Elasticsearch to solidne, popularne rozwiązanie do przechowywania nieporęcznych, nieustrukturyzowanych i półstrukturalnych danych. Jest to czysto baza danych NoSQL i wykorzystuje zupełnie inne podejście do przechowywania, zarządzania i pobierania danych. Przechowuje dane w dokumencie w formacie JSON i używa pozostałych interfejsów API do wykonywania różnych operacji na przechowywanych danych.
Na tym blogu pokażemy:
- Jak Elasticsearch przechowuje i przeszukuje dane?
- Czym są dokumenty Elasticsearch?
- Jak przechowywać dane w dokumencie Elasticsearch?
Jak Elasticsearch przechowuje i przeszukuje dane?
Poniżej wymieniono główne komponenty lub hierarchię Elasticsearch używaną do przechowywania danych:
- Dokument: Dokument jest główną częścią Elasticsearch przechowującą dane w formacie JSON. Tak jak
- Indeksy: Indeksy są nazywane indeksami. Jest to zbiór dokumentów. Podobnie jak w SQL, jest określany jako baza danych.
- Indeksy odwrócone: Obsługuje bardzo szybkie wyszukiwanie pełnotekstowe. Przechowuje słowo jako indeks, a nazwę dokumentu jako odniesienie.
Czym są dokumenty Elasticsearch?
Dokument Elasticsearch jest jednostką przechowywania danych w formacie JSON. Podobnie jak w przypadku relacyjnych baz danych, dokument można nazwać tabelą lub wierszem bazy danych, który jest przechowywany w jakimś indeksie. Indeks może zawierać wiele dokumentów i jest określany jako baza danych zawierająca wiele tabel. Zwykle przechowuje złożoną strukturę danych i sterylizuje dane w formacie JSON.
Ponadto każdy dokument może zawierać wiele pól, które są „ kluczowa wartość ” parami do przechowywania danych, tak jak tabela ma wiele kolumn lub pól w relacyjnej bazie danych. Następnie te pary klucz-wartość mają zostać zindeksowane w taki sposób, aby określić mapowanie dokumentu. Następnie mapowanie definiuje typ danych dokumentu zgodnie z danymi pola, takimi jak tekst, liczba zmiennoprzecinkowa, punkt geograficzny, czas i wiele innych.
Elasticsearch nigdy nie zobowiązał nas do wstępnego zdefiniowania struktury pól indeksu, a dokumenty mogą mieć inną strukturę pól w indeksie. Jeśli jednak mapowanie pola jest zdefiniowane dla określonego typu danych, wszystkie dokumenty Elasticsearch w indeksie muszą być zgodne z tym samym typem mapowania. Aby sprawdzić działanie dokumentu do przechowywania danych w Elasticsearch, przejdź do następnej sekcji.
Jak przechowywać dane w dokumencie Elasticsearch?
Aby przechowywać dane w Elasticsearch, użytkownik musi najpierw utworzyć indeks. Następnie określ pola do przechowywania danych w dokumencie Elasticsearch. Aby przeprowadzić demonstrację, wykonaj wymienione kroki.
Krok 1: Uruchom Elasticsearch
Aby uruchomić bazę danych lub silnik Elasticsearch w systemie, uruchom terminal systemowy, taki jak Command Prompt. Następnie odwiedź „ kosz ” folder Elasticsearch przez „ płyta CD ' Komenda:
płyta CD C:\Users\Dell\Documents\Elk stos\elasticsearch-8.7.0\bin
Następnie uruchom plik wsadowy Elasticsearch, aby uruchomić bazę danych w systemie:
Elasticsearch.bat
Krok 2: Uruchom Kibanę
Następnie uruchom Kibana w systemie. Aby to zrobić, odwiedź jego „ kosz ” z wiersza polecenia:
płyta CD C:\Users\Dell\Documents\Elk stos\kibana-8.7.0\bin
Następnie uruchom poniższe polecenie, aby rozpocząć wykonywanie Kibany:
kibana.bat
Notatka: Jeśli nie zainstalowałeś i nie skonfigurowałeś Elasticsearch i Kibana w systemie, przejdź do naszych postów i sprawdź procedurę krok po kroku, aby zainstalować je w systemie.
Aby zapoznać się z Elasticsearch, odwiedź naszą „ Zainstaluj i skonfiguruj Elasticsearch za pomocą .zip w systemie Windows ” artykuł. Aby skonfigurować Kibanę w systemie Windows, postępuj zgodnie z „ Skonfiguruj Kibana dla Elasticsearch ” artykuł.
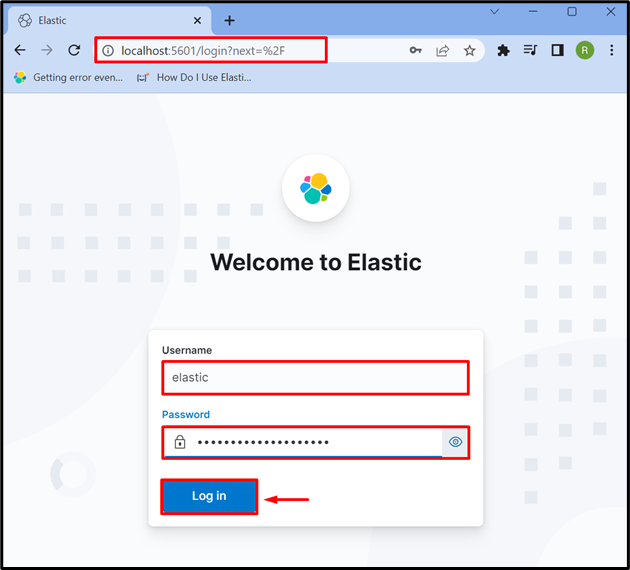
Krok 3: Zaloguj się do Kibany
Po uruchomieniu Kibany w systemie przejdź do domyślnego adresu Kibana „ lokalny host:5601 ” w przeglądarce i podaj dane logowania do Elasticsearch, takie jak „ elastyczny ”użytkownik i hasło. Następnie naciśnij „ Zaloguj sie ' przycisk:
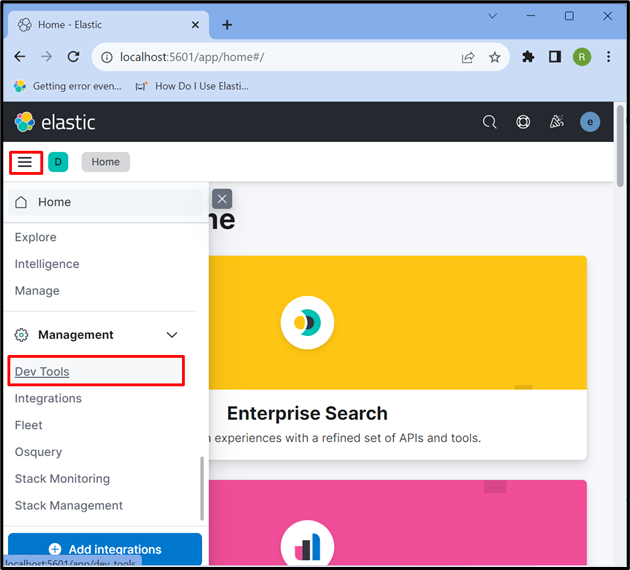
Krok 4: Otwórz „Narzędzie deweloperskie” Kibany
Następnie kliknij „ Trzy poziome paski ” i otwórz Kibana „ Narzędzie deweloperskie ”, aby używać interfejsów API do przechowywania, pobierania i aktualizowania danych:
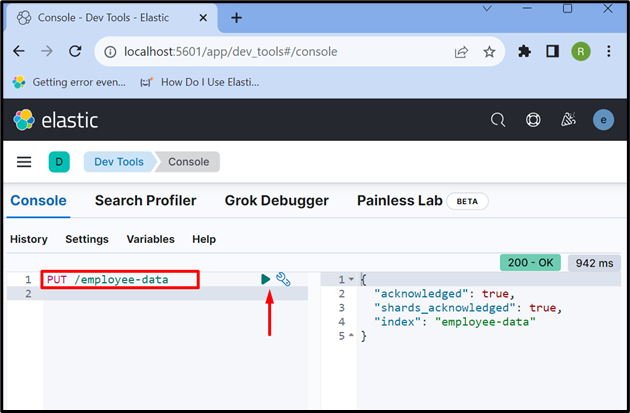
Krok 5: Utwórz indeks
Teraz utwórz nowy indeks, używając „ PUT /
Dane wyjściowe pokazują, że „ dane pracownika ” indeks został pomyślnie utworzony:
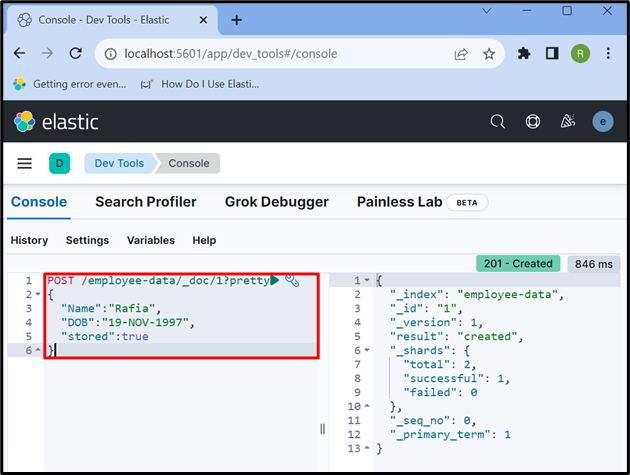
Krok 6: Wstaw dane do dokumentu
Teraz użyj „ POST ” API do przechowywania danych w indeksie. W poniższym żądaniu „ dane pracownika ” to indeks Elasticsearch, „ _doc ” służy do przechowywania danych w dokumencie Elasticsearch, a „ 1 ” to identyfikator:
POST / dane pracownika / _doc / 1 ?ładny{
'Nazwa' : 'Rafia' ,
„DOB” : „19-listopad-1997” ,
„przechowywane” :PRAWDA
}
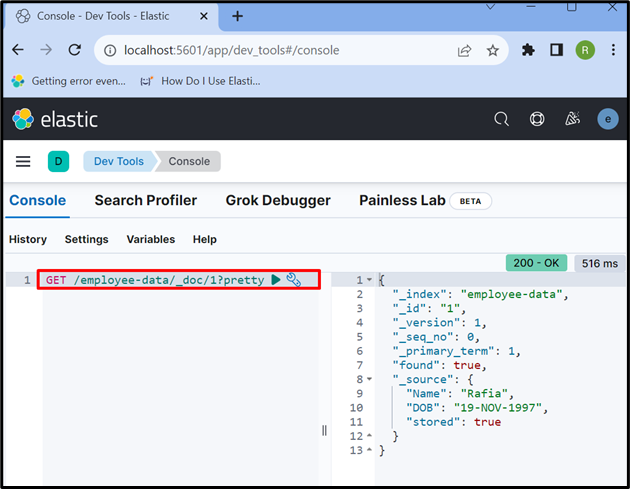
Krok 7: Pobierz dane z dokumentu Elasticsearch
Aby uzyskać dostęp do danych z indeksu lub dokumentu Elasticsearch, użyj „ DOSTAWAĆ ” Interfejs API używany poniżej:
DOSTAWAĆ / dane pracownika / _doc / 1 ?ładny
Dane wyjściowe pokazują, że pomyślnie wyodrębniliśmy dane z dokumentu Elasticsearch o identyfikatorze „ 1 ”:
To wszystko o dokumencie Elasticsearch.
Wniosek
Dokument Elasticsearch jest zwykle używany do przechowywania danych w formacie JSON. Podobnie jak w relacyjnych bazach danych, dokument można nazwać wierszem, który jest przechowywany w jakimś indeksie. Te indeksy mogą zawierać wiele dokumentów, tak jak bazy danych mają różne tabele. Dokumenty te zawierają wiele pól, które są „ kluczowa wartość ” pary do przechowywania danych. W tym artykule pokazano, czym są dokumenty Elasticsearch i jak działają w Elasticsearch.