Istnieje wiele innych metod klasy File Input Stream, które są również bardzo pomocne w pobieraniu danych z pliku; niektóre z nich to int read(byte[] b), funkcja ta odczytuje dane ze strumienia wejściowego o długości do b.length bajtów. File Channel pobiera channel(): Konkretny obiekt File Channel podłączony do strumienia wejściowego pliku jest zwracany za jego pomocą. Finalize() służy do zapewnienia, że funkcja close() zostanie wywołana, gdy nie ma już odniesienia do strumienia wejściowego pliku.”
Przykład 01: Odczytywanie pojedynczego bajtu z pliku tekstowego przy użyciu metod read() i close() klasy strumienia wejściowego
W tym przykładzie użyto strumienia wejściowego pliku do odczytania pojedynczego znaku i wydrukowania zawartości. Załóżmy, że mamy plik o nazwie „file.txt” o treści pokazanej poniżej:

Załóżmy, że mamy plik o nazwie „file.txt” z zawartością pokazaną powyżej. Spróbujmy teraz odczytać i wydrukować pierwszy znak pliku.
Najpierw musimy zaimportować java.io. Pakiet File Input Stream w celu skonstruowania pliku wejściowego strumienia. Następnie utworzymy nowy obiekt File Input Stream, który zostanie połączony z plikiem określonym (plik.txt) w zmiennej „f”.
W tym przykładzie użyjemy metody „int read()” klasy Java File Input Stream, która służy do odczytania pojedynczego bajtu z pliku i zapisania go w zmiennej „I”. Następnie „System.out.print(char(i))” wyświetla znak odpowiadający temu bajtowi.
Metoda f.close() zamyka plik i strumień. Po zbudowaniu i uruchomieniu powyższego skryptu uzyskamy następujące dane wyjściowe, ponieważ widzimy, że drukowana jest tylko początkowa litera tekstu „L”.

Przykład 02: Odczytywanie całej zawartości pliku tekstowego przy użyciu metod read() i close() klasy strumienia wejściowego
W tym przykładzie będziemy czytać i wyświetlać całą zawartość pliku tekstowego; jak pokazano niżej:
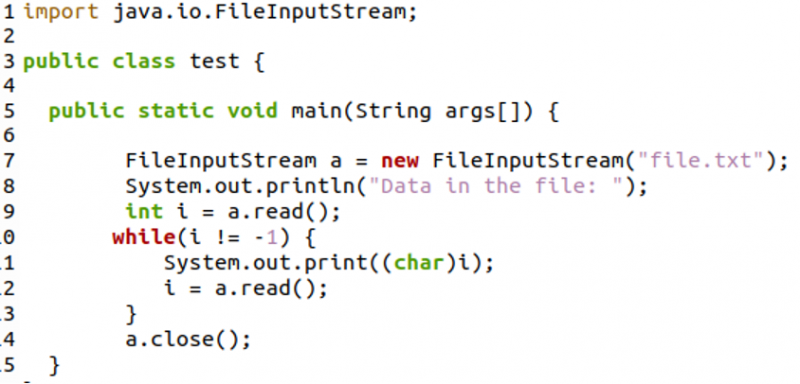
Po raz kolejny będziemy importować java.io. Pakiet File Input Stream w celu skonstruowania pliku wejściowego strumienia.
Najpierw odczytamy pierwszy bajt pliku i wyświetlimy odpowiedni znak wewnątrz pętli while. Pętla while będzie działała do momentu, gdy nie pozostaną żadne bajty, czyli do końca tekstu w pliku. Linia 12 odczyta następny bajt, a pętla będzie kontynuowana do ostatniego bajtu pliku.
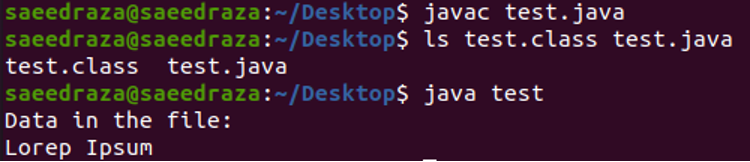
Po skompilowaniu i wykonaniu powyższego kodu otrzymamy następujące wyniki. Jak widzimy, cały tekst pliku „Lorep Ipsum” jest wyświetlany w terminalu.
Przykład 03: Określanie liczby dostępnych bajtów w pliku tekstowym przy użyciu metody available() klasy strumienia wejściowego
W tym przykładzie użyjemy funkcji „available()” strumienia wejściowego pliku, aby określić liczbę istniejących bajtów w strumieniu wejściowym pliku.
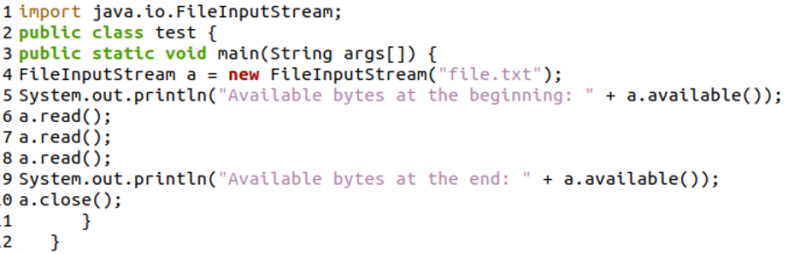
Najpierw wygenerowaliśmy obiekt klasy strumienia wejściowego pliku o nazwie „a” z następującym kodem. W wierszu 5 wykorzystaliśmy metodę „available()”, aby określić i wyświetlić całkowitą ilość dostępnych bajtów w pliku. Następnie od linii 6 do linii 8 trzykrotnie użyliśmy funkcji „read()”. Teraz w wierszu 9 ponownie użyliśmy metody „available()”, aby sprawdzić i wyświetlić pozostałe bajty.
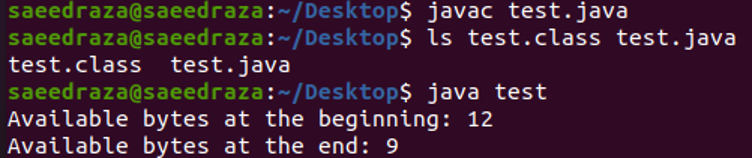
Po skompilowaniu i uruchomieniu kodu widzimy, że pierwsza linia danych wyjściowych pokazuje całkowitą liczbę dostępnych bajtów w pliku. Kolejny wiersz pokazuje liczbę bajtów dostępnych na końcu kodu, czyli o 3 mniej niż bajty dostępne na początku. Dzieje się tak, ponieważ trzykrotnie użyliśmy metody read w naszym kodzie.
Przykład 04: Pomijanie bajtów pliku tekstowego w celu odczytania danych z określonego punktu przy użyciu metody skip() klasy strumienia wejściowego
W tym przykładzie użyjemy metody „skip(x)” strumienia wejściowego pliku, która służy do ignorowania i ignorowania podanej liczby bajtów danych ze strumienia wejściowego.
W poniższym kodzie najpierw utworzyliśmy strumień wejściowy pliku i zapisaliśmy go w zmiennej „a”. Następnie użyliśmy metody „a.skip(5)”, która pomija pierwsze 5 bajtów pliku. Następnie wydrukowaliśmy pozostałe znaki pliku za pomocą metody „read()” wewnątrz pętli while. Na koniec zamknęliśmy strumień wejściowy pliku metodą „close()”.
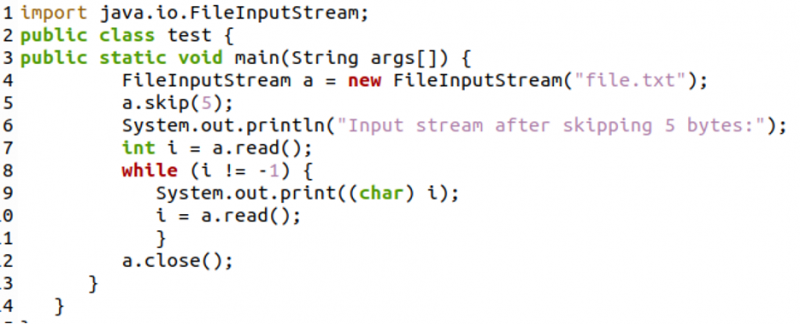
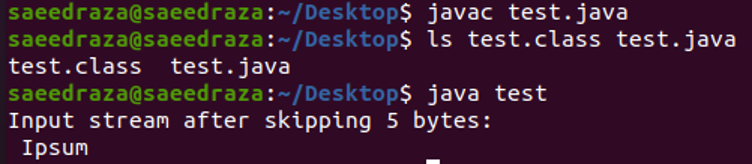
Poniżej zrzut ekranu terminala po skompilowaniu i uruchomieniu kodu. Jak widać, wyświetlane jest tylko „Ipsum”, ponieważ pominęliśmy pierwsze 5 bajtów za pomocą metody „skip()”.
Wniosek
W tym artykule omówiliśmy zastosowania klasy File Input Stream i jej różne metody; read(), available(), skip() i close(). Użyliśmy tych metod do odczytania pierwszego elementu pliku za pomocą metod read() i close(). Następnie odczytujemy cały plik metodą iteracyjną i tymi samymi metodami. Następnie użyliśmy metody available() do określenia liczby bajtów obecnych na początku i na końcu pliku. Następnie użyliśmy metody skip(), aby pominąć kilka bajtów przed odczytaniem pliku, co pozwoliło nam uzyskać określone dane, których potrzebowaliśmy.