„Pandas” to wysokowydajne narzędzie dla środowiska Pythona. Jest to „otwarty” kod źródłowy do analizy danych. Do łączenia dwóch ramek danych w jedną ramkę danych używa się łączenia pand i metody scalania pand. W obu metodach pand różnica polega na tym, że funkcja pandy „join” łączy ramkę danych za pomocą indeksu. Natomiast funkcja „scalania” pand łączy dataframe za pomocą indeksu i metody kolumn, w której sami możemy wybrać żądaną kolumnę. Metoda łączenia pand jest używana głównie w porównaniu do metody łączenia pand. Oprogramowanie, którego będziemy używać do implementacji, to oprogramowanie „spyder”, które znajduje się w środowisku pythona, które zapewni nam korzyści w zakresie implementacji kodu metody pandas join() i funkcji metody pandas merge().
Składnia metody Pandy Join()
„df1. Przystąp ( df2 ) ”„df” w powyższej składni to skrót od „dataframe”. W składni są dwie ramki danych z funkcją „dot join”, która służy do wywoływania metody. Jest to metoda pandy łączenia dwóch ramek danych. Działa przy użyciu indeksu do łączenia ramek danych w jedną.
Składnia metody Pandy Merge()
„df1. łączyć ( df2 , na = 'Nazwa kolumny' ) ”Składnia metody scalania pandy ma dwie ramki danych jako „df1” i „df2”. Funkcja „dot merge” wywołuje metodę łączenia obu dataframe z wyglądem odwróconych kolumn.
Omówimy następujące sposoby łączenia dwóch ramek danych w celu wykorzystania metod łączenia pandy i łączenia pandy:
- Metoda Pandas Join nakłada się na siebie.
- Pandy dołączają do metody przy użyciu resetowania indeksu.
- Metoda scalania Pand (kolumna „lewa i prawa”).
- Pandy łączą metodę jawną.
Tworzenie ramek danych do implementacji metody Pand Merge i Pandas Join
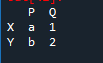
Najpierw musimy stworzyć ramkę danych. W tym celu użyjemy narzędzia „spyder”. Po jego otwarciu zacznij pisać kod. Importuj pandy jako „pd” dla stowarzyszenia bibliotecznego pandy. Mamy zmienne dataframe jako odpowiednio „x”, „y”, „p” i „q” oraz „a” z wartościami „1” i „b” z wartością przypisaną jako „2”.

Wyjście to „df” utworzone z przypisanymi wartościami. Możemy uczynić go tak dużym, jak dane.
Tworzenie kolejnej ramki danych
Musimy stworzyć kolejną ramkę danych, aby jasno zrozumieć metody łączenia pand i łączenia pand. Tutaj mamy „df” utworzone tak samo jak powyższy „df”, tylko wartości przypisane do zmiennych są różne. Mamy „h”, „j”, „s” i „d”, natomiast wartości „b” przypisujemy do wartości „8” i „Y” do wartości „3”.

Dane wyjściowe pokazują utworzone proste „df”.

Przykład nr 01: Metoda łączenia Pand (nakładanie się)
Teraz zobaczymy, jak połączyć dwie ramki danych za pomocą metody łączenia pandy. W przypadku tej metody możemy wybrać z ramki danych wybraną przez Ciebie kolumnę, nad którą chcemy pracować. Wzięliśmy przykład z nakładającą się kolumną „po lewej” od „df”, więc możemy to naprawić za pomocą „sufiksu”, aby przezwyciężyć nakładanie się danych. Tutaj używane zmienne to „x”, „z”, „v”, „d”. „p”, „o”, „l” i „y” z wartościami przypisanymi jako „3”, „6”, „7” i „9”. „.join” wywołuje metodę, z wyrównaniem ustawionym na left join z prawym sufiksem „df”. ”. „Sufiks” użyty w kodzie wynika z tego, że w ramce danych znajdują się dwie kolumny o tej samej nazwie, która jest „kluczem”, i która nie będzie nakładać się na dane.
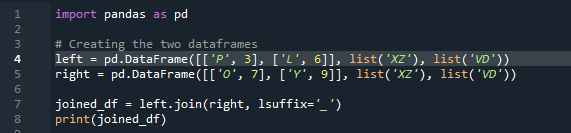
Dane wyjściowe nie zawierają nakładających się danych z metodą łączenia dwóch „df” za pomocą metody łączenia pandy.
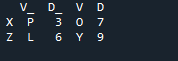
Przykład # 02: Metoda łączenia Pand za pomocą resetowania indeksu
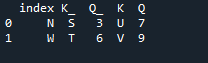
W tym przykładzie będziemy osobno określać kolumnę z parametrem „on”, która ma być używana jako „klucz” w metodzie join, która pomaga w łączeniu dwóch ramek danych. połączona rzecz jest wykonywana z tym parametrem. Również indeks jednego z dwóch „df” powinien być podobny, aby je połączyć. Podobne rodzaje danych lub dane wykorzystywane w tym samym celu mogą być przetwarzane razem. To będzie nadal używać indeksu, używając od prawej. Zmienne to „s”, „t”, „u”, „v”, „n”, „w”, „k” i „q”. Przypisane wartości to „3”, „6”, „7” i „9”. „Reset dot index” to metoda pand resetowania indeksu „df”. Indeks resetowania ustawia wszystkie liczby całkowite na liście ramki danych od 0 do czasu, gdy dane ramki danych zostaną wydłużone.
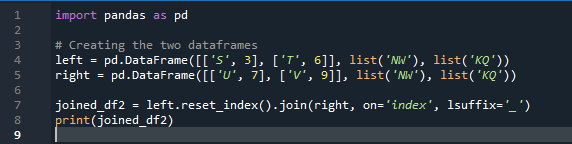
Oto dane wyjściowe wyświetlane przy użyciu metody łączenia „klucza” dla pand.
Przykład nr 03: Metoda łączenia Pand (kolumna „lewa i prawa”)
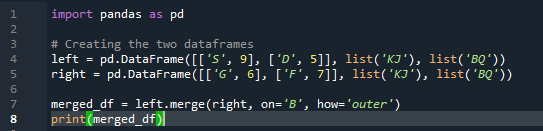
Metoda scalania wykonuje podobną operację jak metoda łączenia pand. Obie metody służą do łączenia danych w podobnej ramce danych. Metoda scalania jest bardziej wszechstronna i wymaga określenia klucza. Możemy również określić go w lewej i prawej kolumnie w zależności od pracy twojego dataframe. Zmienne w kodzie to „s”, „d”, „g”, „f”, „k”, „j”, „b” i „q”. przypisane wartości to „9”, „5”, „6” i „7”. Zewnętrzna implementacja „join” jest wykonywana na obu „df” za pomocą parametru „how” funkcji metody scalania pandy.
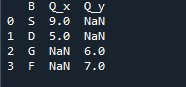
Dane wyjściowe, które widzimy, pokazują połączone dane dwóch ramek danych. „NaN” reprezentuje „nie jest liczbą”, co oznacza, że tam, gdzie nie ma przypisanej liczby w danych, pojawia się „NaN”.
Przykład nr 04: Metoda łączenia jawnie
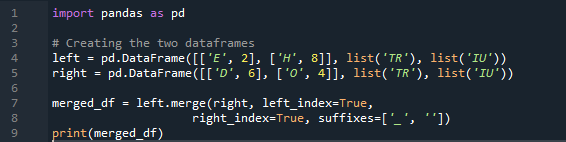
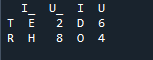
Tutaj, w tym przykładzie, metoda scalania polega na zniszczeniu indeksu, a wartość indeksu nie jest przyjmowana w ramce danych. Będziemy wykonywać tę metodę zgodnie z pracą, która musi zostać wykonana, gdzie wyraźne określenie ma być kontynuowane. Połączy dane na podstawie indeksu lewego lub indeksu prawego z parametrem. Zmienne w tej ramce danych to „t”, „r”, „I”, „u”, „h”, „o”, „e” i „e”. Przypisane wartości to „2”, „4”, „6” i „4”. Powyższy przykład metody scalania pand z wyborem kolumn w zależności od potrzeb jest najbardziej reprezentacyjną i wartościową metodą łączenia dwóch dataframe'ów. Sprawdzanie na końcu wiersza kodu, czy klucz scalania jest unikalny w zestawie danych.
Na poniższym wyjściu indeks nie jest pokazywany bez indeksu, ale funkcja jest wykonywana na podstawie prawego i lewego indeksu.
Wniosek
Obie metody merge() i join() są bardzo wygodnymi i skutecznymi metodami. Obie te funkcje są używane do łączenia dwóch oddzielnych ramek danych na tej samej ramce danych, ale mają różne zastosowanie w zależności od przypadku. W tym artykule poznaliśmy kluczowe różnice między metodą łączenia i łączenia pand. Po wykonaniu przykładów i zrozumieniu metody łączenia pand, zakończymy ją świadomością, że jeśli chcemy bardziej elastycznego łączenia w stylu bazy danych, lepiej jest skorzystać z metody łączenia pand. Z drugiej strony, jeśli chcemy obszernie połączyć ramkę danych z indeksem, możemy skorzystać z funkcji metody pandas join().