowania ruchu, korzystając z różnych kryteriów, takich jak ścieżki, nagłówki i adresy IP. Dzięki temu zdefiniowanie niestandardowej logiki routingu dla Twojego ruchu staje się łatwiejsze.
- Zakończenie SSL – Domyślnie protokół SSL/TLS jest odciążany przez serwery zaplecza, co powoduje zmniejszoną wydajność. Jednak w przypadku HAProxy zakończenie protokołu SSL/TLS następuje w module równoważenia obciążenia, odciążając zadanie na serwerach zaplecza.
Instalowanie HAProxy
Jak dotąd zdefiniowaliśmy, czym jest HAProxy i omówiliśmy funkcje, które oferuje, aby pomóc Ci zrozumieć, dlaczego potrzebujesz go w swojej aplikacji. Następnym krokiem jest zrozumienie, jak zacząć od zainstalowania go w systemie.
Jeśli używasz systemu Ubuntu lub Debian, HAProxy można zainstalować z menedżera pakietów APT. Uruchom następujące polecenie:
$ Sudo trafna aktualizacja
$ sudo apt zainstaluj haproxy
Podobnie, jeśli używasz systemów opartych na RHEL lub CentOS, HAProxy jest dostępny z menedżera pakietów „yum”. Uruchom następujące polecenia:
$ sudo mniam aktualizacja
$ sudo mniam, zainstaluj haproxy
W naszym przypadku korzystamy z Ubuntu. Zatem mamy następujące polecenie:
Możemy następnie sprawdzić jego wersję, aby upewnić się, że udało nam się pomyślnie zainstalować HAProxy.
$ haproxy --wersja 
Jak skonfigurować HAProxy
Po zainstalowaniu HAProxy możesz teraz otworzyć jego plik konfiguracyjny ( / etc/haproxy/haproxy.cfg) i zdefiniuj ustawienia, których chcesz używać w module równoważenia obciążenia.
Otwórz plik konfiguracyjny za pomocą edytora, takiego jak nano lub vim.
$ sudo nano /etc/haproxy/haproxy.cfgOtrzymujesz plik konfiguracyjny podobny do poniższego:
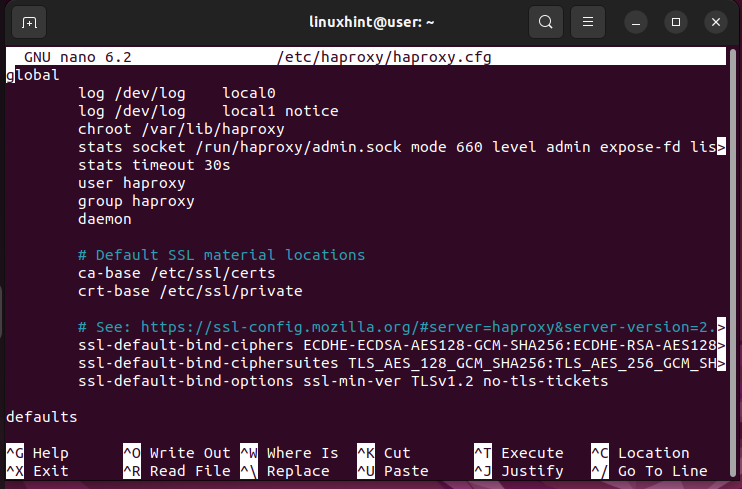
W pliku konfiguracyjnym zauważysz, że zawiera on dwie główne sekcje:
- globalny – Jest to pierwsza sekcja pliku i nie należy zmieniać jej wartości. Zawiera ustawienia procesu, które definiują sposób działania HAProxy. Na przykład definiuje szczegóły logowania oraz grupy lub użytkowników, którzy mogą wykonywać funkcje HAProxy. Pamiętaj, że w tym pliku konfiguracyjnym możesz mieć tylko jedną sekcję globalną, a jej wartości powinny pozostać niezmienione.
- wartości domyślne – Ta sekcja zawiera wartości domyślne węzłów. Na przykład w tej sekcji możesz dodać limity czasu lub tryb działania swojego HAProxy. Poza tym możliwe jest posiadanie wielu sekcji domyślnych w pliku konfiguracyjnym HAProxy.
Oto przykład sekcji „Domyślne”:
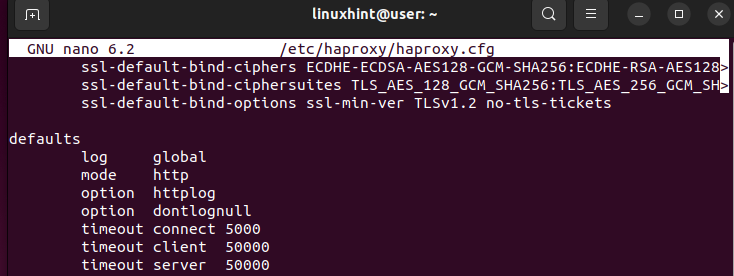
Na podanym obrazku tryb określa, w jaki sposób Twój HAProxy będzie obsługiwał przychodzące żądania. Można ustawić tryb na HTTP lub TCP. Jeśli chodzi o limit czasu, określa on, jak długo HAProxy powinien czekać. Na przykład limit czasu połączenia to czas oczekiwania przed nawiązaniem połączenia zaplecza. Limit czasu klienta określa, jak długo HAProxy powinien czekać na wysłanie danych przez klienta. Limit czasu serwera to czas oczekiwania, aż odpowiedni serwer prześle dane, które zostaną przesłane do klienta. Sposób zdefiniowania wartości domyślnych ma duże znaczenie dla zwiększenia czasu odpowiedzi aplikacji.
Aby moduł równoważenia obciążenia działał zgodnie z oczekiwaniami, należy zdefiniować jeszcze trzy sekcje.
- frontend – Ta sekcja zawiera adresy IP, których mają używać Twoi klienci do nawiązywania połączenia.
- zaplecze – Pokazuje pule serwerów obsługujące żądania zgodnie z definicją w sekcji frontonu.
- Słuchać - Jest używany sukcesywnie, gdy chcesz przekierować określoną grupę serwerów. Sekcja ta łączy w sobie zadania frontendu i backendu.
Weźmy przykład
W tym przykładzie definiujemy frontend tak, aby korzystał z hosta lokalnego z określonym portem. Następnie łączymy go z backendem, na którym działa localhost, a następnie uruchamiamy serwer Python, aby sprawdzić, czy wszystko działa zgodnie z oczekiwaniami w przypadku równoważenia obciążenia. Postępuj zgodnie z podanymi krokami.
Krok 1: Konfiguracja sekcji ustawień domyślnych
W sekcji „Domyślne” ustawiamy wartości, które mają być współdzielone pomiędzy węzłami. W naszym przypadku ustawiliśmy tryb na HTTP i ustawiliśmy limity czasu dla klienta i serwera. Możesz dostosować czas do swoich potrzeb.

Pamiętaj, że wszystkie te zmiany znajdują się w konfiguracji HAProxy znajdującej się w „/etc/haproxy/haproxy.cfg”. Po skonfigurowaniu sekcji ustawień domyślnych zdefiniujmy frontend.
Krok 2: Konfiguracja sekcji frontendu
W sekcji frontend definiujemy, w jaki sposób chcemy, aby aplikacja lub strona internetowa była dostępna dla klientów online. Podajemy adresy IP dla aplikacji. Ale w tym przypadku współpracujemy z localhost. Dlatego nasz adres IP jest adresem zastępczym 127.0.0.1 i chcemy akceptować połączenia przez port 80.

Musisz dodać słowo kluczowe „bind”, które działa jako odbiornik adresu IP na określonym porcie. Zdefiniowany adres IP i port są używane przez moduł równoważenia obciążenia do akceptowania żądań przychodzących.
Po dodaniu poprzednich linii w pliku konfiguracyjnym musimy ponownie uruchomić „haproxy.service” za pomocą następującego polecenia:
$ sudo systemctl uruchom ponownie haproxy 
W tym momencie możemy spróbować wysłać żądania do naszej witryny za pomocą polecenia „curl”. Uruchom polecenie i dodaj docelowy adres IP.
$ curlPonieważ nie zdefiniowaliśmy jeszcze, jaki będzie backend naszego HAProxy, otrzymamy błąd 503, jak pokazano poniżej. Chociaż moduł równoważenia obciążenia zdołał odebrać żądania, obecnie nie jest dostępny żaden serwer, który mógłby je obsłużyć, stąd błąd.

Krok 3: Konfiguracja backendu
W sekcji backend definiujemy serwery, które będą obsługiwać wszelkie przychodzące żądania. Moduł równoważenia obciążenia odwołuje się do tej sekcji, aby wiedzieć, w jaki sposób powinien dystrybuować przychodzące żądania, aby mieć pewność, że żaden serwer nie zostanie przeciążony.
Błąd 503, który otrzymaliśmy wcześniej, wynikał z tego, że nie mieliśmy żadnego backendu do obsługi żądań. Zacznijmy od zdefiniowania „default_backendu” do obsługi żądań. Definiujesz to w sekcji frontendu. W tym przypadku nazwaliśmy go „linux_backend”.
Następnie utwórz sekcję backendu o takiej samej nazwie, jak ta zdefiniowana w sekcji frontendu. Następnie należy użyć słowa kluczowego „serwer”, po którym następuje nazwa serwera i jego adres IP. Poniższy obrazek pokazuje, że zdefiniowaliśmy serwer „linuxhint1” przy użyciu adresu IP 127.0.0.1 i portu 8001:
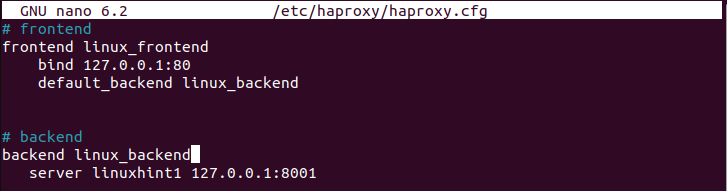
Możesz mieć pulę serwerów backendowych, ale w tym przypadku zdefiniowaliśmy tylko jeden. Upewnij się, że zapisałeś plik. Musimy ponownie zrestartować usługę HAProxy.

Aby przetestować utworzony moduł równoważenia obciążenia HAProxy, tworzymy serwer WWW przy użyciu języka Python3 w celu powiązania portów zaplecza przy użyciu określonego przez nas adresu IP. Uruchamiamy polecenie w następujący sposób:
$ python3 -m http.serwer 8001 --bind 127.0.0.1Upewnij się, że zastąpiłeś wartości zgodne z adresem IP i portem, który chcesz powiązać. Zwróć uwagę na sposób tworzenia serwera WWW i nasłuchiwania przychodzących żądań.

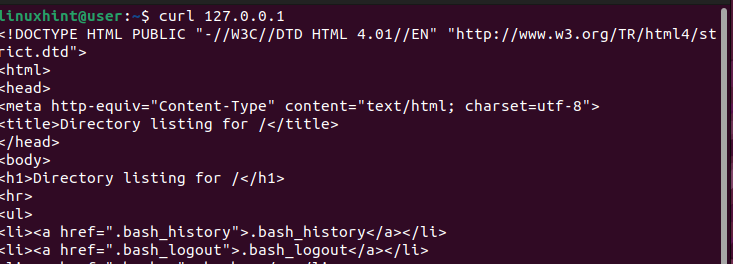
Na innym terminalu użyjmy polecenia „curl”, aby wysłać żądanie do serwera.
$ curlW przeciwieństwie do tego, jak wcześniej otrzymaliśmy błąd 503, który pokazuje, że żaden serwer nie jest dostępny do obsługi żądania, tym razem otrzymujemy wynik potwierdzający, że nasz moduł równoważenia obciążenia HAProxy działa.
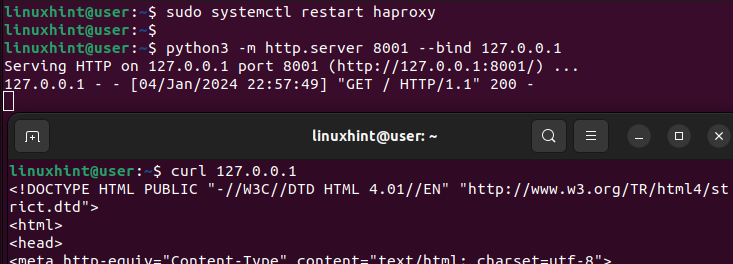
Jeśli wrócisz do poprzedniego terminala, na którym utworzyliśmy serwer WWW, zobaczysz, że otrzymaliśmy wynik 200 powodzenia, który potwierdza, że HAProxy odebrał żądanie i obsłużył je, wysyłając je do zdefiniowanego serwera w naszej sekcji backendu.
W ten sposób możesz ustawić prosty HAProxy dla swojej witryny lub aplikacji.
Praca z regułami
Zanim zakończymy ten samouczek HAProxy dla początkujących, porozmawiajmy szybko o tym, jak zdefiniować reguły określające sposób obsługi żądań przez moduł równoważenia obciążenia.
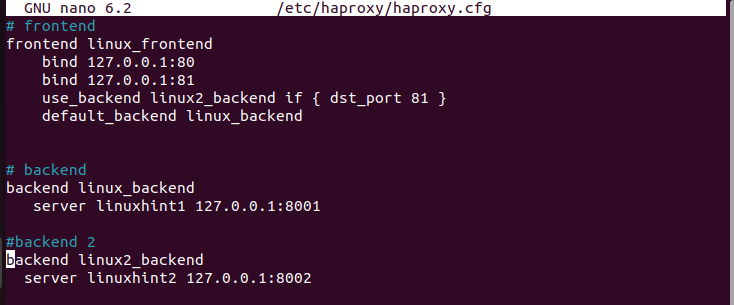
Wykonując te same czynności co poprzednio, zostawmy sekcję domyślną bez zmian i zdefiniujmy różne adresy IP w sekcji frontendu. Łączymy ten sam adres IP, ale akceptujemy połączenia z różnych portów.
Co więcej, mamy nasz „default_backend” i drugi „use_backend”, czyli inną pulę serwerów, z których będziemy korzystać w zależności od portu, z którego przychodzą żądania. W poniższej konfiguracji wszystkie żądania poprzez port 81 są obsługiwane przez serwery w „backendie Linux2”. Wszelkie inne żądania są obsługiwane przez „default_backend”.
Następnie tworzymy sekcje backendu zgodnie z definicją w frontendzie. Należy pamiętać, że dla każdego backendu mamy inny serwer, którego używamy do obsługi żądań.
Szybko uruchom ponownie usługę HAProxy.

Stwórzmy serwer WWW przy użyciu Python3 i powiążmy żądania na porcie 8002, który jest alternatywnym serwerem backendu.

Wysyłając do niego żądania, określamy port jako 81, aby uruchomić moduł równoważenia obciążenia w celu wysłania żądań do serwera alternatywnego, który nie jest serwerem domyślnym.
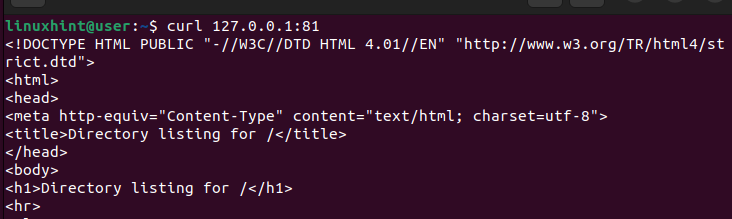
Sprawdzając ponownie nasz serwer WWW, widzimy, że udaje mu się odbierać i obsługiwać żądania oraz daje odpowiedź 200 (powodzenie).
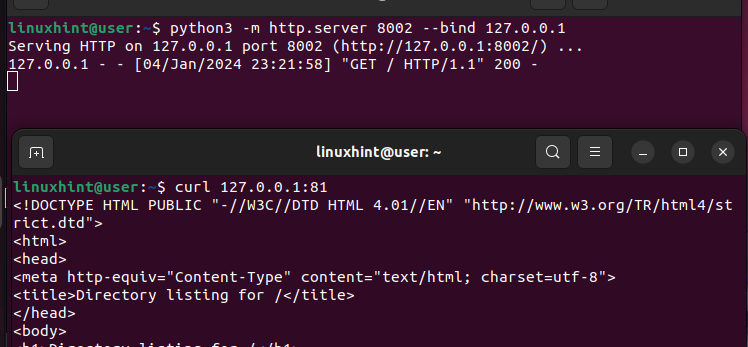
W ten sposób możesz zdefiniować reguły określające sposób, w jaki moduł równoważenia obciążenia będzie odbierał i obsługiwał żądania.
Wniosek
HAProxy to idealne rozwiązanie do równoważenia obciążenia dla aplikacji TCP/HTTP. Po zainstalowaniu możesz wygodnie edytować plik konfiguracyjny, aby zdefiniować sekcje domyślne, frontend i backend, aby określić sposób działania modułu równoważenia obciążenia. Ten post jest przewodnikiem dla początkujących po HAProxy. Zaczęło się od zdefiniowania HAProxy i jego funkcji. Następnie szczegółowo omówiono sposób konfiguracji HAProxy i zakończono podaniem przykładu wykorzystania HAProxy jako modułu równoważenia obciążenia.