Zrozumienie sekwencji ucieczki
Sekwencje ucieczki w C++ pozwalają, aby znaki wykonujące funkcje kontrolne w ciągu znaków były częścią tekstu bez pomylenia ich z kodem. Częstą pułapką dla początkujących jest zamieszanie związane z umieszczaniem cudzysłowów w dosłownym ciągu znaków. Na przykład następujący wiersz kodu spowoduje błąd kompilacji, ponieważ cudzysłowy wokół „sekwencji ucieczki \t” przedwcześnie kończą ciąg znaków:
ciąg tekstowy = „Ten artykuł dotyczy zbadania” \T sekwencja ucieczki” za pomocą przykładów.” ;Aby to naprawić w programie C++, użyjemy ukośnika odwrotnego „\” jako znaku ucieczki, aby zasygnalizować kompilatorowi, że następujący znak ma specjalną interpretację. Oto jak to się robi:
ciąg tekstowy = „Ten artykuł dotyczy odkrywania\” \\ t sekwencja ucieczki\” za pomocą przykładów.” ;
Zagłębianie się w znak specjalny (\t) w C++
Sekwencja „\t” to coś więcej niż tylko narzędzie do rozmieszczania odstępów. Reprezentuje znak tabulacji, który powoduje przesunięcie kursora do następnego tabulatora. Jest to szczególnie przydatne przy tworzeniu starannie sformatowanych wyświetlaczy tekstowych w aplikacjach terminalowych. Poza „\t” C++ obsługuje różne sekwencje specjalne do różnych celów — na przykład „\n” tworzy nową linię. Jednak w tym artykule skupimy się wyłącznie na sekwencji ucieczki „\t” w C++, podając przykłady ilustrujące jej cel i zastosowanie. Dzięki temu zdobędziesz wiedzę niezbędną do efektywnego wykorzystania poziomej zakładki w zadaniach programistycznych. Przejdźmy do przykładów, aby zrozumieć działanie sekwencji ucieczki „\t” w programie C++.
Przykład 1:
Poniższy przykład kodu C++ zawiera prosty program używany do drukowania tekstu na konsoli. Zapoznaj się z poniższym kodem, a my wyjaśnimy to później:
#include
używając przestrzeni nazw std ;
wew główny ( ) {
cout << „To jest pierwsza linijka tekstu”. << koniec ;
cout << „To jest druga linijka tekstu. \T ' ;
cout << „Po tej linii następuje a \\ sekwencja ucieczki.” ;
powrót 0 ;
}
Oto szczegóły każdej części kodu:
#include
używając przestrzeni nazw std; – Ten kod pozwala używać nazw zawartych w bibliotece standardowej bez poprzedzania ich „std::”. Na przykład możesz napisać „cout” zamiast „std::cout”.
int główna() { – To jest deklaracja i punkt wejścia głównej funkcji każdego programu C++. „int” przed „main” zazwyczaj wskazuje, że funkcja zwraca wartość całkowitą.
cout << „To jest pierwsza linijka tekstu.” <
cout << „To jest druga linijka tekstu.\t”; – W tym przypadku program wyświetla kolejny ciąg znaków: „To jest druga linia tekstu.\t”. Zwróć uwagę na „\t” na końcu. Po wydrukowaniu na konsoli dodaje poziomą spację tabulacji zaraz po tekście.
cout << „Po tej linii następuje sekwencja ucieczki \\t.”; – W tej linii program wypisuje: „Po tej linii następuje sekwencja ucieczki \t.”. Sekwencja ucieczki „\\t” jest używana do dosłownego włączenia „\t” do wyniku, ponieważ ukośnik odwrotny „\” sam w sobie jest znakowany przez inny ukośnik odwrotny, tak że zamiast poziomej tabulacji drukowane jest samo „\t”.
zwróć 0; – Oznacza to koniec funkcji głównej i zwraca zero, co oznacza pomyślne wykonanie programu. Po uruchomieniu tego programu dane wyjściowe wyglądają następująco:

Przykład 2:
Teraz spójrzmy na inny przykład i zobaczmy magię znaku ucieczki „\t”. Przykładem jest prosty program w języku C++, który zawiera standardową bibliotekę strumieni wejścia-wyjścia i korzysta ze standardowej przestrzeni nazw. Program przeznaczony jest do drukowania na konsoli sformatowanej tabeli nazw oraz skojarzonych z nimi miast i krajów.
#includeużywając przestrzeni nazw std ;
wew główny ( ) {
cout << 'Nazwa \T | \T Miasto \T | \T Kraj' << koniec ;
cout << '-----------------------------------------' << koniec ;
cout << „Alicja \T | \T Pekin \T | \T Chiny' << koniec ;
cout << 'Pion \T | \T Austina \T | \T Ameryka' << koniec ;
cout << „Kate \T | \T Paryż \T | \T Francja' << koniec ;
cout << „Dawid \T | \T Durbanie \T | \T Afryka Południowa' << koniec ;
cout << '-----------------------------------------' << koniec ;
powrót 0 ;
}
Oto podział kodu:
Ponownie, #include
używając przestrzeni nazw std; – Pozwala na wykorzystanie encji z przestrzeni nazw „std” bez konieczności poprzedzania ich „std::”.
The int główna() { jest punktem wejścia każdego programu C++. Po uruchomieniu programu wykonanie rozpoczyna się od tego miejsca.
W ramach funkcji main mamy:
cout << „Nazwa\t|\tMiasto\t|\tKraj”<
cout << „——————————————-„<
Każda z kolejnych czterech linii cout drukuje wiersz tabeli. Linie te mają ten sam format co tabulatory i są częścią tworzenia wyników tabeli. Po każdej linii danych, „endl” służy do przejścia do następnej linii. Ostatnia linia cout ponownie drukuje linię oddzielającą, aby wskazać koniec danych w tabeli.
zwróć 0;: – Ta linia oznacza pomyślne wykonanie programu. Wartość zwracana 0 oznacza sukces.
Po skompilowaniu i uruchomieniu tego programu dane wyjściowe pojawią się na konsoli w postaci tabeli z nazwiskami osób, miastami i krajami, uporządkowanymi w kolumnach oddzielonych pionowymi kreskami (|) i tabulatorami. Zobacz następujące dane wyjściowe:
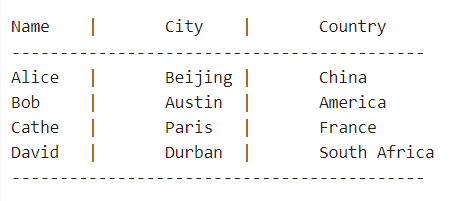
Notatka: Pamiętaj, że faktyczne wyrównanie tekstu w konsoli zależy od szerokości ustawień karty w konsoli lub terminalu, co może skutkować różnym wyglądem tabeli w różnych systemach.
Przykład 3:
Ten prosty, ale interesujący program w języku C++ wykorzystuje sekwencje specjalne tabulatora „\t” do drukowania kształtu rombu na ekranie. Ten kod skaluje rozmiar rombu w oparciu o zmienną „diament”, która określa rozmiar i reprezentuje liczbę linii od środka rombu do jego góry lub dołu. Sprawdź następujący podany kod:
#includeużywając przestrzeni nazw std ;
wew główny ( ) {
wew diament = 3 ;
Do ( wew I = 1 ; I <= diament ; ++ I ) {
Do ( wew J = 0 ; J < diament - I ; ++ J ) {
cout << ' \T ' ;
}
Do ( wew J = 0 ; J < 2 * I - 1 ; ++ J ) {
cout << „* \T ' ; }
cout << koniec ;
}
Do ( wew I = diament - 1 ; I >= 1 ; -- I ) {
Do ( wew J = 0 ; J < diament - I ; ++ J ) {
cout << ' \T ' ;
}
Do ( wew J = 0 ; J < 2 * I - 1 ; ++ J ) {
cout << „* \T ' ; }
cout << koniec ;
}
powrót 0 ;
}
Jak widać, program ten składa się z dwóch części: jedna drukuje górną połowę rombu, a druga drukuje dolną połowę. Górna połowa rombu jest drukowana poprzez wydrukowanie najpierw malejącej liczby zakładek w celu utworzenia wcięcia, po których następuje rosnąca liczba gwiazdek „*”, oddzielonych tabulatorami. Jest to obsługiwane w ramach pierwszej pętli „for”.
Dolna połowa jest drukowana podobnie, ale z pętlami powtarzającymi się w odwrotnej kolejności, aby zmniejszyć liczbę gwiazdek i ponownie zwiększyć wcięcie, tworząc dolną połowę rombu. Jest to obsługiwane w drugiej pętli „for”.
Podczas uruchamiania programu z „diamentem = 3” wynik wygląda jak romb, który jest wyśrodkowany na ekranie ze względu na znaki tabulacji. Zobacz wynik tego konkretnego programu:

Należy pamiętać, że rzeczywisty wygląd może się różnić w zależności od używanej konsoli lub terminala, ponieważ szerokość zakładek może się różnić.
Wniosek
Sekwencje ucieczki w C++ są potężnym narzędziem do reprezentowania znaków, których nie można łatwo wyświetlić w standardowym oknie wyjściowym. Wśród tych sekwencji, tabulator poziomy, oznaczony jako „\t”, jest szczególnie przydatny do dodawania kontrolowanych odstępów poziomych w tekście. Używając „\t”, programiści mogą wyrównać swój tekst, poprawić czytelność i systematycznie porządkować dane. Znak ten imituje naciśnięcie klawisza „tab” na klawiaturze, przesuwając kursor do następnej pozycji tabulatora. W tym artykule zbadaliśmy funkcjonalność sekwencji ucieczki „\t” w języku C++, podkreślając jej zastosowanie za pomocą prostych i praktycznych przykładów ilustrujących jej zachowanie.