- Tłumaczenie obrazu
- Obrót obrazu
- Arytmetyka obrazu
- Przerzucanie obrazu
- Przycinanie obrazu
- Zmiana rozmiaru obrazu
Teraz szczegółowo wyjaśnimy wszystkie wyżej wymienione tematy związane z przetwarzaniem obrazu.
1. Tłumaczenie obrazu
Translacja obrazu to metoda przetwarzania obrazu, która pomaga nam przesuwać obraz wzdłuż osi x i y. Możemy przesuwać obraz w górę, w dół, w prawo, w lewo lub w dowolnej kombinacji.
Możemy zdefiniować macierz translacji za pomocą symbolu M i przedstawić ją w postaci matematycznej, jak pokazano poniżej:
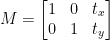
Dzięki temu programowi możemy zrozumieć koncepcję obrazu tłumaczenia.
Kod Pythona: Zachowamy nazwę następującego programu jako przetłumacz.py .
# importuj wymagane pakietyimport liczba Jak np
import argparse
import imutil
import cv2
# implementujemy parser argumentów
ap_obj = argparse. Analizator argumentów ( )
ap_obj. dodaj_argument ( '-k' , '--obraz' , wymagany = Prawdziwe ,
Wsparcie = „lokalizacja pliku obrazu” )
argumenty = którego ( ap_obj. parse_args ( ) )
# załaduj obraz i pokaż na ekranie
obraz = cv2. nieczytane ( argumenty [ 'obraz' ] )
cv2. pokaż ( 'Oryginalny obraz' , obraz )
# Tłumaczenie obrazu to macierz NumPy, która jest podana poniżej:
# [[1, 0, przesunięcieX], [0, 1, przesunięcieY]]
# Zamierzamy użyć powyższej macierzy NumPy do przesunięcia obrazów wzdłuż
# Kierunki osi x i osi y. W tym celu musimy po prostu przekazać wartości pikseli.
# W tym programie przesuniemy obraz o 30 pikseli w prawo
# i 70 pikseli w dół.
tłumaczenie_mat = np. pływak32 ( [ [ 1 , 0 , 30 ] , [ 0 , 1 , 70 ] ] )
tłumaczenie_obrazu = cv2. warpAffine ( obraz , tłumaczenie_mat ,
( obraz. kształtować się [ 1 ] , obraz. kształtować się [ 0 ] ) )
cv2. pokaż ( „Tłumaczenie obrazu w dół iw prawo” , tłumaczenie_obrazu )
# teraz użyjemy powyższej macierzy NumPy do przesunięcia obrazów wzdłuż
# Kierunki osi x (lewo) i osi y (góra).
# Tutaj przesuniemy obrazy o 50 pikseli w lewo
# i 90 pikseli w górę.
tłumaczenie_mat = np. pływak32 ( [ [ 1 , 0 , - pięćdziesiąt ] , [ 0 , 1 , - 90 ] ] )
tłumaczenie_obrazu = cv2. warpAffine ( obraz , tłumaczenie_mat ,
( obraz. kształtować się [ 1 ] , obraz. kształtować się [ 0 ] ) )
cv2. pokaż ( „Tłumaczenie obrazu w górę iw lewo” , tłumaczenie_obrazu )
cv2. czekaćKlucz ( 0 )
Linie od 1 do 5: Importujemy wszystkie wymagane pakiety dla tego programu, takie jak OpenCV, argparser i NumPy. Należy pamiętać, że istnieje inna biblioteka, którą jest imutils. To nie jest pakiet OpenCV. To tylko biblioteka, która z łatwością pokaże to samo przetwarzanie obrazu.
Biblioteka imutils nie zostanie dołączona automatycznie podczas instalacji OpenCV. Aby zainstalować imutils, musimy użyć następującej metody:
pip zainstaluj imutils
Wiersze od 8 do 15: Stworzyliśmy nasz agrparser i załadowaliśmy nasz obraz.
Wiersze od 24 do 25: W tej sekcji programu odbywa się tłumaczenie. Macierz translacji mówi nam, o ile pikseli obraz zostanie przesunięty w górę, w dół, w lewo lub w prawo. Ponieważ OpenCV wymaga, aby wartość macierzy była w tablicy zmiennoprzecinkowej, macierz translacji przyjmuje wartości w tablicach zmiennoprzecinkowych.
Pierwszy wiersz macierzy translacji wygląda następująco:
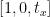
Ten wiersz macierzy dotyczy osi x. Wartość t x zadecyduje, czy obraz zostanie przesunięty w lewą, czy w prawą stronę. Jeśli podamy wartość ujemną, oznacza to, że obraz zostanie przesunięty na lewą stronę, a jeśli wartość jest dodatnia, oznacza to, że obraz zostanie przesunięty na prawą stronę.
Zdefiniujemy teraz drugi wiersz macierzy w następujący sposób:
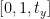
Ten wiersz macierzy dotyczy osi y. Wartość t Y zadecyduje, czy obraz zostanie przesunięty w górę, czy w dół. Jeśli przekażemy wartość ujemną, oznacza to, że obraz zostanie przesunięty w górę, a jeśli wartość jest dodatnia, oznacza to, że obraz zostanie przesunięty w dół.
W poprzednim programie w linii 24 definiujemy t x = 30 i t Y = 70. Przesuwamy więc obraz o 30 pikseli w prawą stronę io 70 pikseli w dół.
Ale główny proces translacji obrazu odbywa się w linii 25, gdzie definiujemy macierz translacji cv2.warpAffine . W tej funkcji przekazujemy trzy parametry: pierwszym parametrem jest obraz, drugim parametrem jest macierz translacji, a trzecim parametrem jest wymiar obrazu.
Linia 27: Linia 27 wyświetli wynik na wyjściu.
Teraz zaimplementujemy kolejną macierz translacji dla lewej i do góry nogami. W tym celu musimy zdefiniować wartości ujemne.
Linie od 33 do 34: W poprzednim programie w linii 33 definiujemy t x = -50 i t Y = -90. Przesuwamy więc obraz o 50 pikseli w lewą stronę io 90 pikseli w górę. Ale główny proces translacji obrazu odbywa się w linii 34, gdzie definiujemy macierz translacji cv2.warpAffine .
Linia 36 : Linia 36 wyświetli wynik, jak pokazano na wyjściu.
Aby uruchomić poprzedni kod, musimy podać ścieżkę do obrazu, jak podano poniżej.
Wynik: python translate.py – wiewiórka obrazu.jpg
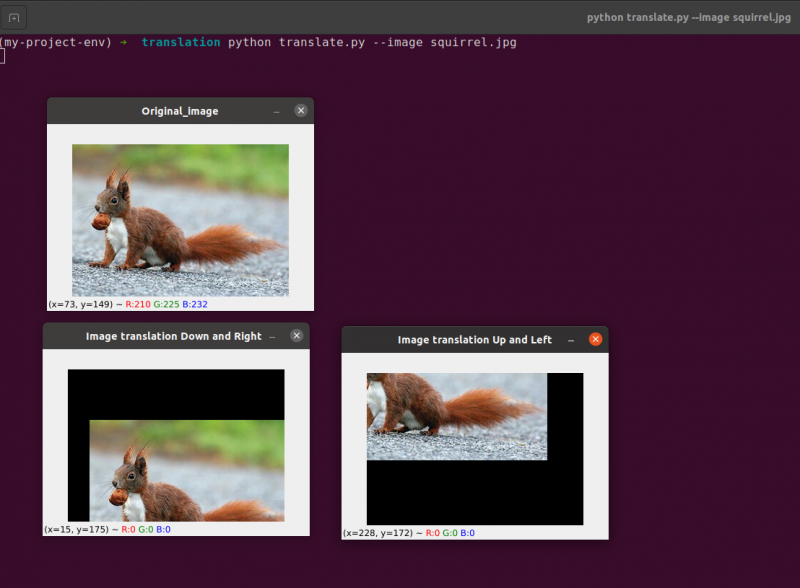
Teraz zaimplementujemy ten sam program do tłumaczenia obrazów za pomocą imutil biblioteka. Ta biblioteka jest bardzo łatwa w użyciu do przetwarzania obrazu. W tej bibliotece nie musimy myśleć o cv2.warpAffine ponieważ ta biblioteka się tym zajmie. Zaimplementujmy więc ten program do tłumaczenia obrazów przy użyciu biblioteki imutils.
Kod Pythona: Zachowamy nazwę następującego programu jako translate_imutils.py .
# zaimportuj niezbędne pakietyimport liczba Jak np
import argparse
import imutil
import cv2
# Ta funkcja implementuje translację obrazu i
# zwraca przetłumaczony obraz do funkcji wywołującej.
pok Tłumaczyć ( obraz , x , Y ) :
macierz_translacji = np. pływak32 ( [ [ 1 , 0 , x ] , [ 0 , 1 , Y ] ] )
tłumaczenie_obrazu = cv2. warpAffine ( obraz , macierz_translacji ,
( obraz. kształtować się [ 1 ] , obraz. kształtować się [ 0 ] ) )
powrót tłumaczenie_obrazu
# skonstruuj parser argumentów i przeanalizuj argumenty
ap = argparse. Analizator argumentów ( )
ap. dodaj_argument ( '-ja' , '--obraz' , wymagany = Prawdziwe , Wsparcie = „Droga do obrazu” )
argumenty = którego ( ap. parse_args ( ) )
# załaduj obraz i wyświetl na ekranie
obraz = cv2. nieczytane ( argumenty [ 'obraz' ] )
cv2. pokaż ( 'Oryginalny obraz' , obraz )
tłumaczenie_obrazu = imutil. Tłumaczyć ( obraz , 10 , 70 )
cv2. pokaż ( „Tłumaczenie obrazu w prawo iw dół” ,
tłumaczenie_obrazu )
cv2. czekaćKlucz ( 0 )
Wiersze od 9 do 13: W tej sekcji programu odbywa się tłumaczenie. Macierz translacji informuje nas o ile pikseli obraz zostanie przesunięty w górę lub w dół lub w lewo lub w prawo.
Te wiersze zostały już wyjaśnione, ale teraz zbudujemy funkcję o nazwie translate () i wyślemy do niej trzy różne parametry. Sam obraz służy jako pierwszy parametr. Wartości x i y macierzy translacji odpowiadają drugiemu i trzeciemu parametrowi.
Uwaga : Nie ma potrzeby definiowania tej funkcji translate w programie, ponieważ jest ona już zawarta w pakiecie bibliotek imutils. Użyłem go w programie ze względu na proste wyjaśnienie. Możemy wywołać tę funkcję bezpośrednio za pomocą imutils, jak pokazano w wierszu 24.
Linia 24: Poprzedni program pokaże, że w linii 24 definiujemy tx = 10 i ty = 70. Przesuwamy więc obraz o 10 pikseli w prawą stronę io 70 pikseli w dół.
W tym programie nie interesują nas żadne funkcje cv2.warpAffine, ponieważ znajdują się one już w pakiecie biblioteki imutils.
Aby uruchomić poprzedni kod, musimy podać ścieżkę do obrazu, jak podano poniżej:
Wynik:
python imutils. py -- obraz wiewiórki. jpg 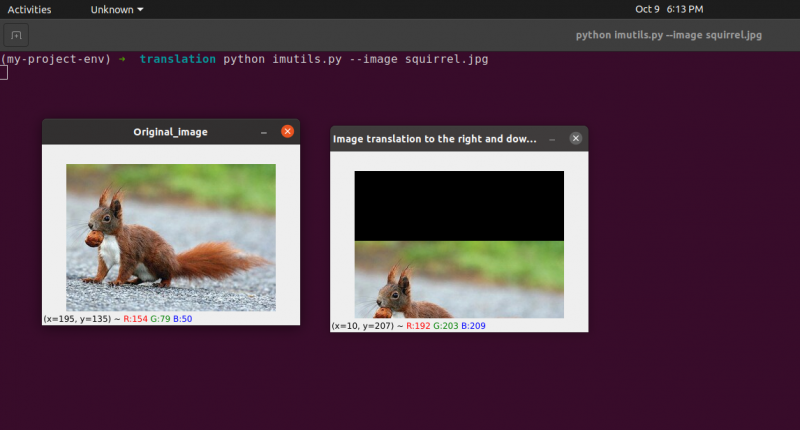
2. Obrót obrazu
W poprzedniej lekcji omówiliśmy, jak przetłumaczyć (tj. przesunąć) obraz w górę, w dół, w lewo i w prawo (lub w dowolnej kombinacji). Następnie omówimy obrót w odniesieniu do przetwarzania obrazu.
Obraz jest obracany o kąt theta w procesie znanym jako obrót. Kąt, o jaki obracamy obraz, będzie reprezentowany przez theta. Dodatkowo udostępnię później wygodną funkcję obracania, aby uprościć obracanie obrazów.
Podobnie jak translacja i być może nie jest to zaskakujące, obrót o kąt, theta jest określane przez zbudowanie macierzy M w następującym formacie:
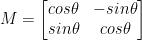
Ta macierz może obrócić wektor theta stopni (przeciwnie do ruchu wskazówek zegara) wokół układu współrzędnych (x, y)-płaszczyzny kartezjańskiej. Zwykle w tym scenariuszu początek byłby środkiem obrazu, ale w rzeczywistości możemy wyznaczyć dowolny losowy punkt (x, y) jako nasz środek obrotu.
Obrócony obraz R jest następnie tworzony z oryginalnego obrazu I przy użyciu prostego mnożenia macierzy: R = IM
Z drugiej strony OpenCV dodatkowo oferuje możliwość (1) skalowania (tj. zmiany rozmiaru) obrazu i (2) oferowania dowolnego środka obrotu do wykonywania obrotu wokół.
Nasza zmodyfikowana macierz rotacji M jest pokazana poniżej:
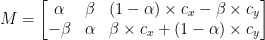
Zacznijmy od otwarcia i wygenerowania nowego pliku o nazwie obróć.py :
# importowanie wymaganych pakietówimport liczba Jak np
import argparse
import imutil
import cv2
# tworzenie obiektu argumentparser i analizowanie argumentu
apobj = argparse. Analizator argumentów ( )
apobj. dodaj_argument ( '-k' , '--obraz' , wymagany = Prawdziwe , Wsparcie = 'ścieżka obrazu' )
argumenty = którego ( apobj. parse_args ( ) )
obraz = cv2. nieczytane ( argumenty [ 'obraz' ] )
cv2. pokaż ( 'Oryginalny obraz' , obraz )
# Oblicz środek obrazu, używając wymiarów obrazu.
( wzrost , szerokość ) = obraz. kształtować się [ : 2 ]
( centrumX , środek Y ) = ( szerokość / 2 , wzrost / 2 )
# Teraz, używając cv2, obrócimy obraz o 55 stopni do
# określ macierz rotacji za pomocą getRotationMatrix2D()
rotacjaMatryca = cv2. getRotationMatrix2D ( ( centrumX , środek Y ) , 55 , 1.0 )
obrócony obraz = cv2. warpAffine ( obraz , rotacjaMatryca , ( szerokość , wzrost ) )
cv2. pokaż ( „Obrócono obraz o 55 stopni” , obrócony obraz )
cv2. czekaćKlucz ( 0 )
# Obraz zostanie teraz obrócony o -85 stopni.
rotacjaMatryca = cv2. getRotationMatrix2D ( ( centrumX , środek Y ) , - 85 , 1.0 )
obrócony obraz = cv2. warpAffine ( obraz , rotacjaMatryca , ( szerokość , wzrost ) )
cv2. pokaż ( „Obrócono obraz o -85 stopni” , obrócony obraz )
cv2. czekaćKlucz ( 0 )
Wiersze od 1 do 5: Importujemy wszystkie wymagane pakiety dla tego programu, takie jak OpenCV, argparser i NumPy. Należy pamiętać, że istnieje inna biblioteka, którą jest imutils. To nie jest pakiet OpenCV. To tylko biblioteka, która będzie używana do łatwego pokazywania tego samego przetwarzania obrazu.
Biblioteka imutils nie zostanie dołączona automatycznie podczas instalacji OpenCV. OpenCV instaluje imutils. Musimy użyć następującej metody:
pip zainstaluj imutils
Wiersze od 8 do 14: Stworzyliśmy nasz agrparser i załadowaliśmy nasz obraz. W tym argparserze używamy tylko jednego argumentu obrazu, który powie nam ścieżkę obrazu, którego użyjemy w tym programie do zademonstrowania obrotu.
Podczas obracania obrazu musimy zdefiniować punkt obrotu. Przez większość czasu będziesz chciał obrócić obraz wokół jego środka, ale OpenCV pozwala zamiast tego wybrać dowolny losowy punkt. Po prostu obróćmy obraz wokół jego środka.
Linie od 17 do 18 weź odpowiednio szerokość i wysokość obrazu, a następnie podziel każdy wymiar przez dwa, aby ustalić środek obrazu.
Konstruujemy macierz do obracania obrazu w taki sam sposób, w jaki zdefiniowaliśmy macierz do translacji obrazu. Po prostu zadzwonimy do cv2.getRotationMatrix2D w wierszu 22 zamiast ręcznie tworzyć macierz za pomocą NumPy (co może być trochę kłopotliwe).
The cv2.getRotationMatrix2D funkcja wymaga trzech parametrów. Pierwszym wejściem jest żądany kąt obrotu (w tym przypadku środek obrazu). Theta jest następnie używana do określenia, o ile stopni (przeciwnie do ruchu wskazówek zegara) obrócimy obraz. Tutaj obrócimy obraz o 45 stopni. Ostatnia opcja jest związana z rozmiarem obrazu.
Niezależnie od tego, że nie omawialiśmy jeszcze skalowania obrazu, możesz tutaj podać liczbę zmiennoprzecinkową z 1,0 oznaczającą, że obraz powinien być używany w oryginalnych proporcjach. Jeśli jednak wpiszesz wartość 2,0, obraz powiększy się dwukrotnie. Liczba 0,5 zmniejsza rozmiar obrazu w ten sposób.
Linie od 22 do 23: Po otrzymaniu naszej macierzy rotacji M od cv2.getRotationMatrix2D funkcji, obracamy nasz obraz za pomocą cv2.warpAffine w linii 23. Pierwszym wejściem funkcji jest obraz, który chcemy obrócić. Następnie definiowana jest szerokość i wysokość naszego obrazu wyjściowego wraz z naszą macierzą obrotu M. W linii 23 obraz jest następnie obracany o 55 stopni.
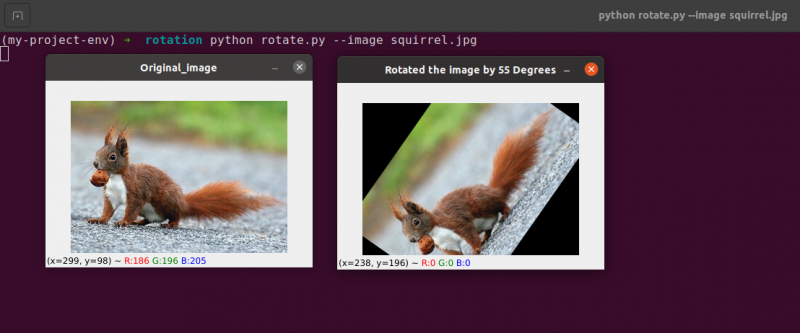
Możesz zauważyć, że nasz obraz został obrócony.
Linie od 28 do 30 stanowią drugą rotację. Wiersze 22–23 kodu są identyczne, z tą różnicą, że tym razem obracamy się o -85 stopni, a nie o 55.
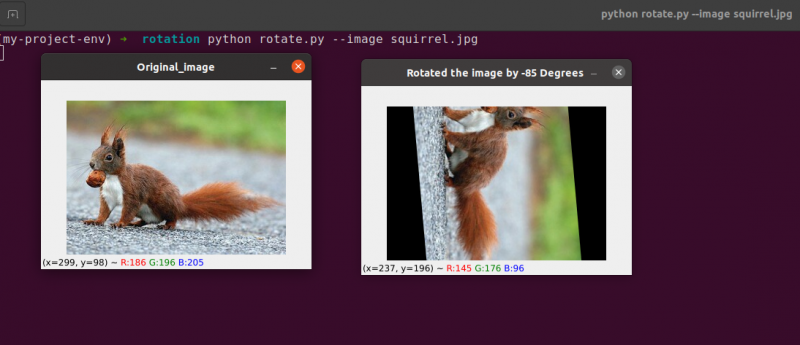
Do tego momentu po prostu obróciliśmy obraz wokół jego środka. Co by było, gdybyśmy chcieli obrócić obraz wokół losowego punktu?
Zacznijmy od otwarcia i wygenerowania nowego pliku o nazwie obróć.py:
# importowanie wymaganych pakietówimport liczba Jak np
import argparse
import imutil
import cv2
# tworzenie obiektu argumentparser i analizowanie argumentu
ap_obj = argparse. Analizator argumentów ( )
ap_obj. dodaj_argument ( '-k' , '--obraz' , wymagany = Prawdziwe , Wsparcie = 'ścieżka obrazu' )
argument = którego ( ap_obj. parse_args ( ) )
# załaduj obraz i wyświetl go na ekranie
obraz = cv2. nieczytane ( argument [ 'obraz' ] )
cv2. pokaż ( 'Oryginalny obraz' , obraz )
# Oblicz środek obrazu, używając wymiarów obrazu.
( wzrost , szerokość ) = obraz. kształtować się [ : 2 ]
( centrumX , środek Y ) = ( szerokość / 2 , wzrost / 2 )
# Teraz, używając cv2, obrócimy obraz o 55 stopni do
# określ macierz rotacji za pomocą getRotationMatrix2D()
rotacjaMatryca = cv2. getRotationMatrix2D ( ( centrumX , środek Y ) , 55 , 1.0 )
obrócony obraz = cv2. warpAffine ( obraz , rotacjaMatryca , ( szerokość , wzrost ) )
cv2. pokaż ( „Obrócono obraz o 55 stopni” , obrócony obraz )
cv2. czekaćKlucz ( 0 )
# Obraz zostanie teraz obrócony o -85 stopni.
rotacjaMatryca = cv2. getRotationMatrix2D ( ( centrumX , środek Y ) , - 85 , 1.0 )
obrócony obraz = cv2. warpAffine ( obraz , rotacjaMatryca , ( szerokość , wzrost ) )
cv2. pokaż ( „Obrócono obraz o -85 stopni” , obrócony obraz )
cv2. czekaćKlucz ( 0 )
# obrót obrazu od dowolnego punktu, a nie od środka
rotacjaMatryca = cv2. getRotationMatrix2D ( ( centrumX - 40 , centrum Y - 40 ) , 55 , 1.0 )
obrócony obraz = cv2. warpAffine ( obraz , rotacjaMatryca , ( szerokość , wzrost ) )
cv2. pokaż ( „Obrót obrazu z dowolnych punktów” , obrócony obraz )
cv2. czekaćKlucz ( 0 )
Linie od 34 do 35: Teraz ten kod powinien wydawać się dość powszechny w przypadku obracania obiektu. Aby obrócić obraz wokół punktu o 40 pikseli w lewo i 40 pikseli powyżej jego środka, instruujemy cv2.getRotationMatrix2D funkcji, aby zwrócić uwagę na jej pierwszy parametr.
Obraz utworzony po zastosowaniu tego obrotu pokazano poniżej:
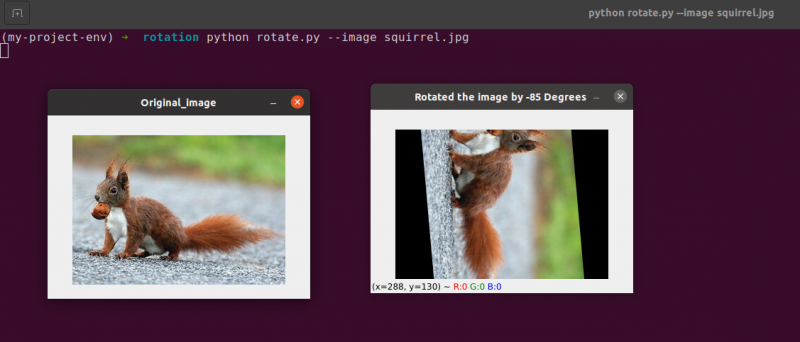
Możemy wyraźnie zobaczyć, że środek obrotu jest teraz współrzędną (x, y), czyli 40 pikseli w lewo i 40 pikseli powyżej obliczonego środka obrazu.
3. Arytmetyka obrazu
W rzeczywistości arytmetyka obrazu to po prostu dodawanie macierzy z kilkoma dodatkowymi ograniczeniami dotyczącymi typów danych, które omówimy później.
Poświęćmy chwilę na omówienie kilku ładnych podstaw algebry liniowej.
Rozważ połączenie kolejnych dwóch macierzy:
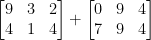
Jaki wynik dałoby dodanie macierzy? Prostą odpowiedzią jest suma wpisów macierzy, element po elemencie:
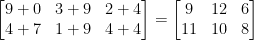
Dość proste, prawda?
Wszyscy rozumiemy podstawowe operacje dodawania i odejmowania w tym czasie. Podczas pracy z obrazami musimy jednak pamiętać o ograniczeniach nałożonych przez naszą przestrzeń kolorów i typ danych.
Na przykład piksele w obrazach RGB mieszczą się w przedziale [0, 255]. Co się stanie, jeśli spróbujemy dodać 10 do piksela o intensywności 250, patrząc na niego?
Otrzymalibyśmy wartość 260, gdybyśmy zastosowali standardowe zasady arytmetyczne. 260 nie jest prawidłową wartością, ponieważ obrazy RGB są reprezentowane jako 8-bitowe liczby całkowite bez znaku.
Co zatem powinno się wydarzyć? Czy powinniśmy przeprowadzić kontrolę, aby upewnić się, że żaden piksel nie znajduje się poza zakresem [0, 255], przycinając każdy piksel, aby miał wartość między 0 a 255?
A może „zawijamy” i wykonujemy operację modułu? Zgodnie z zasadami modułu dodanie 10 do 255 dałoby po prostu wartość 9.
Jak należy postępować z dodawaniem i odejmowaniem obrazów poza zakresem [0, 255]?
Prawda jest taka, że nie ma dobrej ani złej techniki; wszystko zależy od tego, jak pracujesz z pikselami i od tego, co masz nadzieję osiągnąć.
Pamiętaj jednak, że istnieją różnice między dodawaniem w OpenCV a dodawaniem w NumPy. Arytmetyka modułu i „zawijanie” będzie wykonywane przez NumPy. Natomiast OpenCV wykona obcinanie i upewni się, że wartości pikseli nigdy nie opuszczą zakresu [0, 255].
Zacznijmy od utworzenia nowego pliku o nazwie arithmetic.py i otwierając to:
# python arithmetic.py --image wiewiórka.jpg# importowanie wymaganych pakietów
import liczba Jak np
import argparse
import imutil
import cv2
# tworzenie obiektu argumentparser i analizowanie argumentu
apObj = argparse. Analizator argumentów ( )
apObj. dodaj_argument ( '-k' , '--obraz' , wymagany = Prawdziwe , Wsparcie = 'ścieżka obrazu' )
argumenty = którego ( apObj. parse_args ( ) )
obraz = cv2. nieczytane ( argumenty [ 'obraz' ] )
cv2. pokaż ( 'Oryginalny obraz' , obraz )
'''
Wartości naszych pikseli będą mieścić się w przedziale [0, 255]
ponieważ obrazy są tablicami NumPy, które są przechowywane jako 8-bitowe liczby całkowite bez znaku.
Podczas korzystania z funkcji takich jak cv2.add i cv2.subtract wartości zostaną obcięte
do tego zakresu, nawet jeśli są dodawane lub odejmowane spoza zakresu
[0, 255] zakres. Oto ilustracja:
'''
wydrukować ( 'maksymalnie 255: {}' . format ( ul ( cv2. Dodaj ( np. uint8 ( [ 201 ] ) ,
np. uint8 ( [ 100 ] ) ) ) ) )
wydrukować ( „minimum 0: {}” . format ( ul ( cv2. odjąć ( np. uint8 ( [ 60 ] ) ,
np. uint8 ( [ 100 ] ) ) ) ) )
'''
Podczas wykonywania operacji arytmetycznych na tych tablicach przy użyciu NumPy,
wartość będzie się zawijać, a nie być przycinana do
[0, 255]zakres. Podczas korzystania z obrazów konieczne jest zachowanie tego
w umyśle.
'''
wydrukować ( 'owinąć: {}' . format ( ul ( np. uint8 ( [ 201 ] ) + np. uint8 ( [ 100 ] ) ) ) )
wydrukować ( 'owinąć: {}' . format ( ul ( np. uint8 ( [ 60 ] ) - np. uint8 ( [ 100 ] ) ) ) )
'''
Pomnóżmy jasność każdego piksela na naszym obrazie przez 101.
W tym celu generujemy tablicę NumPy o takim samym rozmiarze jak nasza macierz,
wypełnione jedynkami i pomnóż przez 101, aby otrzymać wypełnioną tablicę
z 101s. Na koniec łączymy oba obrazy.
Zauważysz, że obraz jest teraz „jaśniejszy”.
'''
Matryca = np. te ( obraz. kształtować się , dtyp = 'uint8' ) * 101
obraz_dodany = cv2. Dodaj ( obraz , Matryca )
cv2. pokaż ( „Wynik dodania obrazu” , obraz_dodany )
#W podobny sposób możemy przyciemnić nasz obraz, wykonując zdjęcia
# 60 od wszystkich pikseli.
Matryca = np. te ( obraz. kształtować się , dtyp = 'uint8' ) * 60
obraz_odjęty = cv2. odjąć ( obraz , Matryca )
cv2. pokaż ( „Odjęty wynik obrazu” , obraz_odjęty )
cv2. czekaćKlucz ( 0 )
Linie od 1 do 16 zostanie użyty do przeprowadzenia naszego normalnego procesu, który obejmuje import naszych pakietów, skonfigurowanie naszego parsera argumentów i załadowanie naszego obrazu.
Pamiętasz, jak wcześniej omawiałem różnicę między dodawaniem OpenCV i NumPy? Teraz, gdy dokładnie to omówiliśmy, spójrzmy na konkretny przypadek, aby upewnić się, że go rozumiemy.
Zdefiniowano dwie 8-bitowe tablice liczb całkowitych bez znaku NumPy linia 26 . Wartość 201 jest jedynym elementem w pierwszej tablicy. Chociaż tylko jeden element znajduje się w drugiej tablicy, ma ona wartość 100. Wartości są następnie dodawane za pomocą funkcji cv2.add OpenCV.
Jaki przewidujesz wynik?
Zgodnie z konwencjonalnymi zasadami arytmetyki, wynikiem powinno być 301. Należy jednak pamiętać, że mamy do czynienia z 8-bitowymi liczbami całkowitymi bez znaku, które mogą należeć tylko do zakresu [0, 255]. Ponieważ używamy metody cv2.add, OpenCV obsługuje obcinanie i zapewnia, że dodawanie zwróci tylko maksymalny wynik 255.
Pierwszy wiersz poniższego wykazu pokazuje wynik działania tego kodu:
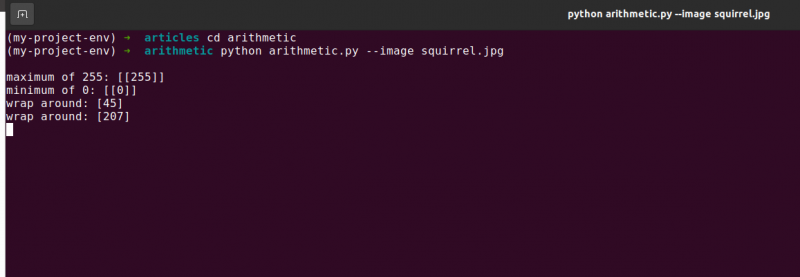
arytmetyka. pymaksymalnie 255 : [ [ 255 ] ]
Suma rzeczywiście dała liczbę 255.
Idąc za tym, linia 26 używa cv2.subtract do wykonania odejmowania. Jeszcze raz zdefiniujemy dwie 8-bitowe tablice NumPy liczb całkowitych bez znaku z pojedynczym elementem w każdej. Wartość pierwszej tablicy to 60, a wartość drugiej tablicy to 100.
Nasza arytmetyka mówi, że odejmowanie powinno dać wartość -40, ale OpenCV ponownie obsługuje obcinanie za nas. Odkrywamy, że wartość została przycięta do 0. Pokazuje to nasz wynik poniżej:
arytmetyka. pyminimum 0 : [ [ 0 ] ]
Używając cv2, odejmij 100 od 60 odejmij, uzyskując wartość 0.
Ale co się stanie, jeśli użyjemy NumPy zamiast OpenCV do przeprowadzenia obliczeń?
Linie 38 i 39 zająć się tą sprawą.
Najpierw definiowane są dwie 8-bitowe tablice liczb całkowitych bez znaku NumPy, z których każda zawiera jeden element. Wartość pierwszej tablicy to 201, podczas gdy wartość drugiej tablicy to 100. Nasze dodanie zostałoby obcięte, a wartość 255 zostałaby zwrócona, gdybyśmy użyli funkcji cv2.add.
Z drugiej strony NumPy „zawija się” i wykonuje arytmetykę modulo zamiast obcinania. NumPy zawija się do zera po osiągnięciu wartości 255, a następnie wznawia liczenie aż do osiągnięcia 100 kroków. Potwierdza to pierwszy wiersz wyjścia, który pokazano poniżej:
arytmetyka. pyowinąć: [ Cztery pięć ]
Następnie definiowane są dwie kolejne tablice NumPy, jedna z wartością 50, a druga z wartością 100. Odejmowanie to zostałoby obcięte metodą cv2.subtract w celu zwrócenia wyniku 0. Ale zdajemy sobie sprawę, że zamiast obcinania, NumPy wykonuje arytmetyka modulo. Zamiast tego procedury modulo zawijają się i rozpoczynają odliczanie wstecz od 255 po osiągnięciu 0 podczas odejmowania. Widzimy to z następującego wyniku:
arytmetyka. pyowinąć: [ 207 ]
Po raz kolejny nasze wyjście terminala pokazuje różnicę między obcinaniem a zawijaniem:
Ważne jest, aby pamiętać o pożądanym wyniku podczas wykonywania działań arytmetycznych na liczbach całkowitych. Czy chcesz obciąć wartości spoza zakresu [0, 255]? Następnie użyj wbudowanych technik arytmetycznych obrazu OpenCV.
Czy chcesz, aby wartości były zawijane, jeśli znajdują się poza zakresem operacji arytmetycznych [0, 255] i modułów? Tablice NumPy są następnie po prostu dodawane i odejmowane w zwykły sposób.
Linia 48 definiuje jednowymiarową tablicę NumPy o takich samych wymiarach jak nasz obrazek. Jeszcze raz upewniamy się, że naszym typem danych są 8-bitowe liczby całkowite bez znaku. Po prostu mnożymy naszą macierz wartości jednocyfrowych przez 101, aby wypełnić ją wartościami 101 zamiast 1. Na koniec używamy funkcji cv2.add, aby dodać naszą macierz setek do oryginalnego obrazu. Zwiększa to intensywność każdego piksela o 101, zapewniając jednocześnie, że wszelkie wartości, które próbują przekroczyć 255, zostaną przycięte do zakresu [0, 255].
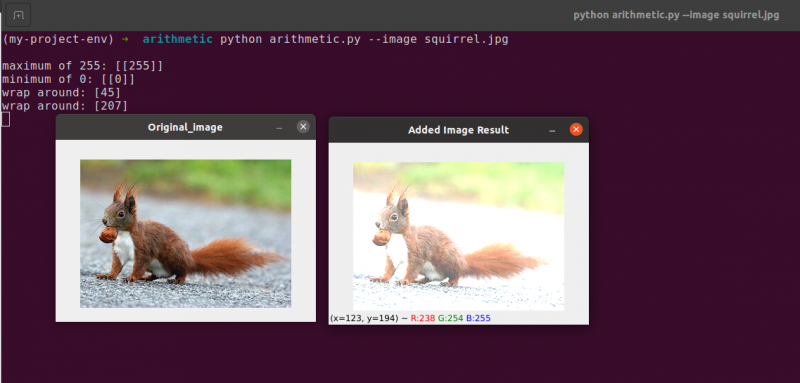
Zwróć uwagę, że obraz jest zauważalnie jaśniejszy i wydaje się bardziej „wyprany” niż oryginał. Dzieje się tak, ponieważ kierujemy piksele w kierunku jaśniejszych kolorów, zwiększając intensywność ich pikseli o 101.
Aby odjąć 60 od intensywności każdego piksela obrazu, najpierw ustalamy drugą tablicę NumPy w wierszu 54, która jest wypełniona latami 60.
Wyniki tego odejmowania przedstawiono na poniższym obrazku:
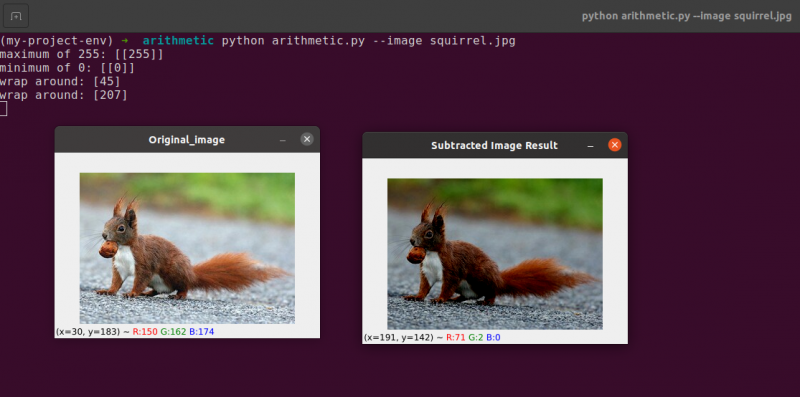
Przedmioty wokół nas wydają się znacznie ciemniejsze niż wcześniej. Dzieje się tak, ponieważ odejmując 60 od każdego piksela, przesuwamy piksele z przestrzeni kolorów RGB do ciemniejszych regionów.
4. Odwracanie obrazu
Podobnie jak w przypadku obracania, odwracanie obrazu wzdłuż jego osi x lub y to kolejna opcja oferowana przez OpenCV. Nawet jeśli operacje odwracania nie są wykorzystywane tak często, znajomość ich jest niezwykle korzystna z różnych powodów, których możesz nie od razu zauważyć.
Opracowujemy klasyfikator uczenia maszynowego dla małej firmy rozpoczynającej działalność, która stara się identyfikować twarze na obrazach. Aby nasz system „nauczył się”, czym jest twarz, potrzebowalibyśmy jakiegoś zestawu danych z przykładowymi twarzami. Niestety, firma udostępniła nam tylko niewielki zbiór danych zawierający 40 twarzy i nie jesteśmy w stanie zebrać więcej informacji.
Co w takim razie robimy?
Ponieważ twarz pozostaje twarzą, niezależnie od tego, czy jest lustrzana, czy nie, jesteśmy w stanie odwrócić poziomo każdy obraz twarzy i użyć lustrzanych wersji jako dodatkowych danych treningowych.
Ten przykład może wydawać się głupi i sztuczny, ale tak nie jest. Przerzucanie jest celową strategią stosowaną przez silne algorytmy głębokiego uczenia się w celu generowania większej ilości danych podczas fazy uczenia.
Z poprzedniego jasno wynika, że metody przetwarzania obrazu, których nauczysz się w tym module, służą jako podstawa dla większych komputerowych systemów wizyjnych.
Cele:
Używając cv2.odwróć tej funkcji nauczysz się odwracać obraz zarówno w poziomie, jak iw pionie.
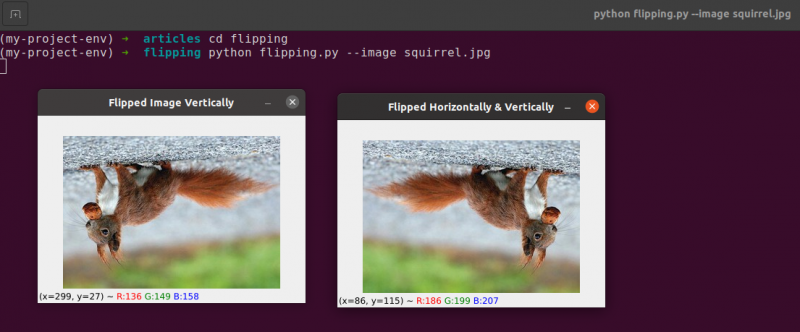
Przerzucanie to kolejna manipulacja obrazem, którą będziemy studiować. Osie x i y obrazu można odwrócić, a nawet obydwa. Zanim zagłębimy się w kodowanie, najlepiej najpierw przyjrzeć się wynikom odwrócenia obrazu. Zobacz obraz, który został odwrócony w poziomie na poniższym obrazie:
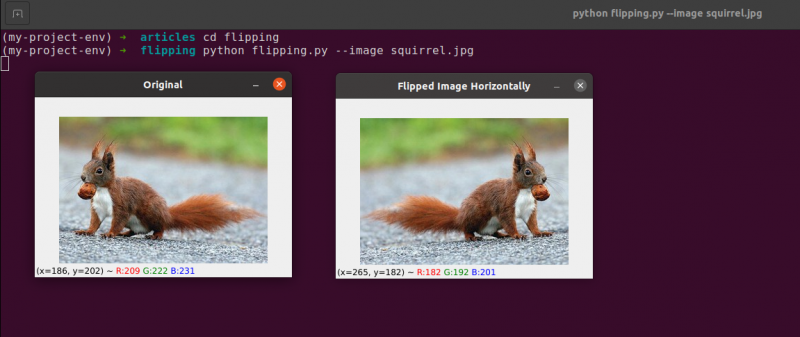
Zwróć uwagę, jak nasz oryginalny obraz znajduje się po lewej stronie i jak obraz został odbity w poziomie po prawej stronie.
Zacznijmy od utworzenia nowego pliku o nazwie przerzucanie.py .
Widziałeś przykład odwrócenia obrazu, więc przeanalizujmy kod:
# python flipping.py --image quirrel.jpg# importowanie wymaganych pakietów
import argparse
import cv2
# tworzenie obiektu parsera argumentów i analizowanie argumentu
apObj = argparse. Analizator argumentów ( )
apObj. dodaj_argument ( '-ja' , '--obraz' , wymagany = Prawdziwe , Wsparcie = 'ścieżka obrazu' )
argument = którego ( apObj. parse_args ( ) )
obraz = cv2. nieczytane ( argument [ 'obraz' ] )
cv2. pokaż ( 'Oryginał' , obraz )
# odwróć obraz w poziomie
odwrócony obraz = cv2. trzepnięcie ( obraz , 1 )
cv2. pokaż ( „Obrócony obraz w poziomie” , odwrócony obraz )
# odwróć obraz w pionie
odwrócony obraz = cv2. trzepnięcie ( obraz , 0 )
cv2. pokaż ( „Obrócony obraz w pionie” , odwrócony obraz )
# Odwróć obraz wzdłuż obu osi
odwrócony obraz = cv2. trzepnięcie ( obraz , - 1 )
cv2. pokaż ( „Odwrócony w poziomie i w pionie” , odwrócony obraz )
cv2. czekaćKlucz ( 0 )
Kroki, które podejmujemy, aby zaimportować nasze pakiety, przeanalizować nasze dane wejściowe i załadować nasz obraz z dysku, są obsługiwane w l od 1 do 12 .
Wywołując funkcję cv2.flip Linia 15 , łatwo jest odwrócić obraz w poziomie. Obraz, który chcemy odwrócić, oraz określony kod lub flaga określająca sposób odwrócenia obrazu to dwa argumenty potrzebne metodzie cv2.flip.
Wartość kodu odwrócenia równa 1 oznacza, że obrócimy obraz wokół osi y, aby odwrócić go w poziomie ( Linia 15 ). Jeśli określimy kod odwrócenia równy 0, chcemy obrócić obraz wokół osi x ( Linia 19 ). Ujemny kod odwrócenia ( Linia 23 ) obraca obraz w obu osiach.
Jednym z najłatwiejszych przykładów w tym temacie jest odwrócenie obrazu, który jest podstawowy.
Następnie omówimy kadrowanie obrazów i użyjemy wycinków tablicy NumPy do wyodrębnienia określonych fragmentów obrazu.
5. Kadrowanie obrazu
Kadrowanie, jak sama nazwa wskazuje, to proces wybierania i usuwania Regionu zainteresowania (lub po prostu ROI), czyli obszaru obrazu, który nas interesuje.
Twarz musiałaby zostać przycięta z obrazu na potrzeby aplikacji do wykrywania twarzy. Dodatkowo, gdybyśmy tworzyli skrypt Pythona do znajdowania psów na obrazach, moglibyśmy chcieć wykadrować psa z obrazu, gdy go zlokalizujemy.
Cele: Naszym głównym celem jest zapoznanie się i swobodne korzystanie z dzielenia tablicy NumPy do przycinania obszarów z obrazu.
Uprawa : Kiedy przycinamy zdjęcie, naszym celem jest wyeliminowanie elementów zewnętrznych, które nas nie interesują. Proces wyboru naszego ROI jest często określany jako wybór naszego regionu zainteresowania.
Utwórz nowy plik o nazwie upraw.py , otwórz go i dodaj następujący kod:
# python crop.py# importowanie wymaganych pakietów
import cv2
# ładowanie i wyświetlanie obrazu na ekranie
obraz = cv2. nieczytane ( 'wiewiórka.jpg' )
wydrukować ( obraz. kształtować się )
cv2. pokaż ( 'Oryginał' , obraz )
# Plasterki tablicy NumPy służą do szybkiego przycinania obrazu
# zamierzamy wyciąć twarz wiewiórki z obrazu
wiewiórcza twarz = obraz [ 35 : 90 , 35 : 100 ]
cv2. pokaż ( „twarz wiewiórki” , wiewiórcza twarz )
cv2. czekaćKlucz ( 0 )
# A teraz przytniemy całe ciało
# wiewiórka
wiewiórka = obraz [ 35 : 148 , 23 : 143 ]
cv2. pokaż ( „Ciało wiewiórki” , wiewiórka )
cv2. czekaćKlucz ( 0 )
Pokażemy kadrowanie w Pythonie i OpenCV przy użyciu obrazu, który ładujemy z dysku Linie 5 i 6 .

Oryginalny obraz, który zamierzamy wykadrować
Używając tylko podstawowych technik kadrowania, dążymy do oddzielenia pyska i ciała wiewiórki od otaczającego obszaru.
Wykorzystamy naszą wcześniejszą wiedzę o obrazie i ręcznie dostarczymy wycinki tablicy NumPy przedstawiające miejsce, w którym znajduje się ciało i twarz. W normalnych warunkach na ogół stosowalibyśmy algorytmy uczenia maszynowego i komputerowego rozpoznawania twarzy do rozpoznawania twarzy i ciała na obrazie. Ale na razie zachowajmy prostotę i unikajmy stosowania jakichkolwiek modeli wykrywania.
Twarz na obrazie możemy zidentyfikować za pomocą zaledwie jednej linijki kodu. Linia 13 , Aby wyodrębnić prostokątną część obrazu, zaczynając od (35, 35), udostępniamy wycinki tablicy NumPy (90, 100). Może wydawać się mylące, że zasilamy kadr indeksami w kolejności od wysokości do pierwszej i szerokości do drugiej, ale pamiętaj, że OpenCV przechowuje obrazy jako tablice NumPy. W rezultacie musimy podać wartości dla osi y przed osią x.
NumPy wymaga następujących czterech indeksów do wykonania naszego kadrowania:
Zacznij y: Współrzędna y na początku. W tym przypadku zaczynamy od y=35.
Koniec y: Współrzędna y na końcu. Nasze zbiory zatrzymają się, gdy y = 90.
Rozpocznij x: Współrzędna x początku wycinka. Uprawa rozpoczyna się przy x=35.
Koniec x: Współrzędna osi x końca wycinka. Przy x=100 nasz wycinek jest skończony.
Podobnie przycinamy regiony (23, 35) i (143, 148) z oryginalnego obrazu, aby wyodrębnić całe ciało z obrazu na Linia 19 .
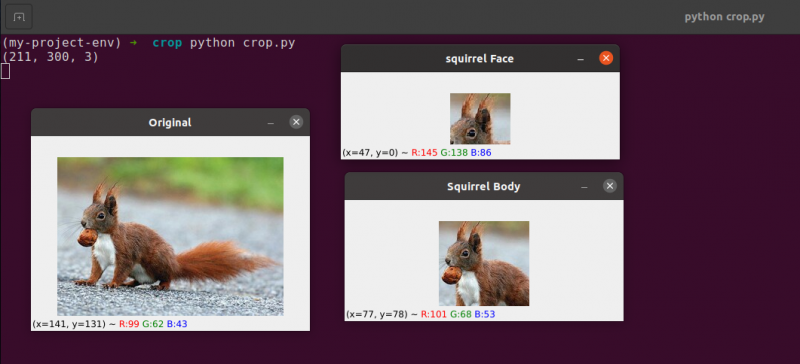
Możesz zauważyć, że obraz został przycięty, aby pokazać tylko ciało i twarz.
6. Zmiana rozmiaru obrazu
Proces zwiększania lub zmniejszania szerokości i wysokości obrazu jest znany jako skalowanie lub po prostu zmiana rozmiaru. Podczas zmiany rozmiaru obrazu należy wziąć pod uwagę współczynnik proporcji, czyli stosunek szerokości obrazu do jego wysokości. Zaniedbanie współczynnika proporcji może spowodować, że przeskalowane obrazy będą wyglądały na skompresowane i zniekształcone:
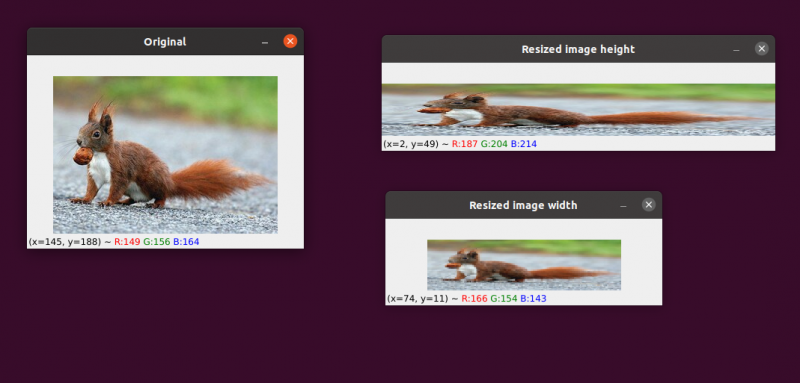
Nasz początkowy obraz znajduje się po lewej stronie. Po prawej stronie zobaczysz dwa obrazy, które zostały przeskalowane bez zachowania proporcji, zniekształcając proporcje szerokości obrazu do jego wysokości. Zmieniając rozmiar obrazów, należy ogólnie wziąć pod uwagę współczynnik proporcji.
Technika interpolacji używana przez nasz algorytm zmiany rozmiaru musi również uwzględniać cel funkcji interpolacji, aby wykorzystać te sąsiedztwa pikseli do zwiększenia lub zmniejszenia rozmiaru obrazu.
Ogólnie rzecz biorąc, zmniejszenie rozmiaru obrazu jest znacznie bardziej skuteczne. Dzieje się tak, ponieważ usuwanie pikseli z obrazu to wszystko, co musi zrobić funkcja interpolacji. Z drugiej strony metoda interpolacji musiałaby „wypełnić luki” między pikselami, których wcześniej nie było, gdyby rozmiar obrazu miał zostać zwiększony.
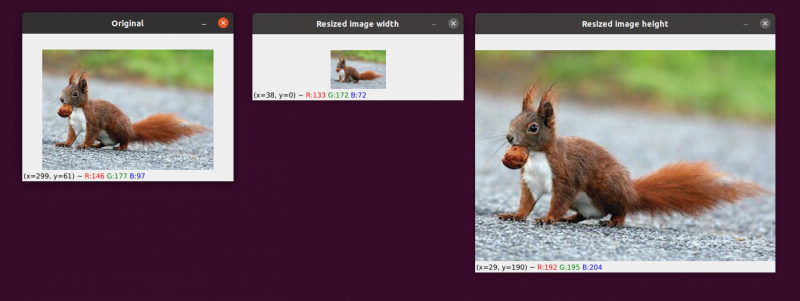
Mamy nasz oryginalny obraz po lewej stronie. Obraz został zmniejszony do połowy jego pierwotnego rozmiaru na środku, ale poza tym nie nastąpiła utrata „jakości” obrazu. Niemniej jednak rozmiar obrazu został znacznie powiększony po prawej stronie. Teraz wygląda na „powiększony” i „pikselowany”.
Jak już wcześniej wspomniałem, zwykle będziesz chciał zmniejszyć rozmiar obrazu, a nie go zwiększyć. Zmniejszając rozmiar obrazu, analizujemy mniej pikseli i mamy do czynienia z mniejszym „szumem”, co sprawia, że algorytmy przetwarzania obrazu są szybsze i bardziej precyzyjne.
Translacja i rotacja to dwie przekształcenia obrazu, o których mowa do tej pory. Przyjrzymy się teraz, jak zmienić rozmiar obrazu.
Nic dziwnego, że będziemy zmieniać rozmiar naszych obrazów za pomocą metody cv2.resize. Jak wspomniałem wcześniej, podczas korzystania z tej metody musimy wziąć pod uwagę proporcje obrazu. Zanim jednak zagłębimy się w szczegóły, pozwólcie, że przedstawię wam ilustrację:
# python resize.py --image wiewiórka.jpg# importowanie wymaganych pakietów
import argparse
import cv2
# tworzenie obiektu parsera argumentów i analizowanie argumentu
apObj = argparse. Analizator argumentów ( )
apObj. dodaj_argument ( '-k' , '--obraz' , wymagany = Prawdziwe , Wsparcie = 'ścieżka obrazu' )
argumenty = którego ( apObj. parse_args ( ) )
# załaduj obraz i wyświetl go na ekranie
obraz = cv2. nieczytane ( argumenty [ 'obraz' ] )
cv2. pokaż ( 'Oryginał' , obraz )
# Aby zapobiec przekrzywieniu obrazu, należy ustawić współczynnik proporcji
# należy rozważyć lub zdeformować; dlatego ustalamy, co
# stosunek nowego obrazu do bieżącego obrazu.
# Ustawmy szerokość naszego nowego obrazu na 160 pikseli.
aspekt = 160,0 / obraz. kształtować się [ 1 ]
wymiar = ( 160 , int ( obraz. kształtować się [ 0 ] * aspekt ) )
# ta linia pokaże rzeczywiste operacje zmiany rozmiaru
obraz o zmienionym rozmiarze = cv2. Zmień rozmiar ( obraz , wymiar , interpolacja = cv2. INTER_OBSZAR )
cv2. pokaż ( „Zmieniono szerokość obrazu” , obraz o zmienionym rozmiarze )
# A gdybyśmy chcieli zmienić wysokość obrazu? - używając
# ta sama zasada, możemy obliczyć współczynnik proporcji na podstawie
# na wysokości, a nie na szerokości. Zróbmy skalowane
# wysokość obrazu 70 pikseli.
aspekt = 70,0 / obraz. kształtować się [ 0 ]
wymiar = ( int ( obraz. kształtować się [ 1 ] * aspekt ) , 70 )
# wykonaj zmianę rozmiaru
obraz o zmienionym rozmiarze = cv2. Zmień rozmiar ( obraz , wymiar , interpolacja = cv2. INTER_OBSZAR )
cv2. pokaż ( „Zmieniono wysokość obrazu” , obraz o zmienionym rozmiarze )
cv2. czekaćKlucz ( 0 )
Linie 1-14 , Po zaimportowaniu naszych pakietów i skonfigurowaniu naszego parsera argumentów, załadujemy i wyświetlimy nasz obraz.
Wiersze 20 i 21: W tych wierszach rozpoczyna się odpowiednie kodowanie . Podczas zmiany rozmiaru należy wziąć pod uwagę proporcje obrazu. Proporcja między szerokością a wysokością obrazu jest znana jako współczynnik proporcji.
Wysokość szerokość jest współczynnikiem proporcji.
Jeśli nie weźmiemy pod uwagę współczynnika proporcji, wyniki naszej zmiany rozmiaru zostaną zniekształcone.
Na Linia 20 , obliczenie współczynnika zmiany rozmiaru jest zakończone. W tym wierszu kodu podajemy szerokość naszego nowego obrazu jako 160 pikseli. Po prostu definiujemy nasz współczynnik (aspectratio) jako nową szerokość (160 pikseli) podzieloną przez starą szerokość, do której uzyskujemy dostęp za pomocą obrazu, aby obliczyć stosunek nowej wysokości do starej wysokości. kształt[1].
Nowe wymiary obrazu na Linia 21 można obliczyć teraz, gdy znamy nasz stosunek. Po raz kolejny nowy obraz będzie miał szerokość 160 pikseli. Po przemnożeniu starej wysokości przez nasz współczynnik i przeliczeniu wyniku na liczbę całkowitą obliczamy wysokość. Wykonując tę operację, możemy zachować oryginalne proporcje obrazu.
Linia 24 to miejsce, w którym obraz jest naprawdę zmieniany. Obraz, którego rozmiar chcemy zmienić, to pierwszy argument, a drugi to wymiary, które obliczyliśmy dla nowego obrazu. Ostatnim parametrem jest nasza metoda interpolacji, czyli algorytm zmiany rozmiaru rzeczywistego obrazu.
Wreszcie na Linia 25 , wyświetlamy nasz przeskalowany obraz.
Na nowo definiujemy nasz stosunek (aspectratio). Linia 31 . Wysokość naszego nowego obrazu wyniesie 70 pikseli. Dzielimy 70 przez pierwotną wysokość, aby uzyskać nowy stosunek wysokości do pierwotnej wysokości.
Następnie ustalamy wymiary nowego obrazu. Nowy obraz będzie miał wysokość 70 pikseli, co jest już znane. Możemy ponownie zachować oryginalne proporcje obrazu, mnożąc starą szerokość przez współczynnik, aby uzyskać nową szerokość.
Rozmiar obrazu jest następnie faktycznie zmieniany Linia 35 i jest wyświetlany na Linia 36.
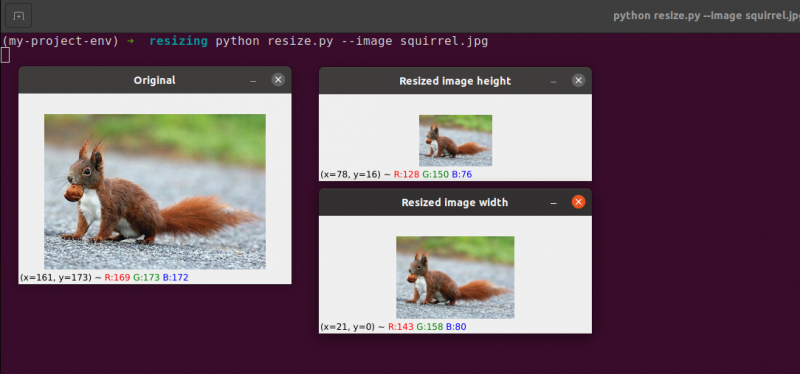
Tutaj widzimy, że zmniejszyliśmy szerokość i wysokość naszego oryginalnego obrazu, zachowując proporcje. Nasz obraz wydawałby się zniekształcony, gdyby proporcje nie zostały zachowane.
Wniosek
Na tym blogu przestudiowaliśmy podstawowe różne koncepcje przetwarzania obrazu. Widzieliśmy tłumaczenie obrazu za pomocą pakietu OpenCV. Widzieliśmy metody przesuwania obrazu w górę, w dół, w prawo iw lewo. Metody te są bardzo przydatne, gdy tworzymy zestaw danych składający się z podobnych obrazów, które mają być zestawem danych szkoleniowych, dzięki czemu maszyna zobaczy różne obrazy, nawet jeśli są takie same. W tym artykule dowiesz się również, jak obracać obraz wokół dowolnego punktu w przestrzeni kartezjańskiej za pomocą macierzy rotacji. Następnie odkryłeś, jak OpenCV obraca obrazy za pomocą tej macierzy i zobaczyłeś kilka ilustracji obracających się obrazów.
W tej sekcji zbadano dwie podstawowe (ale znaczące) operacje arytmetyczne na obrazach: dodawanie i odejmowanie. Jak widać, dodawanie i odejmowanie podstawowych macierzy to wszystkie operacje arytmetyczne na obrazach.
Dodatkowo wykorzystaliśmy OpenCV i NumPy do zbadania osobliwości arytmetyki obrazu. Należy pamiętać o tych ograniczeniach, w przeciwnym razie ryzykujesz uzyskanie nieoczekiwanych wyników podczas wykonywania operacji arytmetycznych na obrazach.
Ważne jest, aby pamiętać, że chociaż NumPy wykonuje operację modułu i „zawija się”, OpenCV dodawania i odejmowania wartości obcina poza zakresem [0, 255], aby zmieścić się w tym zakresie. Pamiętaj o tym, opracowując własne aplikacje do przetwarzania obrazu komputerowego, co pomoże ci uniknąć wyszukiwania trudnych błędów.
Odwracanie obrazu jest niewątpliwie jednym z prostszych pomysłów, które omówimy w tym kursie. Odwracanie jest często stosowane w uczeniu maszynowym do generowania większej liczby próbek danych treningowych, co skutkuje silniejszymi i bardziej niezawodnymi klasyfikatorami obrazów.
Nauczyliśmy się również, jak używać OpenCV do zmiany rozmiaru obrazu. Ważne jest, aby podczas zmiany rozmiaru obrazu wziąć pod uwagę zarówno stosowaną metodę interpolacji, jak i proporcje oryginalnego obrazu, aby wynik nie wyglądał na zniekształcony.
Na koniec należy pamiętać, że jeśli jakość obrazu stanowi problem, zawsze najlepiej jest przełączyć się z większego na mniejszy obraz. W większości przypadków powiększanie obrazu tworzy artefakty i obniża jego jakość.