Czasami danego zestawu danych nie ma w jednym pliku CSV. Wszystkie znajdują się w różnych arkuszach Excela. Wiesz już, że lepiej jest wykonywać wszystkie działania obliczeniowe lub wstępne przetwarzanie na jednym zbiorze danych zamiast kilku zestawów danych. Zmniejsza lub oszczędza czas, który musimy poświęcić na zadania związane z przetwarzaniem wstępnym. Ponadto, jako analityk danych lub naukowiec danych, często możesz być przeciążony licznymi plikami CSV, które należy scalić, zanim jeszcze rozpoczniesz analizę lub badanie dostępnych danych. Z drugiej strony nie zawsze jest możliwe, aby wszystkie pliki pochodziły z jednego lub tego samego źródła danych i miały te same nazwy kolumn/zmiennych oraz strukturę danych. Ten post nauczy Cię łączenia dwóch lub więcej plików CSV o podobnej lub innej strukturze kolumn.
Dlaczego warto łączyć pliki CSV?
Zbiór danych może być zbiorem lub grupą wartości lub liczb związanych z określonym tematem. Na przykład wyniki testu każdego ucznia w określonej klasie są przykładem zbioru danych. Ze względu na rozmiar dużych zbiorów danych często są one przechowywane w osobnych plikach CSV dla różnych kategorii. Na przykład, jeśli mamy zbadać pacjenta pod kątem określonej choroby, musimy wziąć pod uwagę każdy składnik, w tym jego płeć, historię medyczną, wiek, ciężkość choroby itp. W związku z tym wymagane jest połączenie danych CSV w celu zbadania różnych czynników wpływających na predyktory aspekty. Ponadto lepiej jest pracować i zarządzać pojedynczym zestawem danych niż kilkoma zestawami danych podczas wykonywania zadań obliczeniowych lub przetwarzania wstępnego. Oszczędza pamięć i inne zasoby obliczeniowe
Jak łączyć pliki CSV w Pythonie?
Istnieje wiele sposobów i metod łączenia dwóch lub więcej plików CSV w Pythonie. W poniższej sekcji użyjemy funkcji append(), concat() i merge() itp. do łączenia plików CSV w ramkę danych pandas, a następnie ramki danych zostaną przekonwertowane na pojedynczy plik CSV. Nauczymy łączyć wiele plików CSV o podobnej lub zmiennej strukturze kolumn.
Metoda nr 1: Łączenie plików CSV z podobnymi strukturami lub kolumnami
Nasz bieżący katalog roboczy zawiera dwa pliki CSV, „test1” i „test2”.
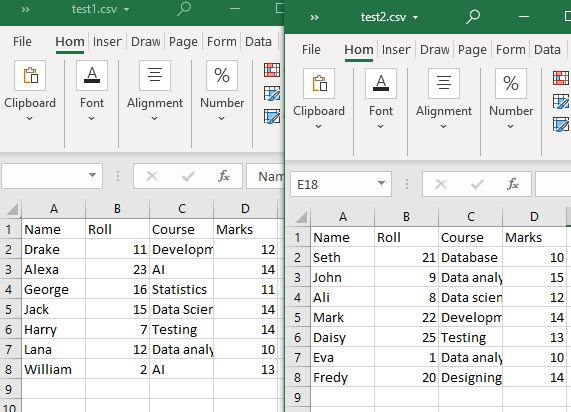
Przykład nr 1: Użycie funkcji append().
Oba pliki CSV mają tę samą strukturę. Funkcja glob() zostanie użyta w tej metodzie do wyświetlenia tylko plików CSV w katalogu roboczym. Następnie użyjemy „pandas.DataFrame.append()” do odczytania naszych plików CSV (ze wspólną strukturą tabelaryczną).

Wyjście:
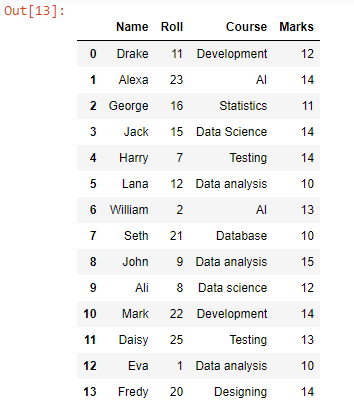
Za pomocą funkcji append dodaliśmy lub dodaliśmy każdy wiersz danych z pliku test2.csv pod wierszami danych pliku test1.csv, ponieważ widać, że wszystkie wiersze danych w pliku zostały połączone. Aby przekonwertować tę ramkę danych na CSV, możemy użyć funkcji to_csv().

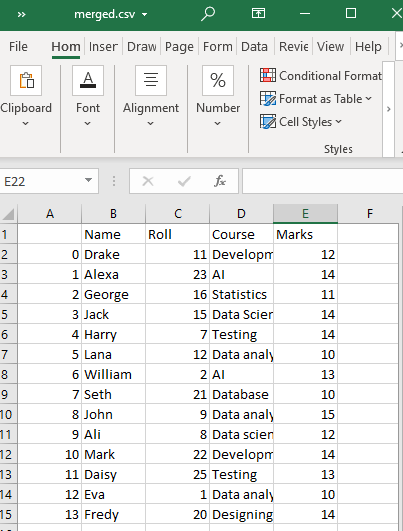
Spowoduje to utworzenie połączonego pliku CSV z plików CSV „test1” i „test2” w naszym katalogu roboczym o określonej nazwie, tj. merged.csv.
Przykład nr 2: Użycie funkcji concat().
Najpierw zaimportujemy moduł pandas. Metoda map odczyta każdy przekazany przez nas plik CSV za pomocą pd.read_csv(). Te zmapowane pliki (pliki CSV) zostaną następnie domyślnie połączone wzdłuż osi wiersza przy użyciu funkcji pd.concat(). Jeśli chcemy łączyć pliki CSV w poziomie, możemy przekazać oś=1. Określenie indeksu ignorowania = True tworzy również ciągłe wartości indeksu dla połączonej ramki danych.

Funkcja pd.read_csv() jest przekazywana wewnątrz funkcji concat() w celu odczytania plików CSV do ramki danych pandas po konkatenacji.
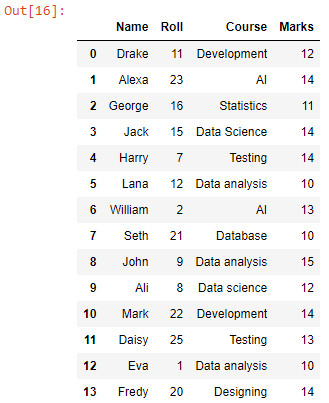
Otrzymaliśmy ramkę danych z połączonymi danymi wszystkich plików CSV w katalogu roboczym. Teraz przekonwertujmy go na plik CSV.
Nasz połączony plik CSV jest tworzony w bieżącym katalogu.
Metoda nr 2: Łączenie plików CSV z różnymi strukturami lub kolumnami
Omówiliśmy łączenie plików CSV z tymi samymi kolumnami i strukturą w pierwszej metodzie. W tej metodzie połączymy pliki CSV z różnymi kolumnami i strukturami.
Przykład nr 1: Użycie funkcji merge().
Funkcja „pandas.merge()” w module pandas może łączyć dwa pliki CSV. Scalanie odnosi się po prostu do łączenia dwóch zestawów danych w jeden zestaw danych na podstawie wspólnych kolumn lub atrybutów.
Ramki danych możemy łączyć na cztery różne sposoby:
- Wewnętrzny
- Prawidłowy
- Lewy
- Zewnętrzny
Aby wykonać tego typu scalanie, użyjemy dwóch plików CSV.
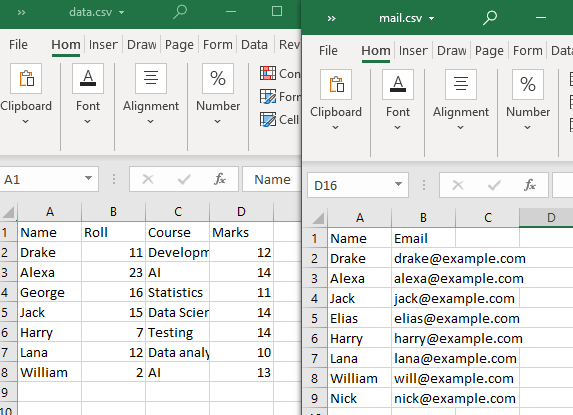
Pamiętaj, że co najmniej jeden atrybut lub kolumna muszą być wspólne dla obu plików CSV. Jak zaobserwowano, kolumna „Nazwa” i niektóre jej atrybuty są wspólne dla obu plików CSV.
Połącz za pomocą połączenia wewnętrznego
Określenie parametru how=’inner’ w funkcji merge() spowoduje połączenie dwóch ramek danych zgodnie z określoną kolumną, a następnie udostępni nową ramkę danych zawierającą tylko wiersze z identycznymi/takimi samymi wartościami w obu oryginalnych ramkach danych.
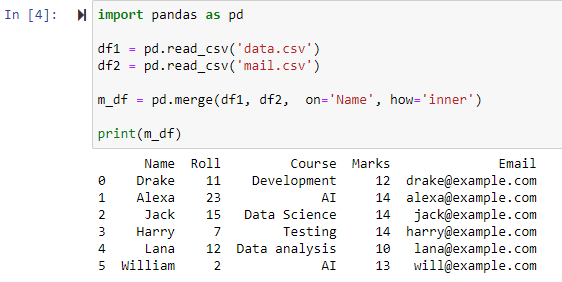
Jak widać, funkcja scaliła oba pliki CSV i zwróciła wiersze na podstawie wspólnych atrybutów kolumny „Nazwa”.
Scal przy użyciu prawego łączenia zewnętrznego
Po określeniu parametru how=’right’ obie ramki danych zostaną połączone na podstawie kolumny, którą określiliśmy dla parametru ‘on’. Zwrócona zostanie nowa ramka danych zawierająca wszystkie wiersze z prawej ramki danych, w tym wszystkie wiersze, dla których lewa ramka danych nie zawiera żadnych wartości, z wartością kolumny lewej ramki danych ustawioną na NAN.
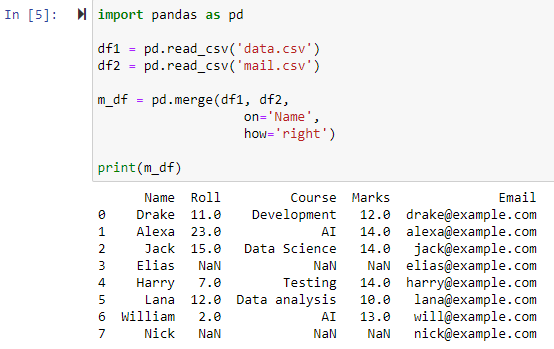
Połącz za pomocą lewego łączenia zewnętrznego
Gdy parametr zostanie określony jako „lewy”, dwie ramki danych zostaną połączone na podstawie określonej kolumny przy użyciu parametru „on”, zwracając nową ramkę danych, która zawiera wszystkie wiersze z lewej ramki danych, a także wszystkie wiersze, które mają NAN lub wartości null w prawej ramce danych i ustawia wartość kolumny prawej ramki danych na NAN.
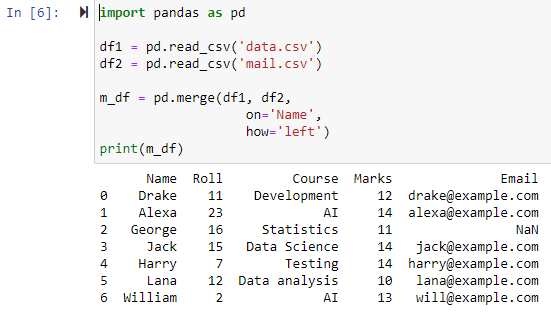
Scal przy użyciu pełnego łączenia zewnętrznego
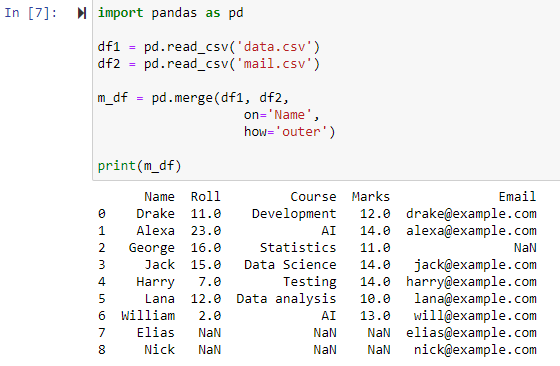
Po określeniu how='outer' dwie ramki danych zostaną połączone w zależności od kolumny określonej dla parametru „on”, zwracając nową ramkę danych zawierającą wiersze z obu ramek danych df1 i df2 oraz ustawiając NAN jako wartość dla dowolnych wierszy dla którego brakuje danych w jednej z ramek danych.
Przykład nr 2: Łączenie wszystkich plików CSV w katalogu roboczym
W tej metodzie użyjemy modułu glob do połączenia wszystkich plików .csv w pandas DataFrame. Wszystkie biblioteki musiały zostać najpierw zaimportowane. Następnie ustawimy ścieżkę dla każdego pliku CSV, który chcemy połączyć. Ścieżka do pliku jest pierwszym argumentem funkcji os.path.join() w poniższym przykładzie, a drugim argumentem są komponenty ścieżki lub pliki .csv, które mają zostać połączone. W tym przypadku wyrażenie „*.csv” znajdzie i zwróci każdy plik w katalogu roboczym, który kończy się rozszerzeniem pliku .csv. Funkcja glob.glob(files join) przyjmuje jako dane wejściowe listę nazw scalonych plików i wyświetla listę wszystkich scalonych/połączonych plików.
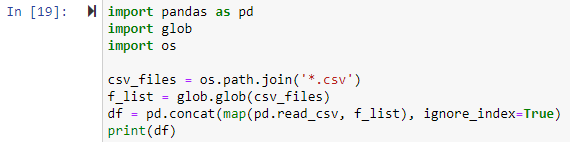
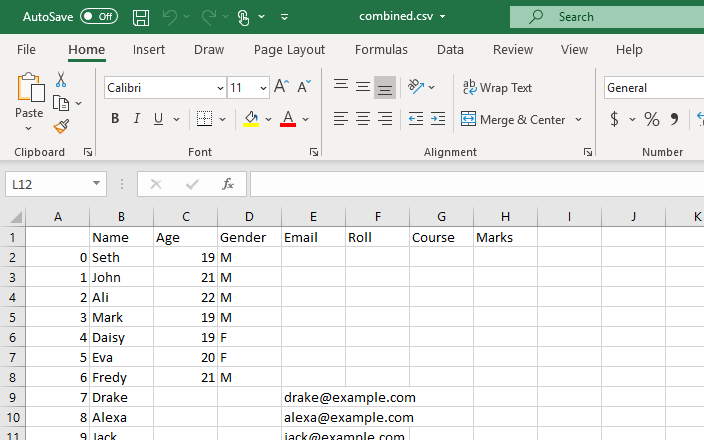
Ten skrypt zwróci ramkę danych z połączonymi danymi wszystkich plików CSV w naszym katalogu roboczym.
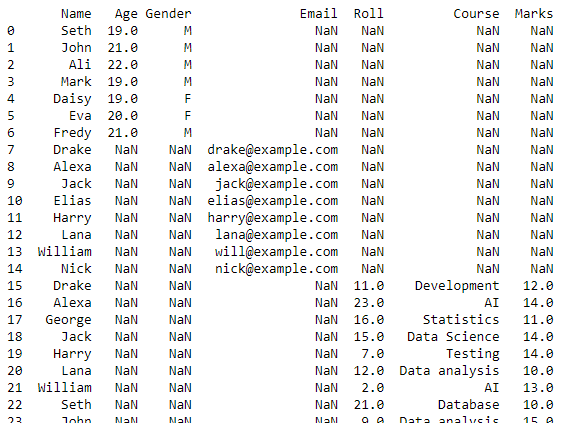
Ta ramka danych zostanie przekształcona w plik CSV, a do tej konwersji zostanie użyta funkcja to_csv(). Ten nowy plik CSV będzie połączonymi plikami CSV utworzonymi ze wszystkich plików CSV przechowywanych w bieżącym katalogu roboczym.
Wniosek
W tym poście omówiliśmy, dlaczego musimy łączyć pliki CSV. Omówiliśmy, w jaki sposób można połączyć dwa lub więcej plików CSV w Pythonie. Podzieliliśmy ten samouczek na dwie części. W pierwszej sekcji wyjaśniliśmy, jak używać funkcji append() i concat() do łączenia plików CSV o tej samej strukturze lub nazwach kolumn. W drugiej części wykorzystaliśmy metodę merge(), os.path.join() oraz metodę glob do łączenia plików CSV z różnymi kolumnami i strukturami.