W tym samouczku dowiemy się, jak możemy wdrożyć klaster Apache Kafka za pomocą dokera. Dzięki temu możemy użyć dostarczonego obrazu dokera do szybkiego uruchomienia klastra Kafka w prawie każdym środowisku.
Zacznijmy od podstaw i omówmy, czym jest Kafka.
Co to jest Apache Kafka?
Apache Kafka to darmowy, wysoce skalowalny, rozproszony i odporny na błędy system przesyłania wiadomości typu „publikuj-subskrybuj” o otwartym kodzie źródłowym. Został zaprojektowany do obsługi dużej ilości, wysokiej przepustowości i strumienia danych w czasie rzeczywistym, dzięki czemu nadaje się do wielu zastosowań, w tym do agregacji dzienników, analiz w czasie rzeczywistym i architektur sterowanych zdarzeniami.
Kafka opiera się na rozproszonej architekturze, która pozwala na obsługę dużych ilości danych na wielu serwerach. Wykorzystuje model publikowania-subskrybowania, w którym producenci wysyłają wiadomości do tematów, a konsumenci subskrybują je, aby je otrzymywać. Pozwala to na oddzieloną komunikację między producentami a konsumentami, zapewniając wysoką skalowalność i elastyczność.
Co to jest Docker Compose
Docker Compose odnosi się do wtyczki dokera lub narzędzia do definiowania i uruchamiania aplikacji wielokontenerowych. Docker komponuje nas do zdefiniowania konfiguracji kontenera w pliku YAML. Plik konfiguracyjny zawiera specyfikacje kontenera, takie jak usługi, sieci i woluminy wymagane przez aplikację.
Za pomocą polecenia docker-compose możemy tworzyć i uruchamiać wiele kontenerów za pomocą jednego polecenia.
Instalowanie Dockera i Docker Compose
Pierwszym krokiem jest upewnienie się, że zainstalowałeś dokera na komputerze lokalnym. Możesz sprawdzić następujące zasoby, aby dowiedzieć się więcej:
- https://linuxhint.com/install_configure_docker_ubuntu/
- https://linuxhint.com/install-docker-debian/
- https://linuxhint.com/install_docker_debian_10/
- https://linuxhint.com/install-docker-ubuntu-22-04/
- https://linuxhint.com/install-docker-on-pop_os/
- https://linuxhint.com/how-to-install-docker-desktop-windows/
- https://linuxhint.com/install-use-docker-centos-8/
- https://linuxhint.com/install_docker_on_raspbian_os/
W chwili pisania tego samouczka instalacja docker compose wymaga zainstalowania pulpitu Docker na komputerze docelowym. W związku z tym instalowanie docker compose jako samodzielnej jednostki jest przestarzałe.
Po zainstalowaniu Dockera możemy skonfigurować plik YAML. Ten plik zawiera wszystkie szczegóły potrzebne do uruchomienia klastra Kafka za pomocą kontenera dokera.
Konfigurowanie pliku Docker-Compose.YAML
Utwórz plik docker-compose.yaml i edytuj go w swoim ulubionym edytorze tekstu:
$ dotknij docker-compose.yaml$ vim docker-compose.yaml
Następnie dodaj plik konfiguracyjny dokera, jak pokazano poniżej:
wersja : „3”usługi :
opiekun zoo :
obraz : bitnami / opiekun zoo : 3.8
porty :
- „2181:2181”
wolumeny :
- 'zookeeper_data:/bitnami'
środowisko :
- ALLOW_ANONYMOUS_LOGIN = Tak
kafka :
obraz : doker. Ten / bitnami / kafka : 3.3
porty :
- „9092:9092”
wolumeny :
- 'kafka_data:/bitnami'
środowisko :
- KAFKA_CFG_ZOOKEEPER_CONNECT = opiekun zoo : 2181
- ALLOW_PLAINTEXT_LISTENER = Tak
zależy od :
- opiekun zoo
wolumeny :
dane_opiekuna zoo :
kierowca : lokalny
kafka_data :
kierowca : lokalny
Przykładowy plik dokera konfiguruje Zookeeper i klaster Kafka, w którym klaster Kafka jest połączony z usługą Zookeeper w celu koordynacji. Plik konfiguruje również porty i zmienne środowiskowe dla każdej usługi, aby umożliwić komunikację i dostęp do usług.
Skonfigurowaliśmy również nazwane woluminy, aby zachować dane usług, nawet jeśli kontenery zostaną ponownie uruchomione lub odtworzone.
Podzielmy poprzedni plik na proste sekcje:
Zaczynamy od usługi Zookeeper przy użyciu obrazu bitnami/zookeeper:3.8. Ten obraz następnie mapuje port 2181 na komputerze hosta na port 2181 w kontenerze. Ustawiliśmy również zmienną środowiskową ALLOW_ANONYMOUS_LOGIN na „tak”. Na koniec ustawiamy wolumin, na którym usługa przechowuje dane jako wolumin zookeeper_data.
Drugi blok określa szczegóły konfiguracji usługi Kafka. W tym przypadku używamy obrazu docker.io/bitnami/kafka:3.3, który odwzorowuje port hosta 9092 na port kontenera 9092. Podobnie definiujemy również zmienną środowiskową KAFKA_CFG_ZOOKEEPER_CONNECT i ustawiamy jej wartość na adres Zookeepera zmapowany do port 2181. Drugą zmienną środowiskową definiowaną w tej sekcji jest zmienna środowiskowa ALLOW_PLAINTEXT_LISTENER. Ustawienie wartości tej zmiennej środowiskowej na „tak” umożliwia niezabezpieczony ruch do klastra Kafka.
Na koniec podajemy wolumen, na którym usługa Kafka przechowuje swoje dane.
Aby upewnić się, że doker skonfiguruje woluminy dla Zookeepera i Kafki, musimy zdefiniować je tak, jak pokazano w sekcji woluminów. Spowoduje to skonfigurowanie woluminów zookeeper_data i kafka_data. Oba woluminy używają lokalnego sterownika, co oznacza, że dane są przechowywane na komputerze hosta.
Masz to! Prosty plik konfiguracyjny, który pozwala w kilku prostych krokach uruchomić kontener Kafki za pomocą dokera.
Prowadzenie kontenera
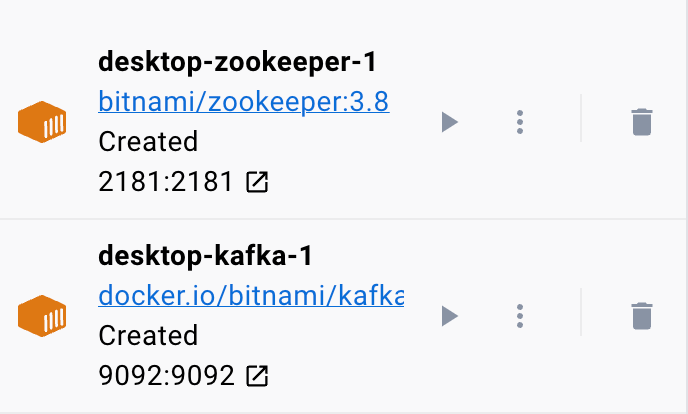
Aby upewnić się, że doker działa, możemy uruchomić kontener z pliku YAML za pomocą następującego polecenia:
$ Sudo docker skomponujPolecenie powinno zlokalizować plik konfiguracyjny YAML i uruchomić kontener z określonymi wartościami:
Wniosek
Wiesz już, jak skonfigurować i uruchomić Apache Kafka z pliku konfiguracyjnego YAML dokera.